南大《软件分析》课程笔记
最后更新时间:
写在前面
准备系统的看一下南大《软件分析》课程,系统的入门一下静态分析,好为之后的自动化漏洞挖掘搭好基础,加油坚持
01-Introduction
静态分析:在编译时刻去检验程序存在的相关问题
可以解决的问题
- 程序的可靠性、安全性
- 编译优化(后端)
- 帮助程序的理解 -> IDE提示
含义:想要在程序运行前分析程序,去了解其中的特征和和是否符合一些性质

不存在方法可以准确的判断程序的性质。换言之,任何递归可枚举语言(现在正常的编程语言)的non-trivial性质都无法判断。

non-trivial性质:有趣的性质,也就是和程序运行时某些行为相关的

完美的静态分析
- Sound 类似过拟合(包含Truth的情况
- Truth 实际真实的特征(例如有10个空指针异常
- Complete 存在的肯定在Truth里头
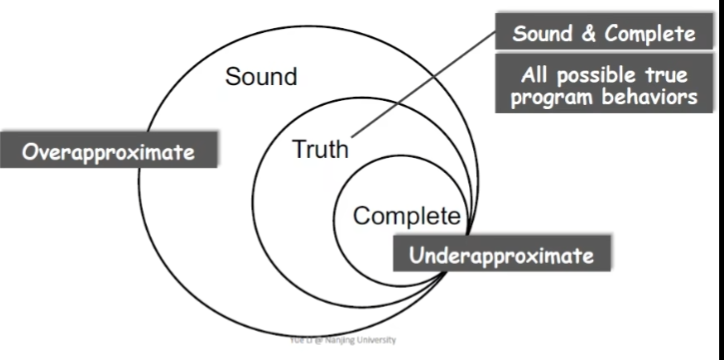
Useful静态分析
- 妥协 sound 会产生漏报
- 妥协 complete 会产生误报(实际绝大多数方法都是这样)
Soundness的必要性
Soundess 对编译优化和程序验证是必不可少的,要考虑所有情况
确保或靠近soundness作为前提,在精度和速度之间做有效的平衡

需要什么样的技术
抽象 + Over-approximation(近似)
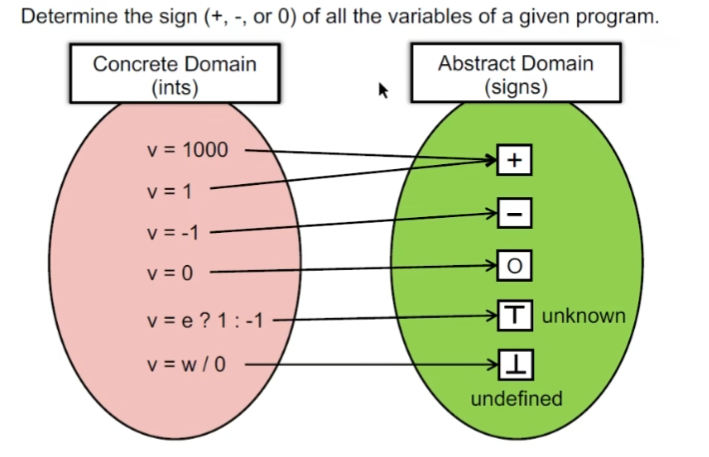
抽象
将每一个具体的域值映射到抽象域(分析关注的符号值)中
近似 Transfer Function
针对每一个程序语句基于抽象值作转换规则
规则的定义:
- 基于分析的目标,以及程序语句分析的语义
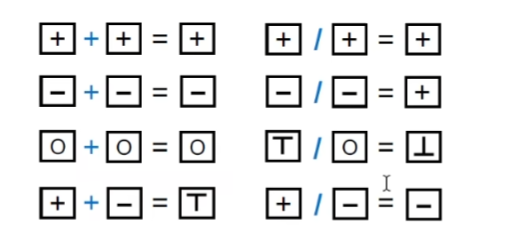
控制流图
汇聚点要针对语义进行合并(因为不可能枚举所有路径)
02-Intermediate Representation
编译器和静态分析器的关系
首先是编译器,先经过词法分析生成记号流(用到正则表达式做规则),进入解析器进行语法分析(上下文无关文法),生成抽象语法树。进而进行语义分析(只能做简单的检查,例如类型检查)。如果还要做代码优化,就需要通过转换器产生IR(通常是三地址码表示),这里也就是静态分析的部分的应用,最终生成机器码交给环境去执行。
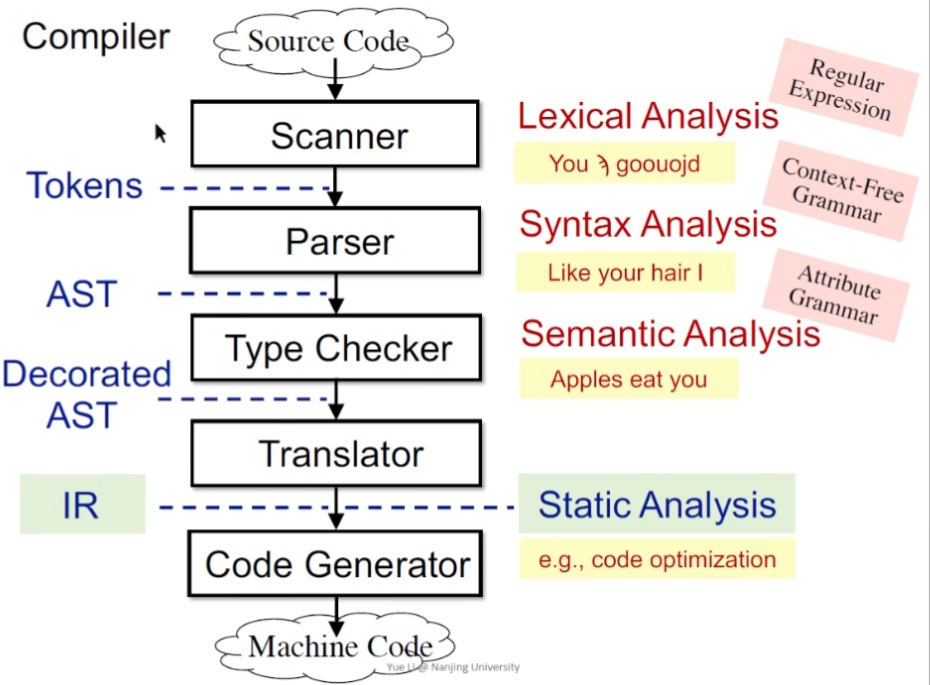
AST vs. IR

IR特点在于与高级程序语言的无关性,不依赖与语言的特性;并且不存在冗余的信息;包含控制流的信息
IR
三地址码 3AC
定义:在指令的右侧最多一个操作符
常见指令的3AC

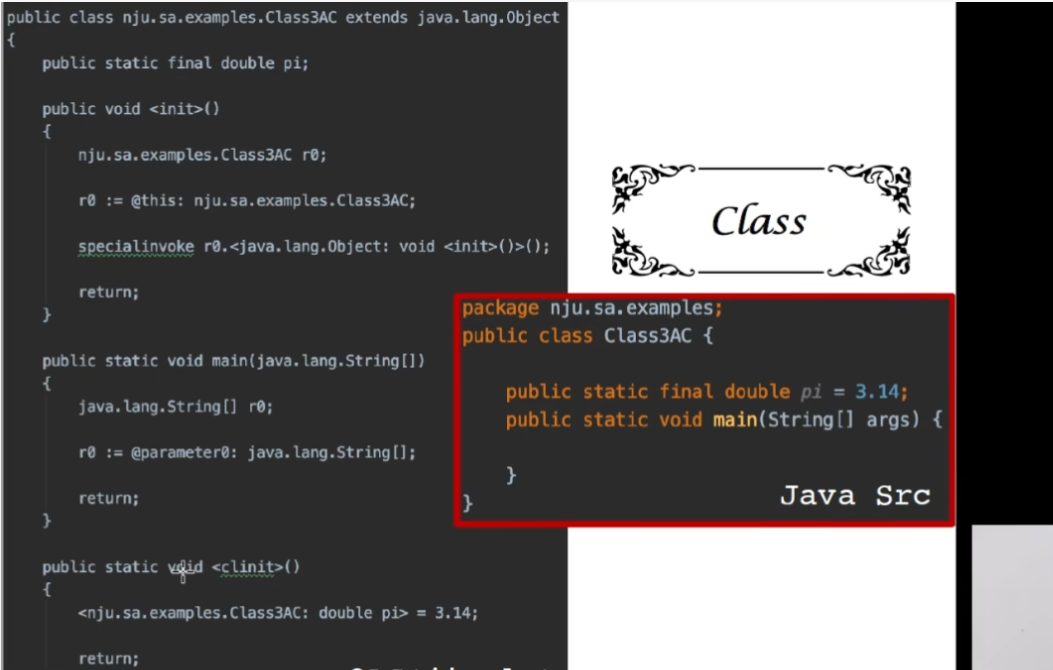
Soot
JVM 四种指令

Method Signature:一般包含方法声明所在类,返回值类型(或void),方法名字,参数类型

clinit: 类的静态的初始化函数。在引用一个变量的时候,会把这个变量加载进来
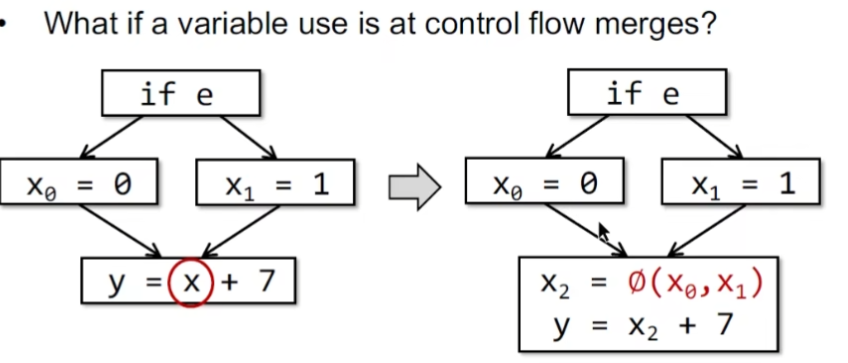
SSA (另一种IR里面的转换格式)
给每一个定义新的name,每个变量都有一个精确的定义。专门定义一个函数来作为变量的选择,并作为新的变量名
控制流分析 CFG
给定输入是三字节码
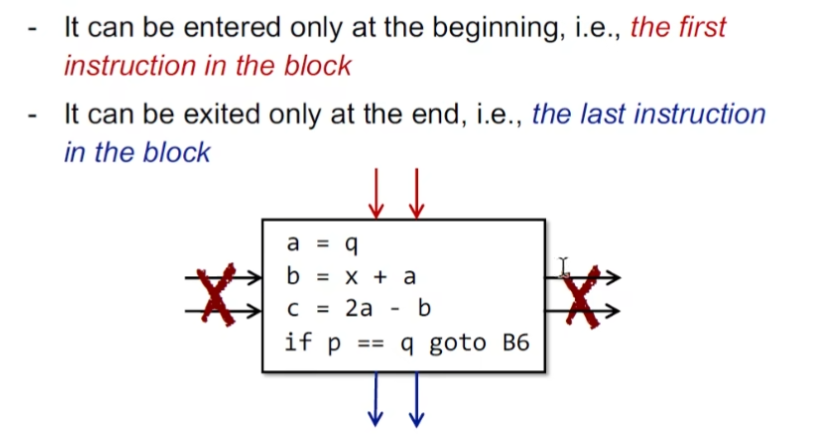
结点:Basic Blocks
特征定义:满足下列性质的最大的连续三地址码指令
如何建立呢?
一个jump的目标的指令应该作为一个BB的入口(反证法就会有两个入口)
一条指令紧跟着jump指令后头,它应该也作为BB的入口(反证法就会有两个出口)

怎样在BB的基础上添加边?
对于有条件跳转的情况,下一条紧跟的BB也要练;无条件的不需要
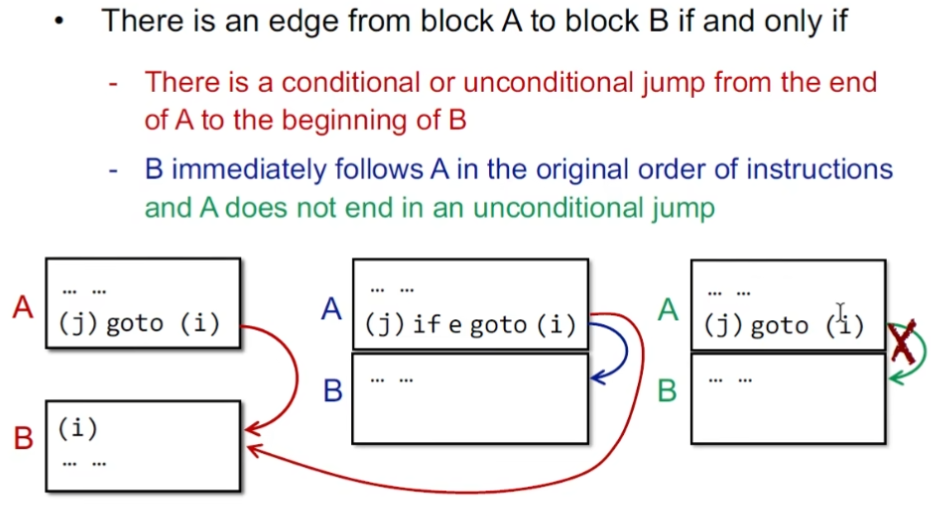
直接将跳转的指令标签替换成所在的BB即可,因为两者的含量信息是一致的
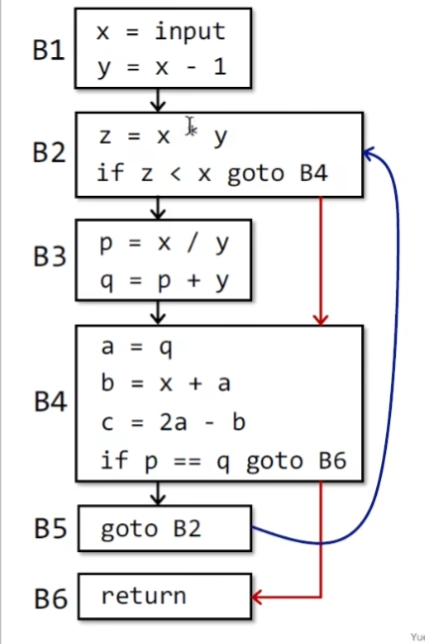
进而产生前趋和后继的概念,之后还要加两个特殊结点(方便程序设计时初始化),可以有多个入边和出边

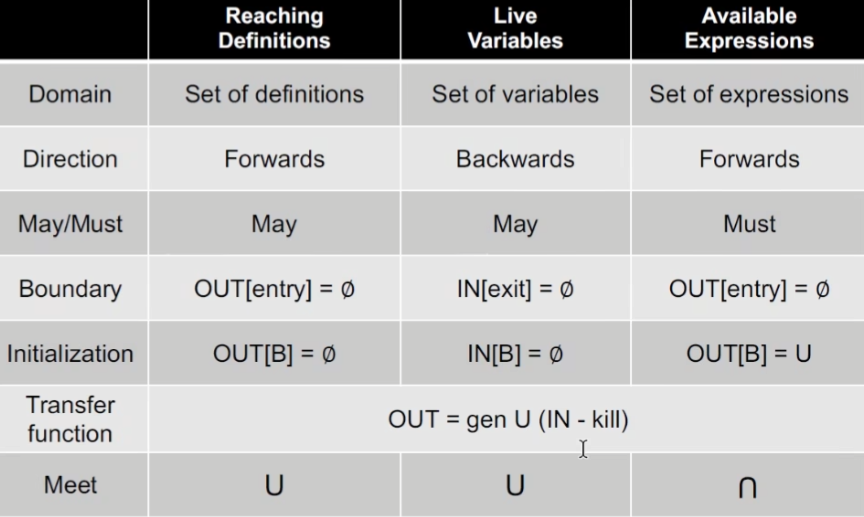
03-Data Flow Analysis I
Data Flow Analysis
Data是如何在CFG上进行流动的?
对于绝大多数的静态分析,我们都尽可能以sound为标准

但是对某些特定分析,需要达到must analysis

因此统一称作不同标准对应的safe approximation
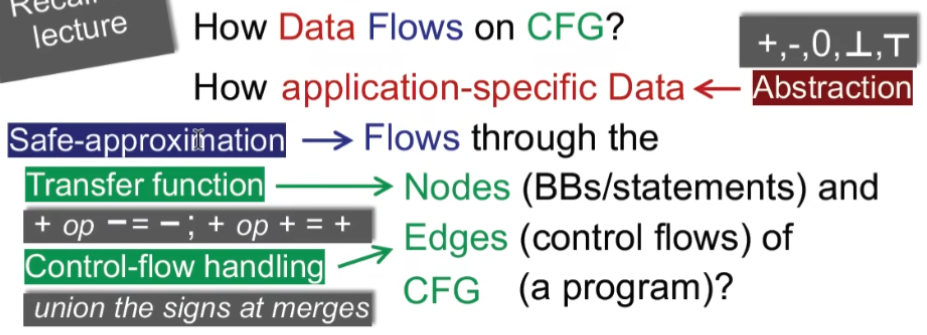
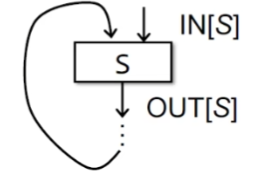
Input and Outout States
^代表meet汇聚符号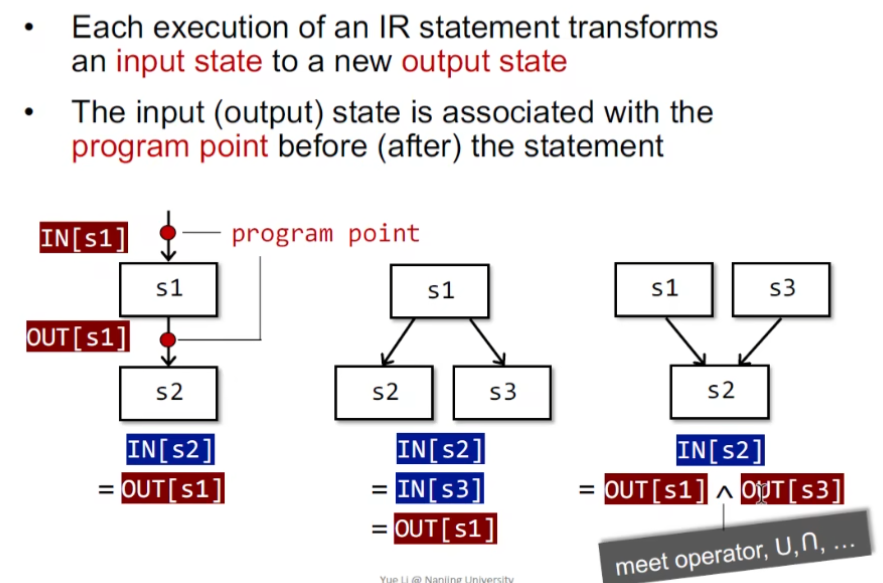
我们给每个点都关联一个值。该值时程序状态的抽象集合(我们关注的)
抽象指的是定义能否到达该点的抽象表示(位向量)

值域domain
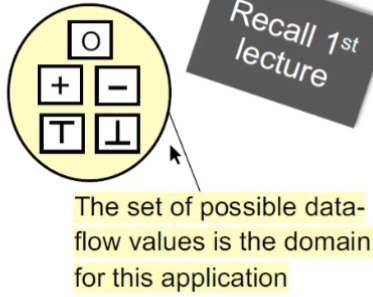
数据流分析的定义
不停的运用transfer functions 和 控制流在IN 和OUT上,直至找到一个符合safe-approximations标准的解决方案

Transfer functions ‘s constraints
前向分析
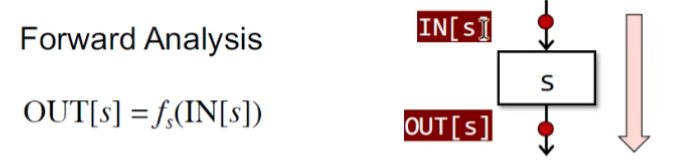
反向分析

control flow’s constraints
BB块内,每一个statements 顺序执行
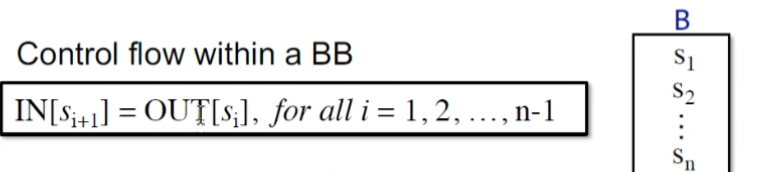
BB之间
首先B的transfer function 由每一个内部的statements迭代调用各自的transfer function构成规则;

反向操作
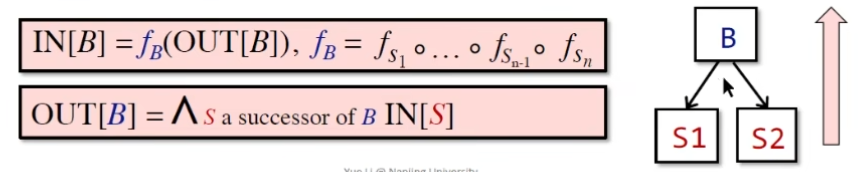
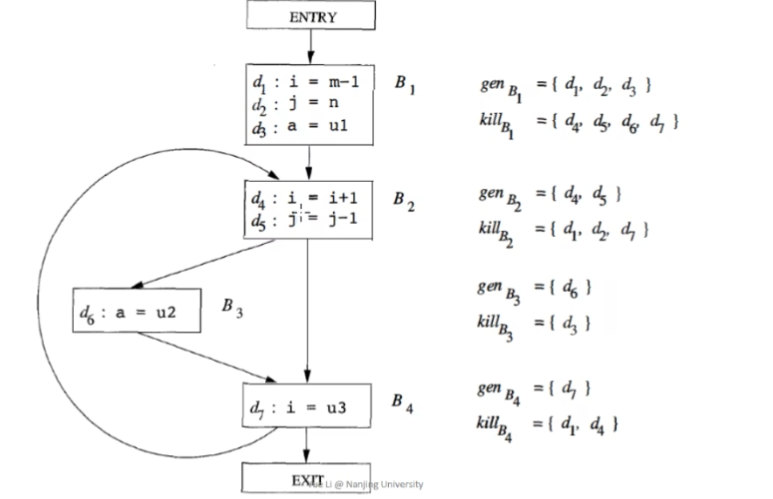
Reaching Definitions Analysis
处理的程序不涉及方法调用以及别名
简单来说就是定义v的地方p,到q可以有条路径,但不能有v的新定义

这里应该是以may-analysis为标准,实际运行中可能会有多个路径但只有一条可达。所以我们需要考虑到全部的可达性。
如何做抽象和约束规则
抽象
我们把定义值抽象成比特位的形式,从左数第i位对应的就是Di的定义,0代表该点定义不可达

约束规则
针对每一个语句块而言,生成新的定义,同时kill掉其他定义v的地方;但是对于其他输入的定义x 和 y 不受影响

符号形式表示
BB
转移函数:生成语句块中生成的定义,同时kill掉之后二次定义(已生成定义)的地方
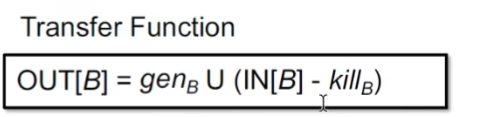
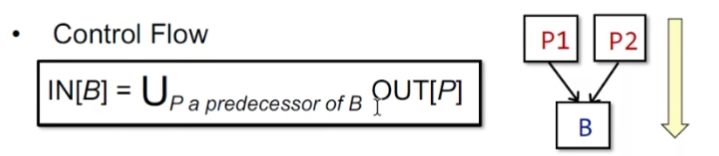
控制流: may-analysis -> over approximation
算法
按照语义来理解,初始置OUT[entry]为空,也就是说当前并没有定义流到entry的OUT处;
这个算法针对所有数据流分析模型都是一样的,所以初始化值entry不一定为空;
BB初始化为空是针对may analysis,对于must analysis一般是top;
循环体中就是针对BB不停的做规则定义的约束;
循环如何结束?
如果IN不变,则输出也不会变化 kill是个常量(statememts不会变)

example
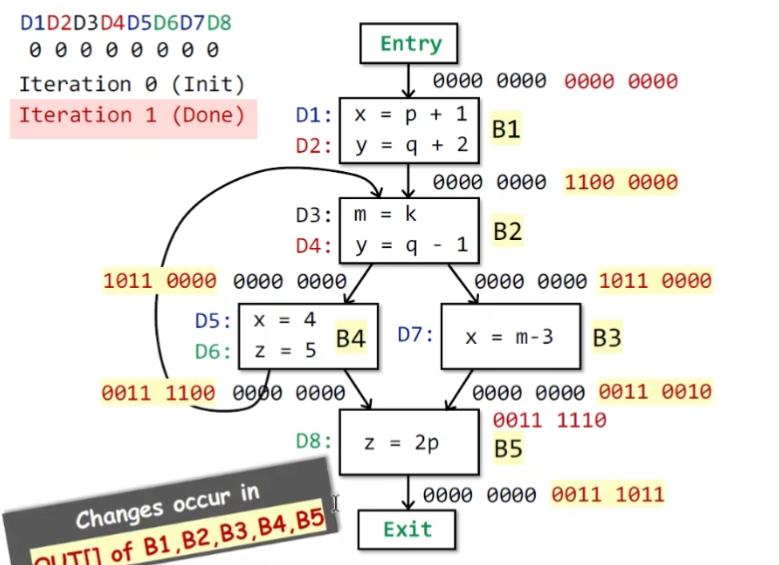
迭代为什么会停?有没有可能不会停?
关键点:transfer function
1不会变成0,只要定义进入到OUT中,就不会在变回0(该kill的在transfer function时已经被kill掉);但是OUT增长会有限,也就是存在一次迭代OUT不会再变化;而OUT不会变的话,在transfer function中,根据
可知,IN也不会变。从而再下一次迭代中同理OUT也不会再变,也就意味着程序状态达到了一个不动点,(和程序的单调性有关)作为程序的分析结果

04-Data Flow Analysis II
Live Variable Analysis

从v到被使用的地方存在这么一条路径,同时v在这中途没有被重定义,我们就说v在program p点是live的

Data怎么抽象?
Data是什么?程序中所有的变量
同样可以用比特位来表示
如何设计transfer function? backward的设计方式比较方便
已知OUT[B]求IN[B]?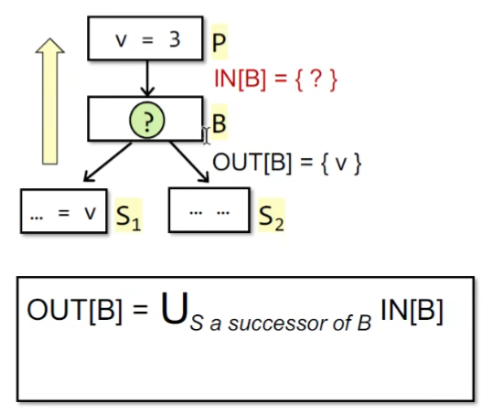
通过一个应用场景来说明,可以看到如何判断是否是live的其实就是看OUT[B]中有无使用v,或者在被redefined之前use了v

def指的是v被redefined的情况,也就是减去redefined的情况,但也有可能是live的。如情况4和6,在redefined之前被use了,就要把他们加回来
算法
一般情况下,may analysis的初始化为空;must analysis的初始化为all.循环中不停迭代,直至所有的IN都不再变化

exp
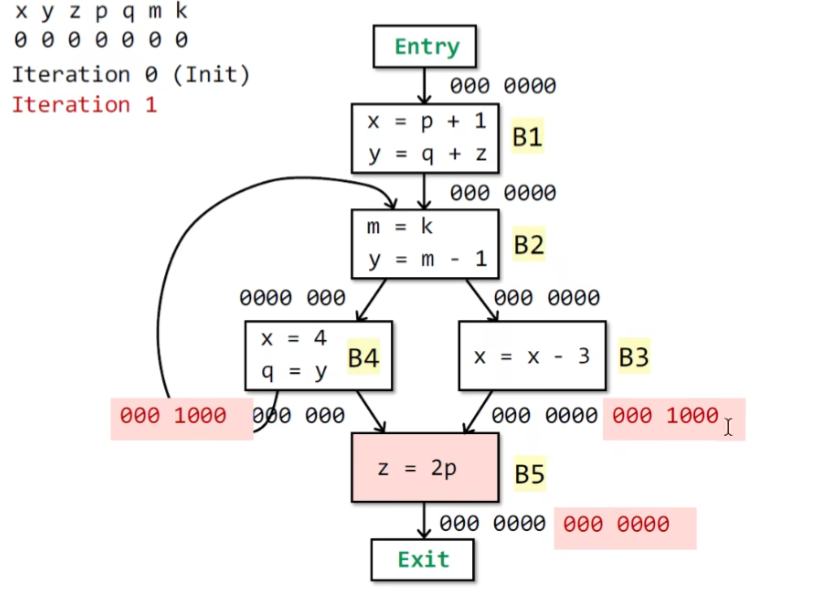
同理,kill和g都是固定的,因此OUT不变,所以IN也不会变
Available Expression Analysis (must analysis)
从entry开始,到p的所有path都要经过执行x op y的值,各自path的表达式x op y之后,没有再出现重定义

数据抽象 针对的是expression
利用比特位来表示,0代表不available,1相反
transfer function
针对 must analysis,gen部分加入新生成的expression,同时kill部分去掉被重定义的变量对应的表达式
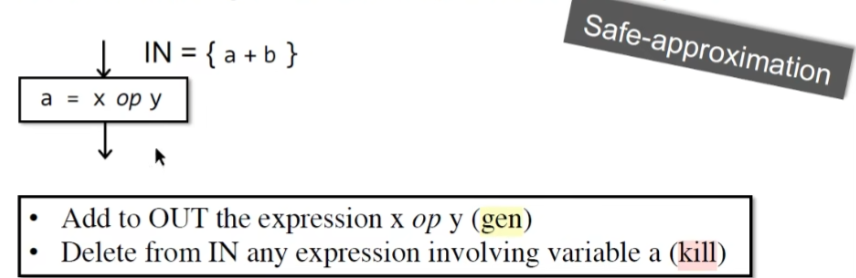
因为所有的path都得有表达式 x op y,不能仅有一条有

可能会有漏报,但是也可以认为是safe approximation的

算法
这里有个细节就是初始化时OUT[B]全为1。在循环当中迭代运行,直至没有OUT变化

分析对比
HomeWork1 活跃变量分析和迭代求解器 https://tai-e.pascal-lab.net/pa1.html#_2-%E5%AE%9E%E7%8E%B0%E6%B4%BB%E8%B7%83%E5%8F%98%E9%87%8F%E5%88%86%E6%9E%90
前置知识
用到了Java的一些特性
Optional特性:isPresent() 和 get()的使用

泛型特性
pascal.taie.analysis.dataflow.analysis.DataflowAnalysis五个关键API:分析方向、边界条件、初始条件、meet操作、transfer函数
pascal.taie.ir.exp.Exp这是 Tai-e 的 IR 中的一个关键接口,用于表示程序中的所有表达式。其中有很多继承类,本次作业只需关注Var类
pascal.taie.ir.stmt.Stmt为了实现活跃变量分析,你需要获得某条语句中定义或使用的所有表达式中的变量
pascal.taie.analysis.dataflow.fact.SetFact<Var>它提供了各种集合操作,如添加、删除元素,取交集、并集等
pascal.taie.analysis.dataflow.analysis.LiveVariableAnalysis实现
DataflowAnalysis的接口来定义具体的活跃变量分析函数实现
public SetFact<Var> newBoundaryFact(CFG<Stmt> cfg)new fact in boundary conditions, i.e., the fact for
entry (exit) node in forward (backward) analysis在这里想了好久,后来再看注释原来就是返回一个fact用于exit结点的。所有的实际操作应该是在solver中实现
public SetFact<Var> newInitialFact()new initial fact for non-boundary nodes
同理也是返回fact
void meetInto(Fact fact, Fact target)Meets a fact into another (target) fact. This function will be used to handle control-flow confluences.
这里对应算法当中并集处理IN到OUT当中,在实现上,实验文档说明了避免通过生成一个新的fact来实现合并的功能,所以是利用对每一个IN的fact集迭代合并到OUT当中,来优化程序
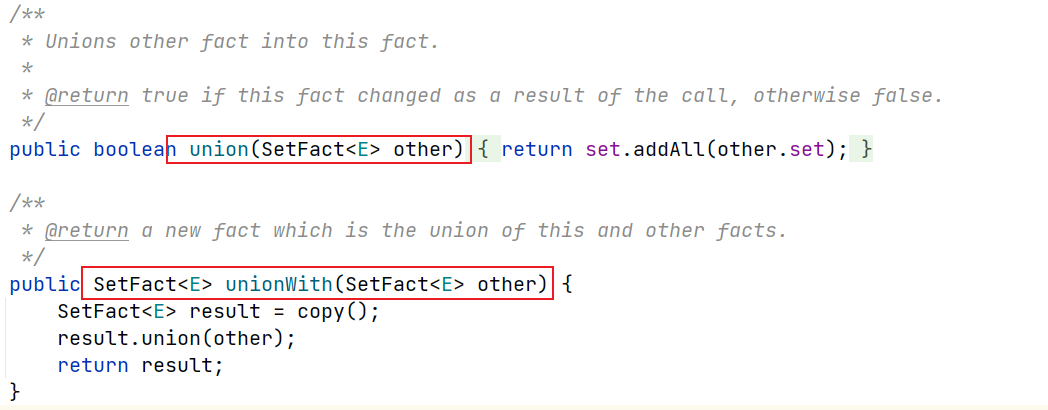
所以我们这里也应该注意一下union和unionWith方法的区别
ublic boolean transferNode(Stmt stmt, SetFact<Var> in, SetFact<Var> out)The function transfers data-flow from in (out) fact to out (in) fact. for forward (backward) analysis.
@return true if the transfer changed the out (in) fact, otherwise false.实验中为了简化,将BB视为了一条条statements
依照算法
实现上的思路就是,复制OUT集合中的fact到新集合,然后针对其中的定义变量作生成和删改操作,最后与输入参数中的IN集合作比对看是否出现变化
针对fact集的复制,可以利用进行深拷贝

stmt.getUses()返回的是一个List<RValue>。在RValue下,有立即数也有变量。怎么判断一个RValue变量是不是指向了一个Var对象呢?Java 里的解决方法就是instanceof关键字。依然是那个问题,
SetFact<Var>储存的是Var,如何把RValue use内的对象放进去呢?方法就是强制类型转换(Var) use;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65public class LiveVariableAnalysis extends
AbstractDataflowAnalysis<Stmt, SetFact<Var>> {
public static final String ID = "livevar";
public LiveVariableAnalysis(AnalysisConfig config) {
super(config);
}
@Override
public boolean isForward() {
return false;
}
@Override
public SetFact<Var> newBoundaryFact(CFG<Stmt> cfg) {
// 边界结点对应exit 这里意思就是返回一个 fact
return new SetFact<Var>();
}
@Override
public SetFact<Var> newInitialFact() {
// 返回非边界结点的fact
return new SetFact<Var>();
}
@Override
public void meetInto(SetFact<Var> fact, SetFact<Var> target) {
// 这里做并集
target.union(fact);
}
@Override
public boolean transferNode(Stmt stmt, SetFact<Var> in, SetFact<Var> out) {
// 先作复制OUT集中的内容
SetFact<Var> newInFact = new SetFact<Var>();
newInFact.set(out);
// 运用算法修改 先删除
Optional<LValue> leftValue = stmt.getDef();
if(leftValue.isPresent()) {
LValue lValue = leftValue.get();
if (lValue instanceof Var) {
newInFact.remove((Var)lValue);
}
}
// 再添加新定义的变量
List<RValue> rightValues = stmt.getUses();
for (RValue rightValue : rightValues) {
if(rightValue instanceof Var) {
newInFact.add((Var)rightValue);
}
}
// 最后判断修改的In和上一轮的IN是否相同
if(!newInFact.equals(in)) {
// 记得将修改内容赋给 输入的 in
in.set(newInFact);
return true;
}
return false;
}
}
实现迭代求解器
前置知识
pascal.taie.analysis.dataflow.fact.DataflowResult该类对象用于维护数据流分析的 CFG 中的 fact。你可以通过它的 API 获取、设置 CFG 节点的
IN facts和OUT facts。pascal.taie.analysis.graph.cfg.CFG表示程序中方法的控制流图,可迭代
实现
方法1:
protected void initializeBackward(CFG<Node> cfg, DataflowResult<Node, Fact> result)这里对应算法核心的迭代之前的初始化操作
细节
Solver是一个抽象的分析框架,因此Node和Fact都是未确定的,不能做new Node()这样的操作。这里实际上要利用前面分析器的接口方法,还是多看注释源码为了实现上面所说的 meet 策略,你需要在初始化阶段给每条语句的
OUT[S]赋上和IN[S]一样的初值1
2
3
4
5
6
7
8
9
10
11
12
13
14protected void initializeBackward(CFG<Node> cfg, DataflowResult<Node, Fact> result) {
// 初始化 OUT[exit] = 空集
Node exit = cfg.getExit();
result.setOutFact(exit, analysis.newBoundaryFact(cfg));
result.setInFact(exit, analysis.newBoundaryFact(cfg));
for (Node node : cfg) {
// 不对exit重复初始化
if (!cfg.isExit(node)) {
result.setInFact(node, analysis.newInitialFact());
result.setOutFact(node, analysis.newInitialFact());
}
}
}方法2:
IterativeSolver.doSolveBackward(CFG,DataflowResult)
05-Data Flow Analysis - Foundations I
另一个角度理解迭代算法
每次迭代更新结点中的OUT值

每次迭代可以视为一次动作F,也就是包含了transfer function和CFG,对应$V^k$到$V^k$的映射

停止条件:最后一次迭代的k元组值与上一个最后迭代值相等

图示表示:
初始化元组各项为bottom,第i+1次迭代和第i次迭代结果相同
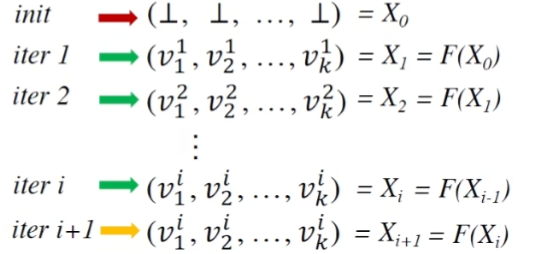
关注最后两个式子
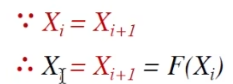
由此引出X不动点的定义
那么算法是否能保证得到一个不动点嘛?或者说是否一定能为数据流分析给出一个solution
相关数学概念
Partial Order
偏序集满足的性质
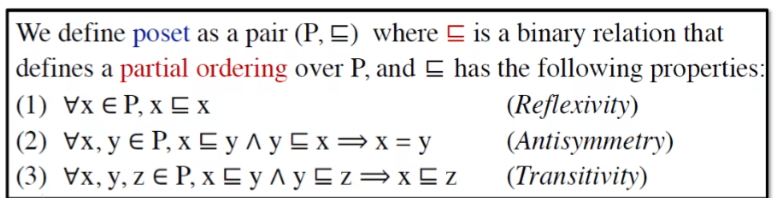
偏序的意义:集合中两个元素可以不满足偏序关系

Upper and Lower Bounds 上下界
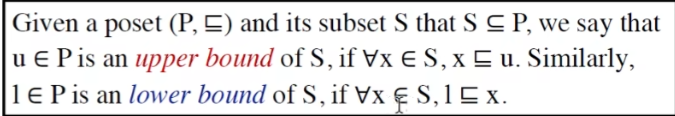
最小上界和最大下界的概念

最小上界和最大下界的另一种表示,当S值包含两个元素时

相关性质:

证明:利用了偏序的反对称性

Lattice

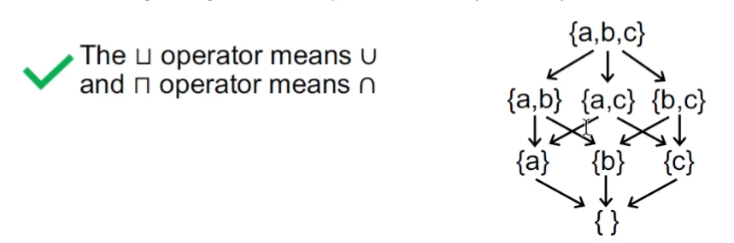
定义Semilattice
最小上界和最大下界只存在其一
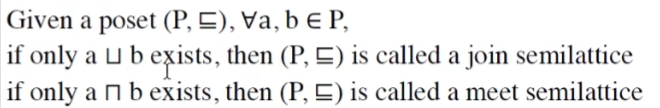
定义Complete Lattice,不再是针对两个元素的子集,而是任意的子集

由此引出bottom和top的含义。

只有你的lattice是有穷的,则它一定是complete lattice;反之不一定成立
Product Lattice

最小上界上最下下界
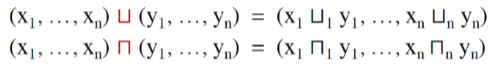
两个性质

用Lattice来表达数据流分析框架

exp:s1 和 s3的join操作,实际上右面的Lattice从下往上升(may analysis)

Lattice函数单调性(回答data flow analysis是否能到不动点)
Lattice上定义函数单调性及不动点定理
针对不动点定理,前提是complete lattice,所以需要加一个条件即L是有限的

这里给出了最小不动点和最大不动点的方法,证明如下(最小不动点)
充分利用bottom的定义和单调性定义、有限性
这里也就是说明了上升链有限,最终能达到不动点

接下来证明得到的一定是最小不动点
利用数学归纳法

得到的最小不动点一定是唯一的
最大不动点的证明同理有Lattice上的函数不动点定理引申到迭代算法上是否也满足不动点的性质?换句话说,两者怎么关联上?
06 - Data Flow Analysis - Foundation
迭代算法与固定点定理相结合
针对第二个已知条件:L有限
在一个迭代算法中每一个OUT的值域实际上就是对应一个Lattice,整个就构成一个product lattice

针对第一个已知条件:函数f满足单调性

大写的F包含两部分,每个结点施加transfer function;在控制流图中针对汇聚点采用join或meet方法合并。那么F是否是单调的?
首先对于第一个transfer function我们已经在迭代算法中知道了当kill固定时和gen固定时,OUT/IN不变,那么IN/OUT也不会变,也就是说它是只增不减的,因此是单调的
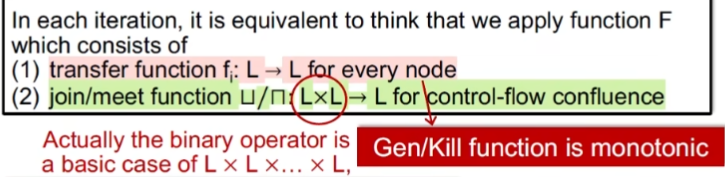
对于join/meet,我们以join为例,证明如下
利用最小上界的定义
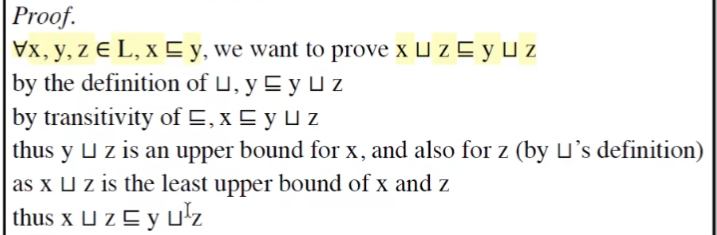
迭代算法什么时候能达到不动点,复杂度问题
lattice的高度

什么时候能达到不动点,也就是求最大迭代次数
考虑最坏情况,每一次迭代,只有一个结点的一个值变化

如果lattice的高度为h,且CFG中的结点数为k,则最大迭代次数为
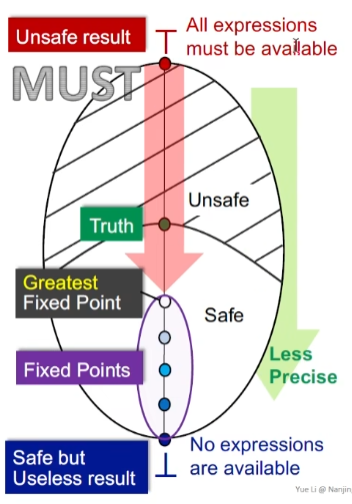
May and Must Analysis
对于May analysis来讲,bottom就意味着unsafe result,(没有定义可以到达,也就是所有定义都已经初始化过);而top意味着所有的定义都可达,也就是说肯定能保证正确但是无用。
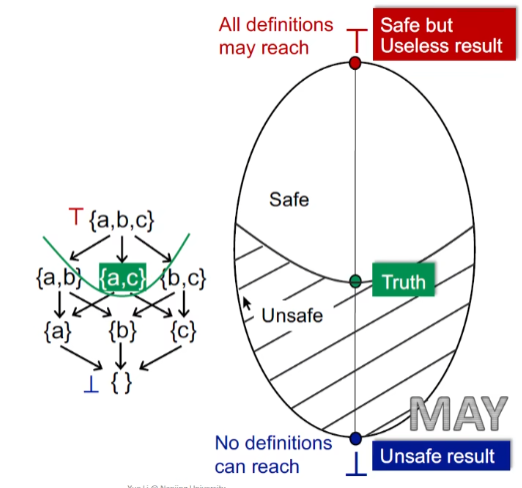
从bottom到top,自下而上需要一个truth点作为边界,如何辨别是否safe,或者说到达不动点取决于算法的safe approximation的策略
自下而上,不动点越往上精度越差,因此达到最小不动点是最好的
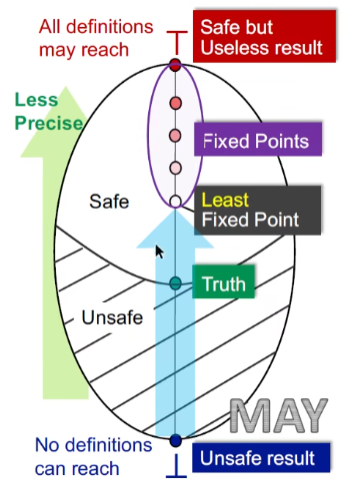
而对于must analysis,有一个误报可能都会导致程序分析的错误
所以其是从top往下走,直至最大不动点将会达到精度最高的safe点
Path Function 精度问题

MOP 枚举所有path,应用Path Function
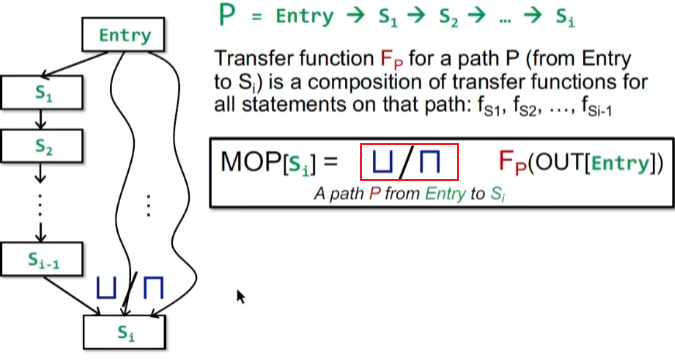
当然这只是概念上的一种形式,实际上枚举起来非常困难
那么迭代算法结果和MOP的关系?
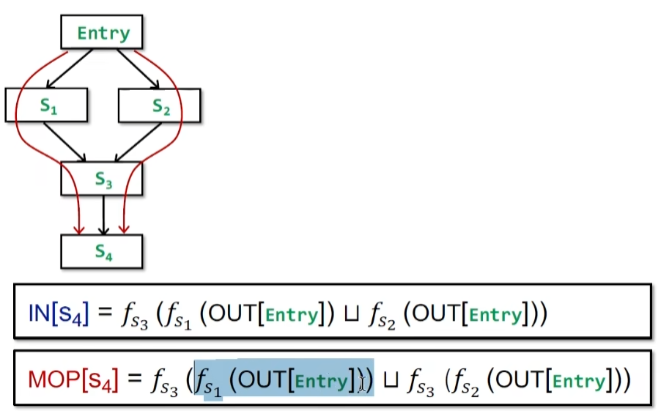
实际上就是join的位置不太一样
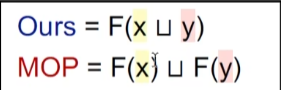
证明:

结果在lattice上满足偏序关系,MOP是更准的。
特殊情况下,如果F满足分配律
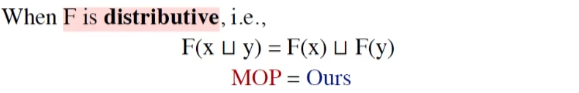
Constant Propagation (函数不满足分配律)
must analysis 满足前向传播

Lattice下
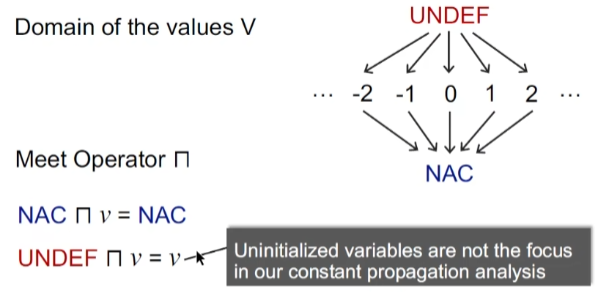
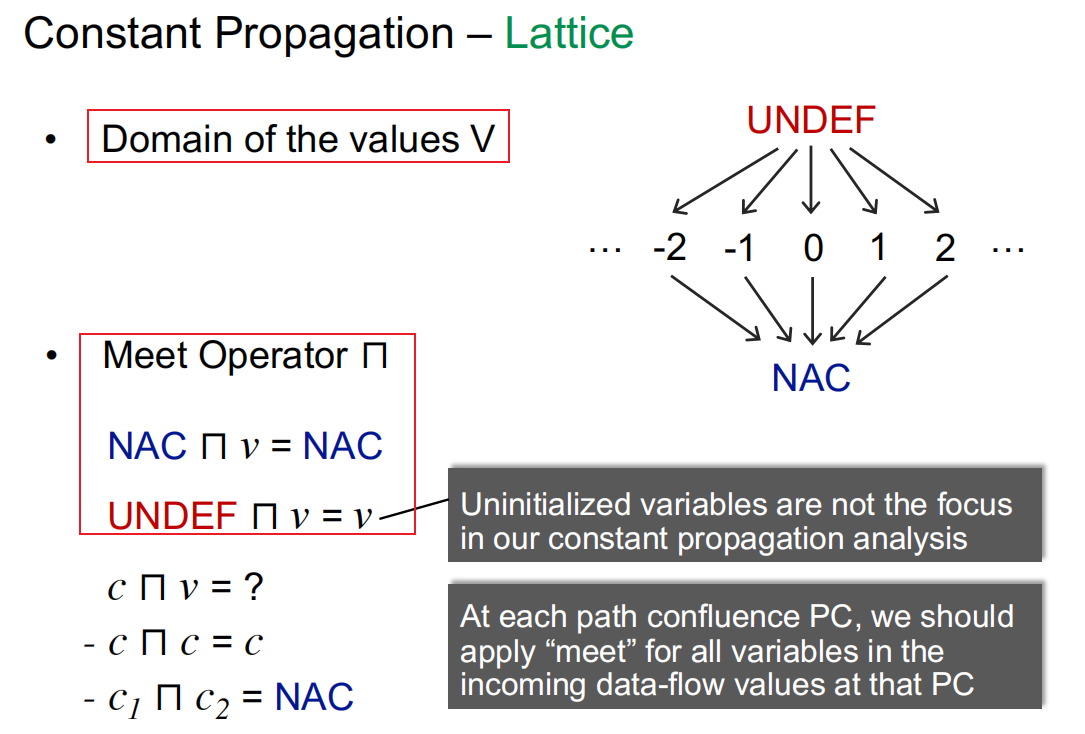
Domain of the values V
特殊点在初始化时v的值是undefined(虽然初始化时从top开始)
Meet Operator
特别地,这里不关注未初始化变量的问题,也就是只要有path到达,就是已初始化变量
transfer function

在val(x)最后一种情况,如果一个常量+undefined值,则transfer function将不满足单调性
它的非分配律特性
当两边均是NAC时,join后就是NAC
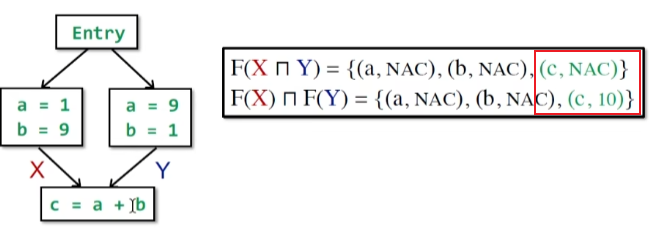
Worklist Algorithm(迭代算法的优化)
核心:只需遍历有变化的地方施加transfer function,而非整体再迭代一遍
只计算IN变的,OUT才有可能会变;因此当OUT变时只需关注它的所有后继BB即可

实验2 常量传播和 Worklist 求解器
需要了解的类
pascal.taie.ir.IR
IR 的核心数据结构。它的每个实例储存了一个 Java 方法的各种信息,例如变量、参数、语句等等
pascal.taie.ir.exp.Exp类型接口
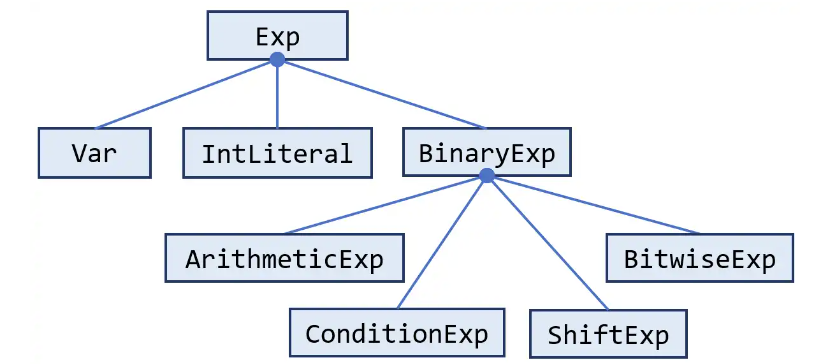
Var第一个实验我们已经用过
pascal.taie.ir.exp.IntLiteral 整数字面量
pascal.taie.ir.exp.BinaryExp 二元表达式
这个类代表程序中的二元表达式。这个类的各个子类对应了表 1 中的不同种类的二元表达式,并且每个子类中都有一个内部枚举类型用于表示该类支持的运算符。

作者提到了二元表达式的操作数均设计成立变量的形式,也就是说
pascal.taie.ir.stmt.DefinitionStmt
这是 Stmt 的一个子类。它表示了程序中所有的赋值语句
pascal.taie.analysis.dataflow.analysis.DataflowAnalysis
这是具体数据流分析算法需要实现的接口(实现类为pascal.taie.analysis.dataflow.analysis.constprop.ConstantPropagation),之后会被求解器调用。本次实验关注前5个API
pascal.taie.analysis.dataflow.analysis.constprop.Value
这个类表示了常量分析中格上的抽象值
用下列的静态方法获取格上抽象值(即该类的实例)
Value getNAC(): 返回NACValue getUndef(): 返回UNDEFValue makeConstant(int): 返回给定整数在格上对应的抽象值
pascal.taie.analysis.dataflow.analysis.constprop.CPFact
这个类表示常量传播中的 data facts,即一个从变量(Var)到格上抽象值(Value)的映射。该类提供了各种 map 相关的操作,例如键值对的查询、更新等等
实现常量传播
API I : newBoundaryFact()
在实现 newBoundaryFact() 的时候,你要小心地处理每个会被分析的方法的参数。具体来说,你要将它们的值初始化为 NAC,为了满足must analysis的top 符合safe approximation.同时这里还涉及到需要考虑方法参数类型是否在本实验的范围内,对于不在范围的直接忽略即可。
这里在实现时就是先从图里取出所有的方法,然后获取IR语义信息中的参数进行初始化
1 | |
API II : newInitialFact()
这里没啥好说的,就是正常返回一个空fact
API III : meetInto()
原理参照:
这里利用到了一个辅助函数Value meetValue(Value,Value)对应的是格上的meet操作,我们先实现格上的
这里需要注意一点的就是要返回常数的话需要先调用一个Value的makeConstant方法
1 | |
然后就是实现meetInto()
这里也就是需要遍历fact map中的变量将其依次合并到target map上(meet时利用格上的合并方法)
1 | |
API IV : transferNode()
首先先实现Value evaluate(Exp,CPFact)
这个方法会计算表达式(Exp)的值(Value)。当然,此处的值是格上的抽象值。
原理参考

也就是我们需要按照不同的表达式类型来作不同处理,对于非赋值型语句,采用直接复制的操作
1 | |
接下来实现transferNode(),利用
1 | |
实现 Worklist 求解器
需要知道的类
pascal.taie.analysis.dataflow.solver.WorkListSolver原理按照如图分两部分实现

对于方法
Solver.initializeForward(CFG,DataflowResult)实现基本和实验1一致,就是初始化为空。只是注意IN和OUT都要做相同的初始化处理对于方法
WorkListSolver.doSolveForward(CFG,DataflowResult),这里注意区别在于当OUT出现变化时,并不是将所有的结点再遍历一次,而是将改变的结点及其后继结点加到worklist当中
07- Interprocedural Analysis
以往在过程内调用静态分析方法遇到方法调用时往往采用最保守的方式,也就是返回值一定是个NAC(以常数传播为例)
如何构建程序的调用图
CALL Graph 程序中调用关系的集合
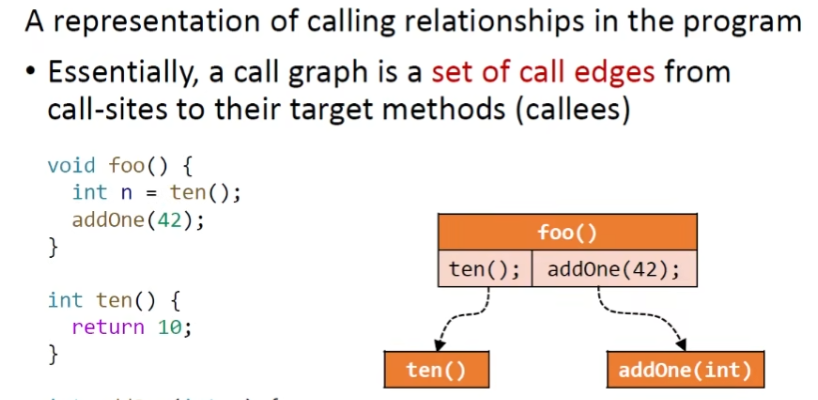
当前构建的算法,越往下精度越高,同时速度也会相对下降
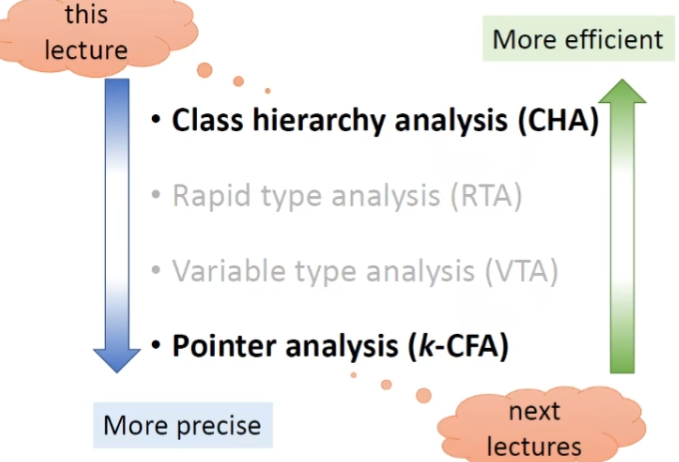
JAVA语言中方法调用的类型,其中virtual call主要是为了实现OO语言的多态特性,因此目标方法只有在运行时才能够确定,所以调用图的关键就是如何处理这个调用类型
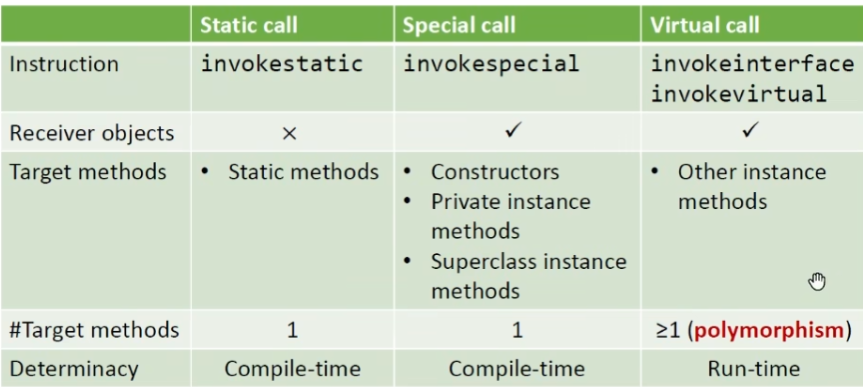
Method Dispatch of Virtual Calls

签名的定义如下(soot 采用格式),用于唯一确定方法

Dispatch的函数定义,模拟动态运行时具体调用目标方法的过程
涉及两个参数:调用者类型和方法的签名

Class Hierarchy Analysis
核心思想:根据声明类型去求解目标方法
去查找A类及其整个继承结构的目标方法

算法:

对于virtual call部分,c和c的所有子类都会去调用dispatch方法,并将结果加入到目标方法
特征

如何用CHA构造整个调用图

具体算法:

exp:
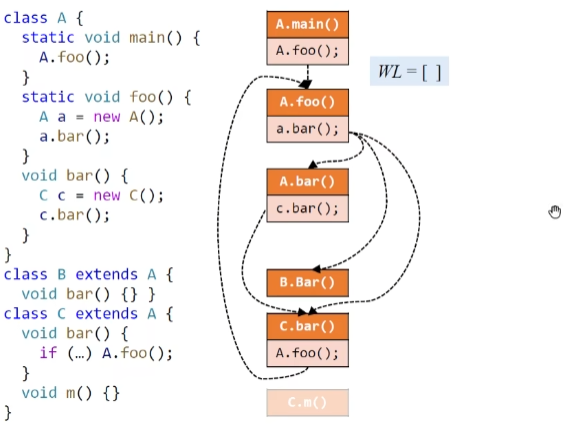
Interprocedural Control-Flow Graph
表示整个程序的结构,作过程间分析

return site指的是紧跟着调用方法语句的下一个语句
Interprocedural Data-Flow Analysis 过程间数据流分析
在transfer function之外增加edge transfer
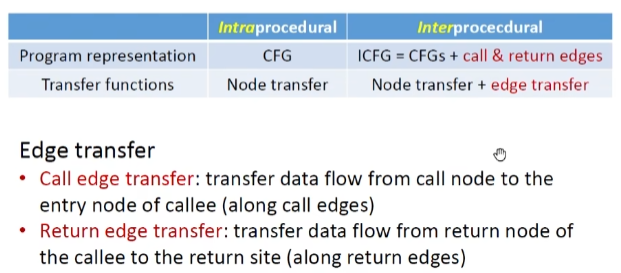
过程间常量传播(这里仅考虑值传递)
这里有个细节就是方法调用和返回之间仍存在一条边,便于我们去传递本地的数据流(没有的话则需要在外部调用方法时仍然得保留形参的数据流信息,影响性能)
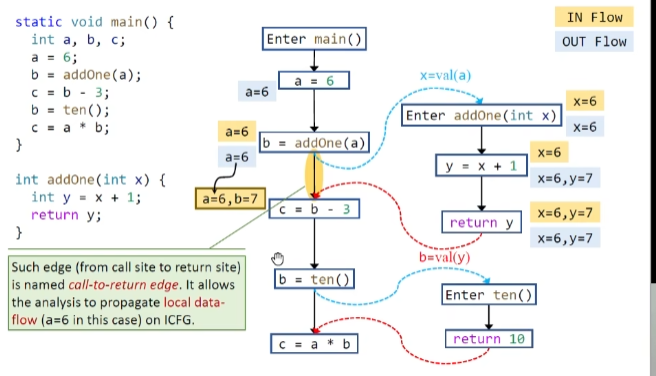
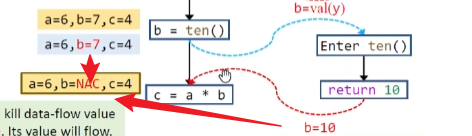
对于每一个call node,都需要kill掉左边的变量,因为其值会顺着return边重新流回来
如果不kill掉则会影响精度问题,这里就是将会导致b结果变成NAC
实验4 类层次结构分析与过程间常量传播
需要了解的类
pascal.taie.analysis.graph.callgraph.DefaultCallGraph
该类代表了程序的调用图。它提供了多样的 API(继承自类
AbstractCallGraph)来获取到调用图的信息。另外,它还提供了一些修改调用图的 API,你可以借此来建立调用图。1
2
3
4Stream<Invoke> callSitesIn(JMethod)`:返回给定方法 `JMethod` 中的所有 `call sites
boolean contains(JMethod): 返回当前调用图是否含有给定的方法,即给定方法 JMethod 在当前调用图中是否可达。
boolean addReachableMethod(JMethod): 向当前调用图中添加方法 JMethod 并将方法标记成可达的
boolean addEdge(Edge<Invoke,JMethod>): 向当前调用图中添加一条调用边pascal.taie.analysis.graph.callgraph.CallKind
该枚举类型表示调用图中边的种类,包括
INTERFACE、VIRTUAL、SPECIAL和STATICpascal.taie.analysis.graph.callgraph.Edge
该类表示调用图中的边。每一条边从调用点(call site,Tai-e 中为
Invoke类型)出发,指向被调用方法(callee method,类型为JMethod)。在创建一条边的时候,你需要向构造方法提供调用类型、调用点和被调用方法的信息pascal.taie.ir.stmt.Invoke(subclass ofStmt)该类表示程序中的方法调用(举个例子:
x = o.m(a1,a2,…))以及调用图中的调用点1
你需要使用 getMethodRef() 来获取目标方法的签名信息pascal.taie.ir.proginfo.MethodRef
Tai-e 中的目标方法引用,如调用点的目标方法。它包含了调用点所调用的目标方法的签名信息。
1
2JClass getDeclaringClass():返回该方法签名的声明类,即声明该方法的类
Subsignature getSubsignature():返回被调用方法的子签名(subsignature)pascal.taie.language.classes.JMethod
该类表示 Tai-e 中的 Java 方法。每个
JMethod的实例关联着一个方法并包含该方法的各种信息1
boolean isAbstract(): 如果该 JMethod 是一个没有方法体的抽象方法,则返回 true,否则返回 false;pascal.taie.language.classes.JClass
该类表示 Tai-e 中的 Java 类。每个
JClass的实例关联着一个类并包含该类的各种信息1
2
3JClass getSuperClass(): 返回该类的父类。如果这个类在类层次结构的顶端(没有父类),比如 java.lang.Object,则返回 null。
JMethod getDeclaredMethod(Subsignature): 根据子签名返回该类中声明的对应方法。如果该类中没有该子签名对应的方法,则返回 null。
boolean isInterface(): 返回该类是否是一个接口pascal.taie.language.classes.Subsignature
该类表示 Tai-e 中的子签名。一个方法的子签名只包含它的方法名和方法签名的描述符
pascal.taie.language.classes.ClassHierarchy
该类提供了类层次结构的相关信息
1
2
3Collection<JClass> getDirectSubclassesOf(JClass): 对于给定类,返回直接继承该类的子类
Collection<JClass> getDirectSubinterfacesOf(JClass) 对于一个给定接口,返回直接继承该接口的子接口。
Collection<JClass> getDirectImplementorsOf(JClass): 对于一个给定接口,返回直接实现了该接口的类需要实现 pascal.taie.analysis.graph.callgraph.CHABuilder 通过CHA 建立调用图
dispatch
原理如下

实现上采用循环的形式,每次都根据签名判断方法是否存在且是否为非抽象方法
resolve
1
你可以使用 CallGraphs.getCallKind(Invoke) 来获得调用点的调用类型原理如下

对于前两者调用方法类型,直接dispatch即可;对于后面virtual call,需要先找出当前类的所有子方法和子接口及子接口实现,然后调用dispatch
buildCallGraph
算法伪代码如下

这里不好实现的点在获取方法中的所有调用点,因为Stream
callSitesIn(JMethod) 这个方法返回的结果没法遍历,一种解决方法是直接拿到method中的IR,然后对IR中的stmt进行逐行判断,如果其类型为 Invoke,那就可以说明其是一个call site 然后进行resolve,返回的方法集加入调用图当中即可
实现过程间常量传播
解决 Edge Transfer
为了计算第 4 条语句的 IN fact,也就是方法
addOne()的 entry 节点的 IN fact,我们需要对 2→4 这条边应用 edge transfer,这样使得第 2 条语句的 OUT fact(a=6)转换为 x=6,并最终 meet 结果 x=6 到第四条语句的 IN fact中。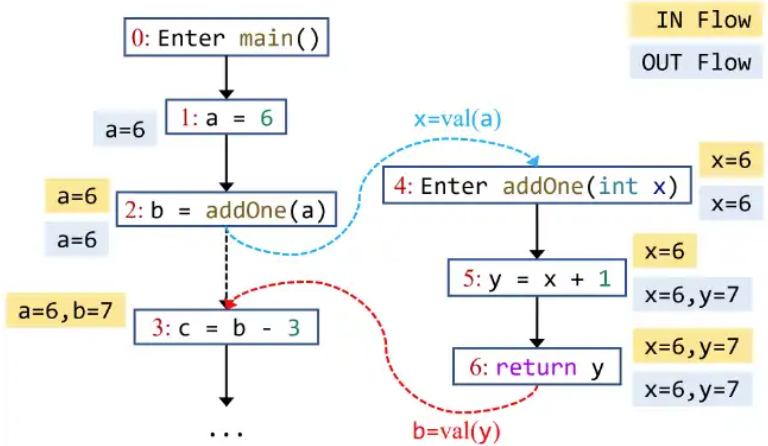
定义
transferEdge(edge, fact)方法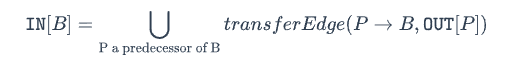
处理边的种类
- Normal edge 一般是与过程间调用无关的边。transferEdge(edge, fact) = fact
- Call-to-return edge 对于方法调用
x = m(…)edge transfer 函数会把等号左侧的变量(在这个例子里也就是x)和它的值从 fact 中 kill 掉。而对于等号左侧没有变量的调用,则视作恒等函数4 - Call edge 对于这种边,edge transfer 函数会将实参(argument)在调用点中的值传递给被调用函数的形参(parameter)。具体来说,edge transfer 首先从调用点的 OUT fact 中获取实参的值,然后返回一个新的 fact,这个 fact 把形参映射到它对应的实参的值。edge transfer 函数的返回值应该仅包含被调用函数的形参的值
- Return edge 被调用方法的返回值传递给调用点等号左侧的变量。返回的结果应该仅包含调用点等号左侧变量的值。如果该调用点等号左侧没有变量,那么 edge transfer 函数仅会返回一个空 fact。
需要了解的类
pascal.taie.analysis.graph.icfg.ICFGEdge
有四个子类关联上述的边
1
2
3
4pascal.taie.analysis.graph.icfg.NormalEdge
pascal.taie.analysis.graph.icfg.CallToReturnEdge
pascal.taie.analysis.graph.icfg.CallEdge
pascal.taie.analysis.graph.icfg.ReturnEdgepascal.taie.analysis.dataflow.inter.InterDataflowAnalysis
pascal.taie.analysis.dataflow.inter.AbstractInterDataflowAnalysis
它把 ICFG 中不同的点和边分派给对应 transfer 方法

pascal.taie.ir.exp.InvokeExp
程序中的方法调用表达式。它包含了被调用的方法引用和传入的各个参数
首先要熟悉这几个类型

按照每种类型的进行实现即可,特别说明
call-to-return edges 其首先需要kill掉调用点左边的变量,获取方式可以利用Invoke类的getResult方法

对于 Return edges
首先要对返回的结果做一次meetValue
edge.returnVars()里面有多个值,这是因为整个方法里的 return 语句都会指向 exit,再从 exit 连接单条 return edge 回上层方法然后再将值传回给调用点左边的变量,当然如果没有的话就返回一个空 fact
实现过程间 Worklist 求解器
与实验二基本一致,不同点:
在计算一个节点的 IN fact 时,过程间求解器需要对传入的 edge 和前驱们的 OUT facts 应用 edge transfer 函数(transferEdge)
但你仅需要对 ICFG 的 entry 方法(比如 main 方法)的 entry 节点设置 boundary fact
08 - Pointer Analysis
指针分析
对于OO语言,指针分析回答了变量可以指向程序中的哪些对象 may-analysis
输入程序,经过指针分析得到各个指向关系

影响指针分析的关键要素
指标:精度和速度
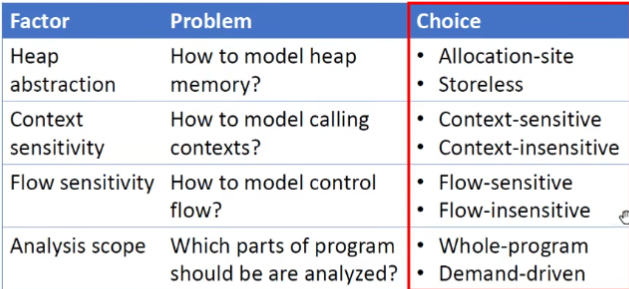
堆抽象:如何对内存进行建模
保证指针分析可以终止,避免受到死循环等场景的影响。通过将无穷的对象抽象成有限的(符合某些共性的抽象成一个)
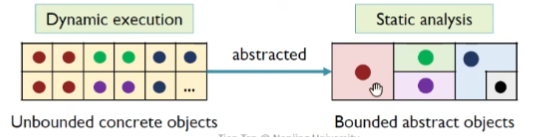
主要技术流派,这里学习Allocation sites
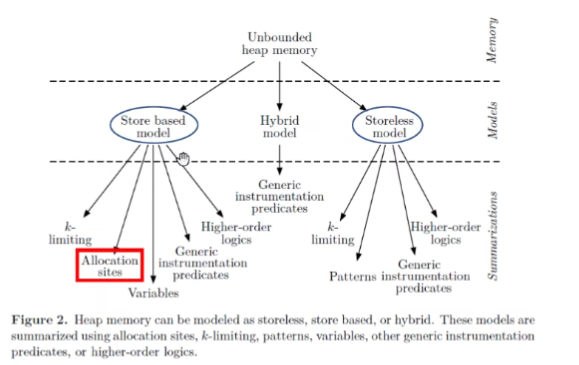
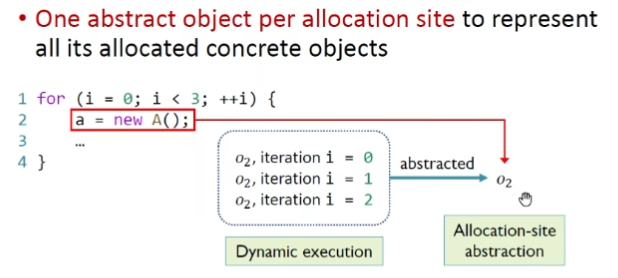
Allocation sites
在对象创建点(下标表示创建对象的位置)抽象对象来表示动态运行时所创建的对象。因为程序当中的创建点个数一定是有限的,所以可以保证静态分析中抽象对象时有限的
上下文敏感 context sensitivity
如何对上下文调用进行建模
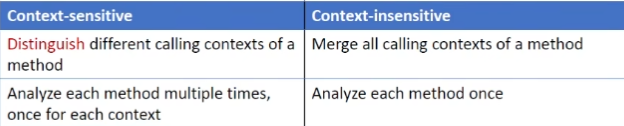
流敏感 Flow Sensitivity
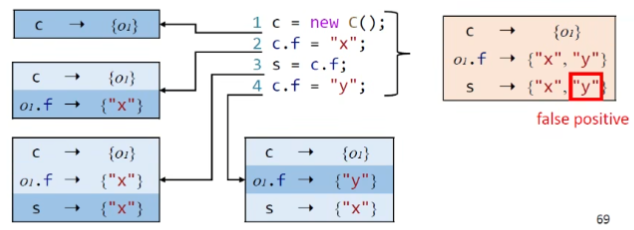
如何对控制流进行建模
控制流敏感的会遵循程序执行的顺序,并对每一个执行点维护一个指向关系的映射;而对于非敏感,会忽略掉程序执行的顺序,对整个程序只维护一个指向关系的映射

exp
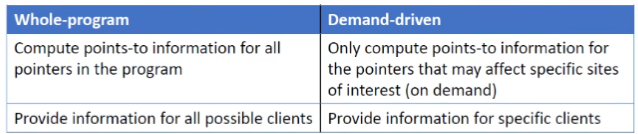
Analysis Scope
应该分析程序中的哪些部分
前者分析的结果可以适用于所有可能的应用;而对于后者按照需求进行指针分析,得到的结果适用于特定的应用
关注的语句
只关注直接影响指针指向的语句
对于数组比较特殊,通常是忽略下标的区别,建模成只有一个单个Field arr,所有的指向关系都存在这里


因此只专注于局部变量以及实例的属性,浓缩成下面的语句

调用Call时特别关注Virtual call的情况
09 - Pointer Analysis Foundations(I)
指针分析的规则
Domains and Notations 域及其记号
指针由两部分组成 所有变量以及Field

幂集对应指针的集合
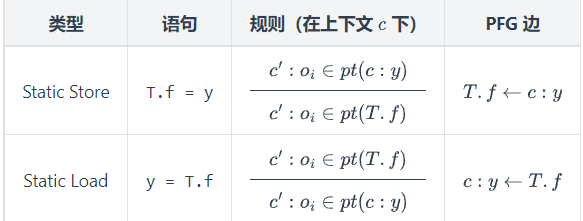
处理四种语句的规则
横线之上表示前提条件,只要上面的条件满足就可以推导出横线下的语句;没有写表示不需前提条件
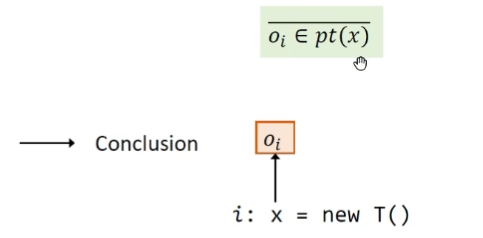
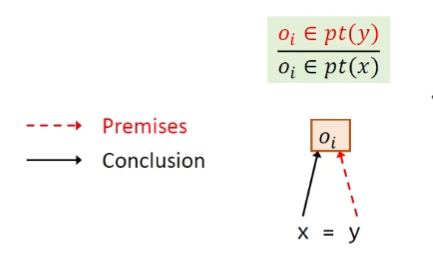
New 将对象$o_i$加入到变量x的指针集当中,箭头表示新的指向关系
Assign 对象$o_i$如果原先属于y的指针集的话,在赋值规则中也会将其加入到x变量的指针集当中
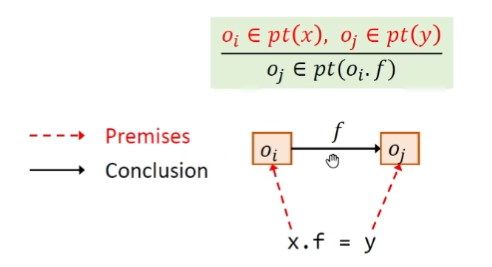
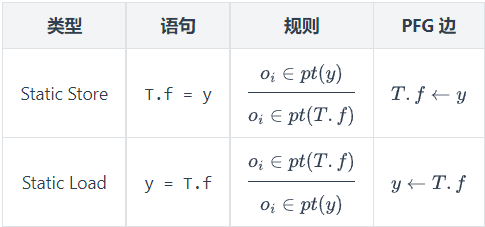
Store 如果x变量指向$o_i$,变量y指向$o_j$,则将Field $o_i.f$指向$0_j$
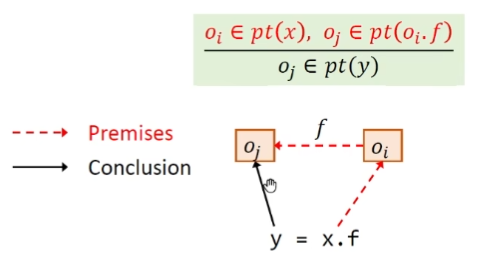
Load 如果变量x指向$o_i$,且Field $o_i.f$指向 $o_j$,那么就让变量y指向 $o_j$对象
09 - Pointer Analysis - Foundations I
如何实现指针分析
指针分析本质就是在指针之间互相传播指向信息
可以看作之间满足某种包含约束关系

关键点:变量x的指针集更新时,要把变化的信息传播给和x关联的其他指针,如何传播??
利用图的数据结构

Pointer Flow Graph 指针流图
结点注意对象指的是抽象对象,流动关系都是may的关系

如何构建边?
基于程序的语句和对应的规则
exp
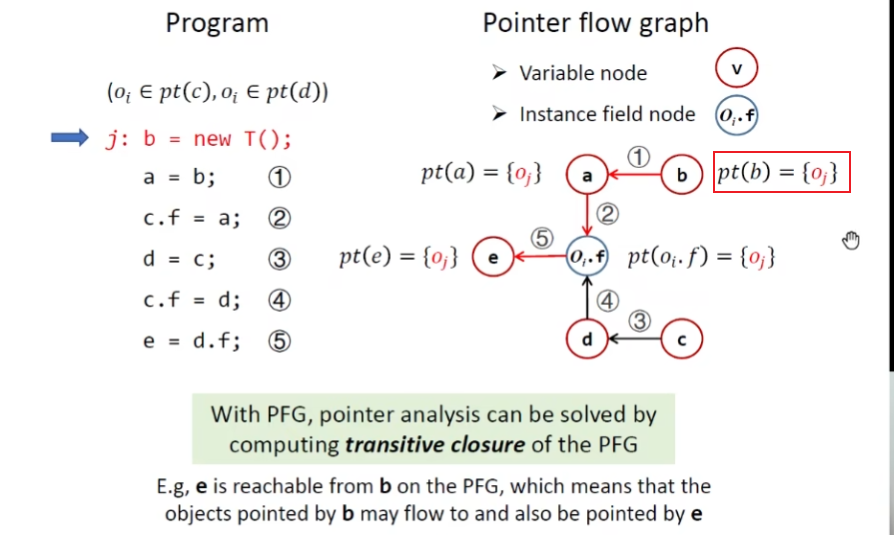
通过PFG,指针分析就可以转换为求解图上的传递闭包关系(利用图的可达性信息)
构建PFG与在其上进行指向信息的传播两者是相互依赖的,PFG在指针分析过程中是动态更新的
指针分析算法

worklist
WL的元素为指针变量和其对应的指针项(要加入到变量的指针集中),表示需要被处理的指向信息

先简化看 只看new和赋值语句
这里注意在赋值语句AddEdge方法中,如果s存在指向关系集,也需要将加入到对应t的指向关系集当中(这里就是加入到worklist中)

处理worklist当中的东西
这里注意到有个减法操作,表示我们要先将已有的指向关系去重,只添加新增的指向关系

指针集的变化真正是发生在算法第二行处,之后还需要将pts传给n的后继结点

有个细节就是集合操作为什么也需要去重操作?
指针集中已有的元素已经被传播到对应指针的后继当中了,所以就不需要再去传播一遍,采用差异传播的方式来进行
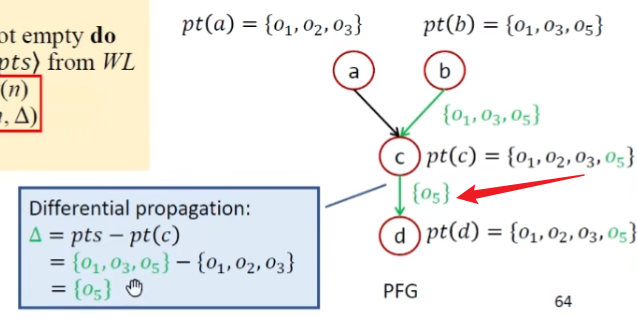
接下来处理store 和 load
新的指向信息可能引入新的PFG边,可能的意思是指存在多个变量指向同一个对象$o_j$,其他变量在处理时可能已经构建过这条边

exp(分析基于流不敏感,不关心语句的顺序)

实验3 死代码检测
控制流不可达
检测方法:遍历所在方法的控制流图并标记可达语句
分支不可达
- if 语句的条件值是一个常数(利用常量传播得知)
- switch语句
预先对被检测代码应用常量传播分析
无用赋值
一个局部变量在一条语句中被赋值,但再也没有被该语句后面的语句读取、
检测方式:
- 我们需要预先对被检测代码施用活跃变量分析。对于一个赋值语句,如果它等号左侧的变量(LHS 变量)是一个无用变量(换句话说,not live),那么我们可以把它标记为一个无用赋值。
需要利用的类
pascal.taie.analysis.graph.cfg.Edge本次实验需要考虑四种边的种类
IF_TRUE、IF_FALSE、SWITCH_CASE和SWITCH_DEFAULT
如何获取和检查边的种类?
1
2Edge<Stmt> edge = ...;
if (edge.getKind() == Edge.Kind.IF_TRUE) { ... }对于
SWITCH_CASE边,可以通过getCaseValue()方法来获取它们对应的 case 分支的条件值
pascal.taie.ir.stmt.If(Stmt的子类)表示程序中的 if 语句
pascal.taie.ir.stmt.SwitchStmt(Stmt的子类)pascal.taie.ir.stmt.AssignStmt继承关系如下,所以对于方法调用这种情况的赋值语句我们本次实验不关注,仅关注 AssignStmt这个类即可
思路:这里首先遍历整个控制流图,对于未标记的语句即为不可达代码。遍历方式可以采用DFS或BFS
在遍历 CFG 时,你需要对当前正在访问的节点使用
CFG.getOutEdgesOf()来帮助获得之后要被访问的后继节点控制流不可达
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25TreeSet<Stmt> unreachedStmts = new TreeSet<>(Comparator.comparing(Stmt::getIndex));
for (Stmt stmt : cfg) {
unreachedStmts.add(stmt);
}
TreeSet<Stmt> reachedStmts = new TreeSet<>(Comparator.comparing(Stmt::getIndex));
Stmt entry = cfg.getEntry();
BFS(cfg, reachedStmts, entry);
for (Stmt reachedStmt : reachedStmts) {
unreachedStmts.remove(reachedStmt);
}
// 控制流不可达
for (Stmt unreachedStmt : unreachedStmts) {
deadCode.add(unreachedStmt);
}
---
private static void BFS(CFG<Stmt> cfg, Set<Stmt> stmts, Stmt curStmt) {
if (!stmts.contains(curStmt)) {
stmts.add(curStmt);
cfg.getOutEdgesOf(curStmt).forEach(outEdge -> {
BFS(cfg, stmts, outEdge.getTarget());
});
}
}对于分支不可达,我们需要预先对被检测代码应用常量传播分析,通过它来告诉我们条件值是否为常量,然后在遍历 CFG 时,我们不进入相应的不可达分支
条件值的获取利用常量传播分析得到的结果,调用的API为
constants.getOutFact()通过得到的变量进一步判断是否为常数。你需要对当前正在访问的节点使用
CFG.getOutEdgesOf()来帮助获得之后要被访问的后继节点。这个 API 返回给定节点在 CFG 上的出边,用它进一步判断是否是经过常量判断可达的出边。这里有一点需要注意,Edge类边本身并不代表表达式类型,而是一种连接关系,想要获得其可以延伸到哪一个结点,调用getTarget()进一步判断对于赋值语句,首先只用考虑
AssignStmt类,在左边变量存在的情况下,利用活跃变量分析的结果去晒出所有非活跃变量且右边赋值无副作用影响的表达式,即为死代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 无用赋值检测
for (Stmt stmt : cfg) {
if (stmt instanceof AssignStmt) {
AssignStmt assignStmt = (AssignStmt) stmt;
if (assignStmt.getDef().isPresent()) {
LValue lValue = assignStmt.getLValue();
RValue rValue = assignStmt.getRValue();
// 为了检测无用赋值,我们需要预先对被检测代码施用活跃变量分析
SetFact<Var> outFact = liveVars.getOutFact(assignStmt);
if (lValue instanceof Var) {
// 如果非活跃变量,且无副作用
if (!outFact.contains((Var) lValue)) {
if (hasNoSideEffect(rValue)) {
deadCode.add(assignStmt);
}
}
}
}
}
}
如何从分支不可达当中剔除掉死循环的部分?
形如
while(true)的语句死循环之后其后面的所有语句包括return等就不可达了,但是exit节点仍然应当被加入进来,所以初始化的时候应该是entry和exit都加入
按照前面的写逻辑会有问题,感觉逻辑上是分开的,先筛一遍控制不可达再晒一边分支不可达最后筛无用赋值,这样会导致类似死循环问题由于分支不可达的判断直接抛掉后续的语句,应该是所有分析结果结束之后再做筛选
1 | |
作业5 非上下文敏感指针分析
新的分析规则
对于数组的索引,无视下标,均视作field字段

假设 $o_i$ 代表一个数组对象,那么我们用表示一个指向数组中所有对象的指针(无论保存在数组的什么位置)。

静态方法. 静态方法的处理与实例方法大体相同,除了1)我们不需要在 receiver object 上进行 dispatch 以解析(resolve)出被调用的方法,2)我们不需要传 receiver object。因为静态方法的处理不需要考虑 receiver object(静态方法中是没有this变量的),因此它的处理规则也比实例方法更简单。所以相当于只需要传参数和返回值即可
需要了解的类
pascal.taie.ir.stmt.DefinitionStmt
表示程序中所有的定义语句,(包括方法调用的)。在本次作业中,所有影响指针的语句都是这个类的子类
注意
isStatic()可以检查语句调用的对象时实例还是静态字段pascal.taie.ir.exp.Var
它表示 Tai-e IR 中的变量。对于所有实例字段 loads/stores、数组 loads/stores 或实例调用的 base 变量,这个类提供了一些方便的 API 来查找相关语句。

pascal.taie.language.classes.JField
这个类表示程序中的各个字段
pascal.taie.analysis.pta.core.heap.Obj
这个类表示指针分析中的抽象对象,即指针集(points-to sets)中的对象
pascal.taie.analysis.pta.core.heap.HeapModel
这个类表示堆模型(即堆抽象),它用来对堆对象进行建模。你可以使用
HeapModel的getObj(New)方法来获得与它对应的抽象对象(即Obj)
堆抽象返回值唯一
pascal.taie.analysis.pta.ci.PointsToSet
这个类表示指针集,即指针分析中的
Obj集合pascal.taie.analysis.pta.ci.Pointer
这个类表示分析中的指针,即 PFG(指针流图,pointer flow grpah)中的节点。每个指针都与一个指针集相关联,你可以调用
getPointsToSet()来获得这个指针集该类存在4个子类
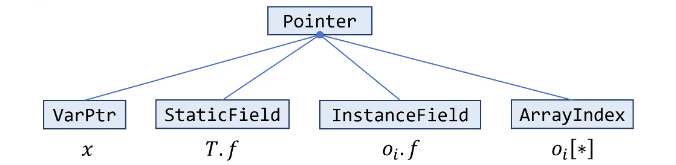
与下图对应

pascal.taie.analysis.pta.ci.PointerFlowGraph
还维护着从变量、静态字段、实例字段、数组索引到相应指针(即 PFG 节点)的映射,因此你可以利用这个类的 API 获得各种指针
pascal.taie.analysis.pta.ci.WorkList
这个类表示指针分析算法中的 worklist
pascal.taie.analysis.pta.ci.Solver
可以使用前面作业中介绍的
DefaultCallGraph的 API 来修改调用图
需要实现的API
void addReachable(JMethod)
这里学习一种新的设计模式:访问者模式https://refactoringguru.cn/design-patterns/visitor
对于不同种类的语句,你需要使用不同的逻辑来处理。
Tai-e 的 IR 天然支持访问者模式。具体来说,Tai-e 提供了
pascal.taie.ir.stmt.StmtVisitor类,这是所有Stmt访问者的通用接口,它为所有种类的语句都声明了访问操作。另外,Stmt的非抽象子类都实现了accept(StmtVisitor)方法,因此它们可以回调来自具体访问者的访问操作。出于方便,我们提供了
Solver.resolveCallee(Obj,Invoke)来解析 Java 中静态调用、虚调用、接口调用和特殊调用(static, virtual, interface, and special invocations)的被调用者。原理如图

先说一下底下的全局数组值都对应哪个变量,RM位于
DefaultCallGraph类中,可以通过addReachableMethod方法进行添加;而对于变量S,实验框架为了方便存储和处理,直接关联到了每一个Var上,即内部类RelevantStmts。对于我们想要寻找的语句只需调用对应类型的API即可在框架里面,因为每个方法都生成了 IR,相应地也会为每个变量添加好
RelevantStmts。这会导致一些空间的消耗,但是因为变量都是局部的,当你访问到一个变量时,其相关语句必然也是reachable的因此我们可以忽略 $S_m$ 的添加,在遍历时即已经添加完成。接下来只需对New
,Copy, 以及静态的Inoke,StoreField,LoadField按照对应的规则进行处理即可。
这里特别说明静态方法调用的处理,相比于实例方法调用,少了传递receiver obj 和dispatch的操作,但仍需要找到对应的目标方法。这里可以利用`resolveCallee()`,参考ProcessCall


void addPFGEdge(Pointer,Pointer)
原理如下

void analyze()
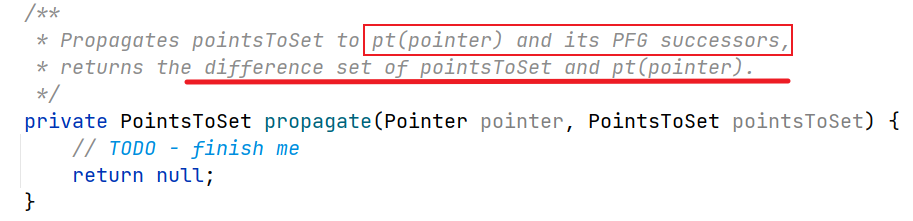
这个方法实现了
Solve函数的主要部分,即while循环部分不要忘记在这个方法中处理数组 loads/stores。
这里第一个细节在于遍历 $\triangle$ 应为propagate的返回值,即对所有变动的指针集中的对象进行分析处理,这里注意一下该函数的返回值即可留意到
接下来在处理实例变量的load和store语句,要辨析
x.f = y和y = x.f中对应变量的关系,充分利用指针提供的API对于数组的store和load,
pointerFlowGraph.getArrayIndex(obj)即可得到数组的下标属性指向的对象PointsToSet propagate(Pointer,PointsToSet)
该算法合并了算法中的两个步骤,它首先计算差集(
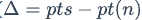 ),然后将 $pts$ 传播到 $pt(p)$ 中。它返回 $\triangle$作为调用的结果。
),然后将 $pts$ 传播到 $pt(p)$ 中。它返回 $\triangle$作为调用的结果。
void processCall(Var,Obj)
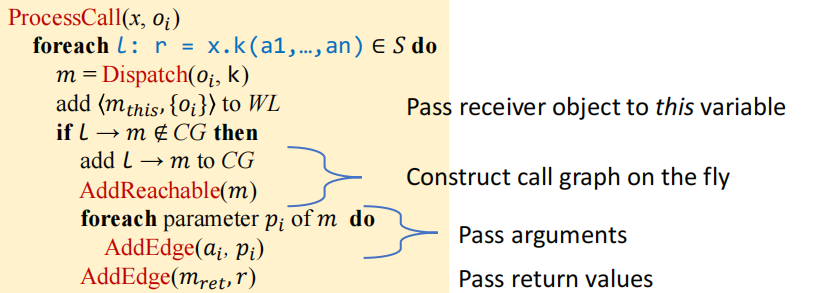
为了保证 soundness,你应该将一个方法中由返回变量(即返回语句中出现的变量)所指向的所有对象传播给其调用点等号左侧的变量。你可以通过相关的
IR对象获得一个方法的所有返回变量
10 - Pointer Analysis - Foundations II
如何处理方法调用
相对于CHA,指针分析根据实际所指的对象来计算指针集(不光只看声明类型)
实际方法调用时JVM出现的变化
dispatch实际方法
传 resolve object
传参数
传返回值
规则

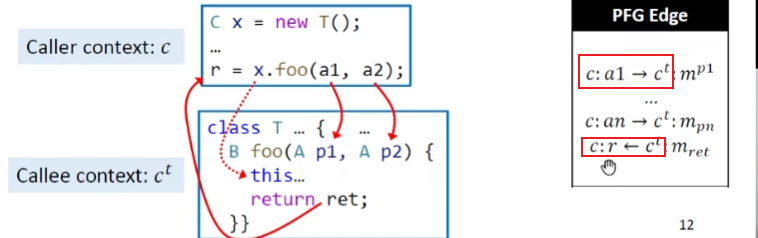
k即调用点方法的签名,传Receiver object给$m_{this}$,即将实际调用方法的对象传给方法中的this变量。然后进行实参传给形参,为了方便传参都会建立PFG边。最后返回值从目标方法返回返回值变量用$m_{ret}$表示
为什么this不建边呢?
Receiver object只会流向它实际调用方法的this变量当中去,但是PFG边的构建是会将所有指向对象都连上,这样会引入很多假的调用关系

那为什么参数和返回值可以连?
参数无法决定实际调用哪个方法,所以采取保守手段。但是this更精确就不用连
过程间指针分析方法处理
与CHA类似,指针分析的调用方法处理也是与CALL Graph互相依赖。但后者会从一个入口方法开始,慢慢去探寻可达的方法,最终建立Reachable World,仅在可达方法上作分析
算法

entry方法可以理解为程序的入口方法(如main)
AddReachable()扩展Reachable World
这里看到在新方法加入时只处理new 和 赋值语句。load和store需要根据指针信息的内容来处理,但前两者不需要所以这里在刚加入时只做这两个处理
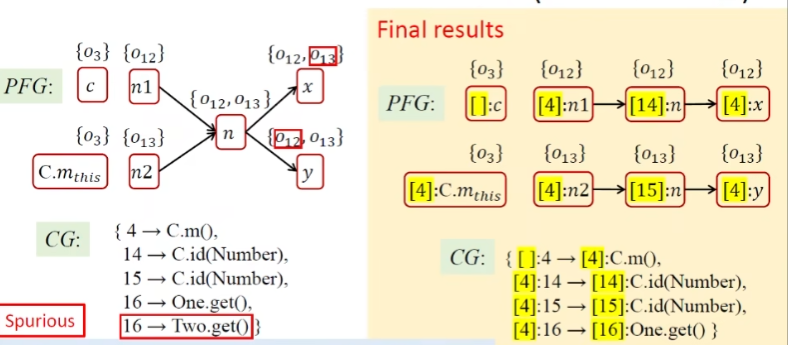
ProcessCall(x, o_i)过程调用,实际就是对上面Rule的实现。x的receiver object的变量,$o_i$就是表示流向x的新对象这里注意在dispatch的时候,虽然引入了新的对象,但是实际寻找的调用目标方法到m的边之前可能已经连过(存在其他的指向对象但是调用的相同的目标方法)

整个算法输出:指针集以及Call Graph
exp
初始化

大循环
处理b的ProcessCall

与CHA 处理的对比

foo方法内的变化 AddReachable 传参 传返回值

处理剩下的WL中的指向关系

11 - Pointer Analysis - Context Sensitivity I
上下文不敏感指针分析引起的精度下降的问题

上下文不敏感不准确的本质
动态执行时,一个方法可以调用多次,每次调用的上下文均不同(参数 返回点),导致指向不同的对象

上下文敏感模型建模就是能区分不同上下文之间的数据流
最早的策略采用调用栈抽象的方式
把一系列call sites(调用方法的位置)串起来

通过给予不同方法不同上下文前提,也就标记了方法中的变量也在不同上下文中,指向不同的对象。每个上下文对应一份方法和其中变量的克隆副本
上下文敏感 Heap
给抽象的堆当中加入上下文,得到粒度更细的堆抽象
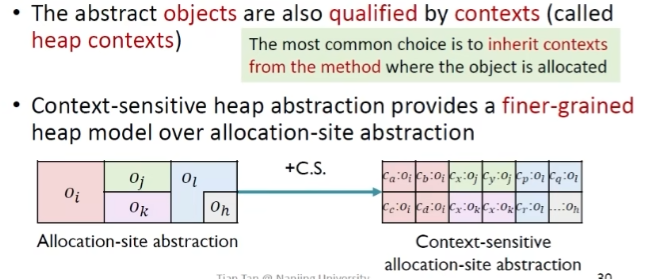
为什么会有用?
每一个创建出的对象会根据不同的数据流给予不同操作

exp
没有上下文敏感堆抽象的分析,实际上x1和x2是指向两个对象的,因此导致最后newX方法的结果合并到一个对象中去了

有上下文敏感堆抽象的分析

但是如果只给heap加上下文,不给变量加上下文

也就是说两者需要共同作用才能更好提升精度
规则
Domains and Notations

Rules

New语句,变量在上下文c之下,指向在上下文C之下创建的对象$o_i$(堆抽象也加上下文)
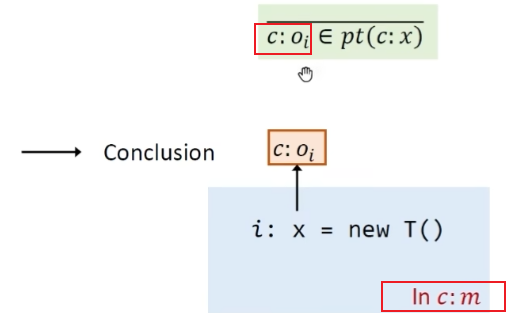
Assign赋值语句,x和y在同一上下文中
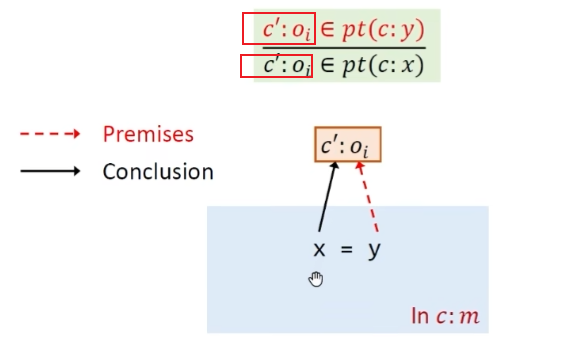
Store语句,分别取x和y在上下文c中所指向的对象
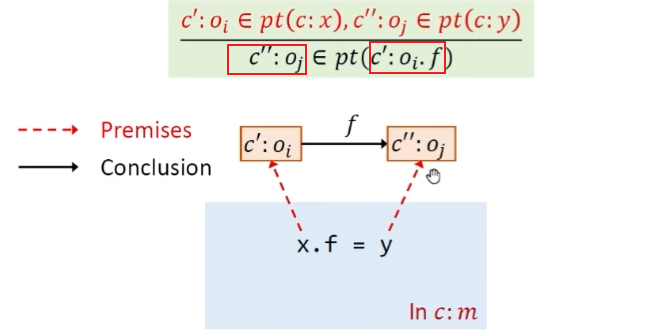
Load语句,先去找x在上下文c中指向的对象,在找x.f指向的对象
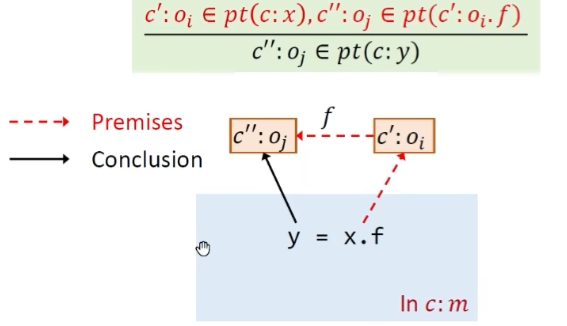
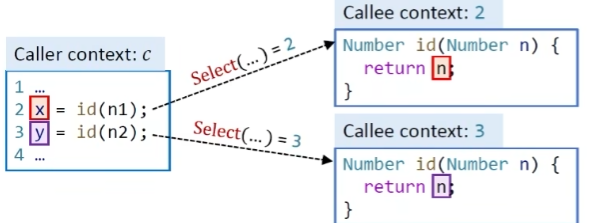
Call语句,首先找到receiver object x在上下文c中指向的对象。然后dispatch出对应的方法(根据方法签名和receiver object),其次要去选择对应上下文中的方法,定义Select方法,根据调用点l拿到的所有信息来选择上下文


exp
之后传receiver object 给指定$c^t$上下文中的方法m,然后传参数也是如此。最后传返回值,返回给指定上下文的变量(这个调用点和目标上下文方法是关联的,知道数据流的流动来源)
12 - Pointer Analysis - Context Sensitivity II
上下文敏感指针分析算法
Pointer Flow Graph with C.S.
结点:程序当中上下敏感的指针(变量或者对象的field),每个结点都带有上下文信息
边:指针流向关系

对于调用方法的规则,主要传参和返回值时上下文的选择
算法

RM代表已经可达的带有上下文信息的方法
call site和 callee都要有上下文(更准确)

AddReachable
入口方法给一个空的上下文
对于new语句,堆抽象的上下文来自方法传进来的上下文

Propagate方法和AddEdge方法和CI一样
这里x和y的上下文是一样的,这样保证了不同方法分析时是出于不同上下文下

ProcessCall
这里最关键的一步是选出上下文Select函数
c就是调用点所在上下文,l代表调用点 c’ 代表receiver object所在上下文

Select函数如何选择
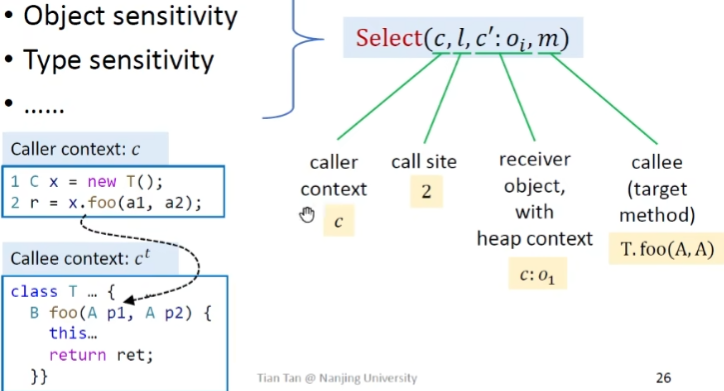
仅考虑其中一两个参数作为上下文的选择
上下文敏感 Varints
调用点敏感
每个上下文由一系列调用点构成一个call chain. 本质上就是对调用栈的抽象

exp

对于递归调用,则将会有无穷个上下文。因此需要保证算法能够终止,采用k-Limiting Context Abstraction,限制调用链长度

假设k取1

一般k取2 保留最后一个上下文
exp

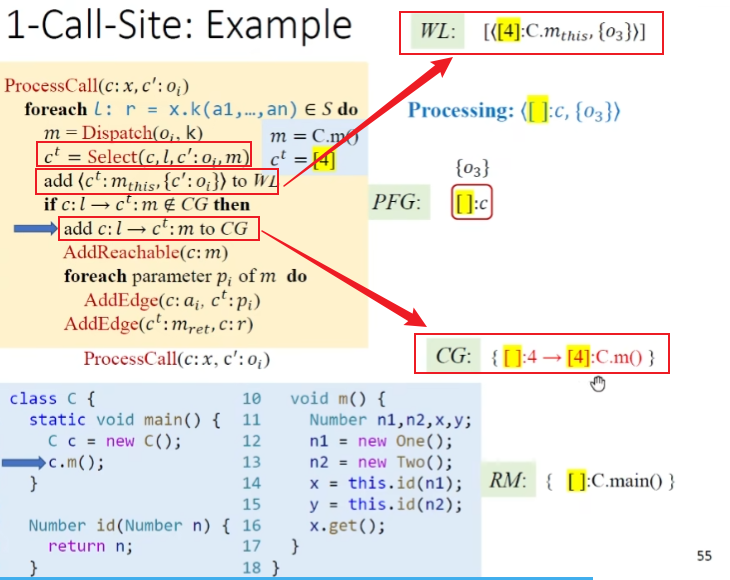
处理方法m中的AddReachable

处理worklist剩余指针对,调用id方法 传参 传返回值
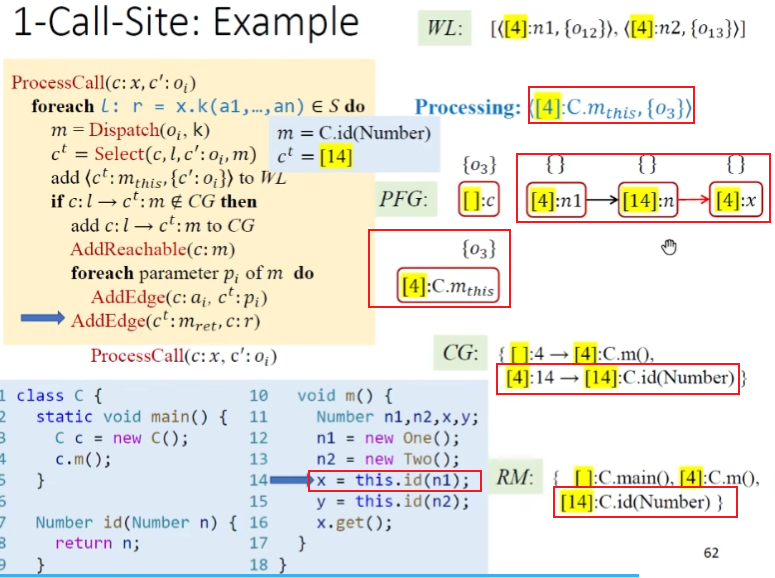
与15行调用的对比
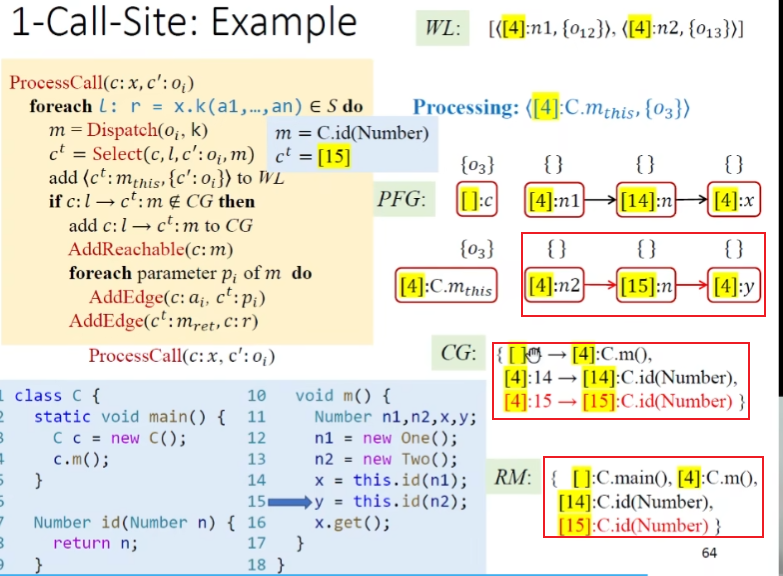
继续处理worklist

与上下文不敏感对比,前者则会将数据流混在一起,x和y一定会有误报出现
对象敏感
对于OO语言,对receiver object作为上下文策略

exp

a1.get()调用时即可很容易得到this来自上下文o1 this.f即o1.f也就是指向o3
每个this变量一定是上下文本身
与 1-call-site作对比,前者是不能够分开的,就是因为在doSet方法这里有一个数据流汇合

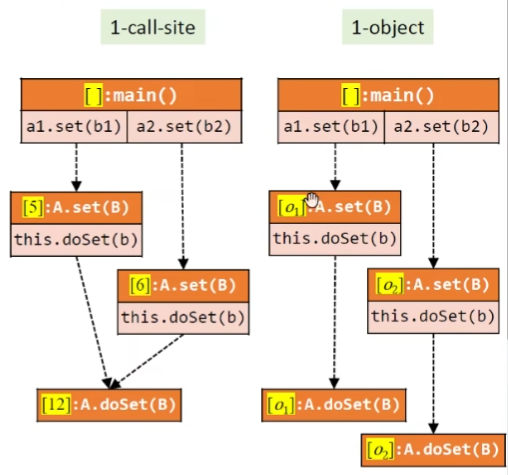
但是对于刚才的程序,1-object就不行,因为这里this是一样的

类型敏感
基于对象敏感技术的进一步抽象
调用点 receiver object 所在的类型作为上下文

对象敏感粗粒度的抽象
exp

实验6 上下文敏感的指针分析
新处理规则
静态字段
数组索引
常规的指针分析不区别对针对同一数组不同位置的 store 和 load

静态方法
1)不需要在 receiver object 上通过 dispatch 来解析出被调用方法。2)不需要传递 receiver object

需要了解的类
IR、Var、InvokeExp以及DefinitionStmt的子类 JMethod、JField、Obj和HeapModelpascal.taie.analysis.pta.core.cs.context.Context
该类表示上下文敏感的指针分析中的上下文
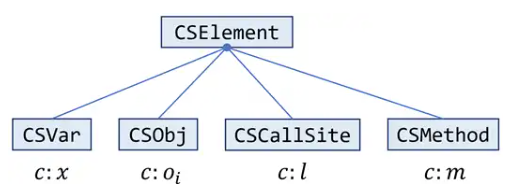
pascal.taie.analysis.pta.core.cs.element.CSElement
该类表示指针分析中需要用到上下文的元素,每个这样的元素都和一个上下文相关联。四个子类如下
pascal.taie.analysis.pta.core.cs.element.Pointer
该类表示上下文敏感指针分析中的指针,每个
Pointer和一个PointsToSet相关联,通过调用getPointsToSet()取得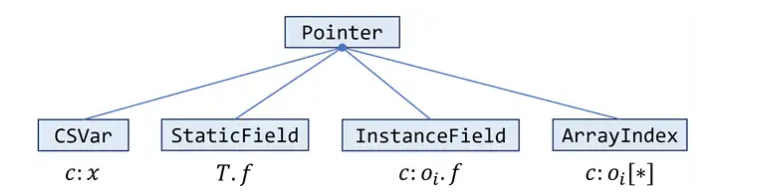
pascal.taie.analysis.pta.core.cs.element.CSManager
该类管理所有需要用到上下文的元素和所有上下文敏感的指针。
pascal.taie.analysis.pta.core.cs.selector.ContextSelector
该类是上下文敏感指针分析框架和具体的上下文敏感策略(如调用点敏感、对象敏感等)之间的接口。
该类有 4 个 API,其中一个 API 返回空上下文,另外三个 API 分别为静态方法、实例方法和堆对象(heap object)选择上下文。
当你在上下文敏感指针分析中处理
Invoke和New语句时,你需要使用本类的各个子类中的方法来生成目标方法(Invoke语句)和新创建对象(new语句)的上下文。pascal.taie.analysis.pta.core.cs.CSCallGraph
该类表示上下文敏感的调用图.你需要使用其中的
addReachableMethod(CSMethod)以及addEdge(Edge)这两个 API 来修改调用图。pascal.taie.analysis.pta.pts.PointsToSet
可迭代
pascal.taie.analysis.pta.pts.PointsToSetFactory
该类提供创建
PointsToSet的静态工厂方法。
pascal.taie.analysis.pta.cs.PointerFlowGraph
该类表示程序的指针流图 PFG
pascal.taie.analysis.pta.cs.WorkList
该类表示指针分析算法中的 WorkList。
pascal.taie.analysis.pta.cs.Solver
API1: void addReachable(CSMethod)
原理如下
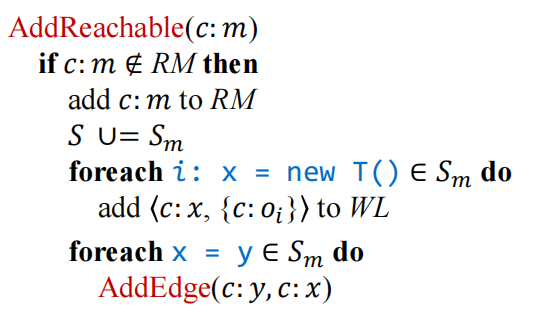
方法
Solver.resolveCallee(CSObj,Invoke)用于解析各种方法调用的被调用方法这里依然采用访问者模式来处理方法中的不同类型语句,不同点在于这里加上了上下文,因此不能再用同一个StmtProcessor,在用的时候创建即可;其次,我们需要注意对于New 和 Invoke语句要ContextSelector类生成上下文

然后利用csManager,来获得带有上下文的指针
对于静态方法调用,不需要dispatch和传this变量,其他参考

依然记得resolveCallee对于静态方法来说,其recv设为null即可。同时,要分清调用点方法的上下文以及调用者所在上下文之间的关系。
API2: void addPFGEdge(Pointer,Pointer)
原理如下
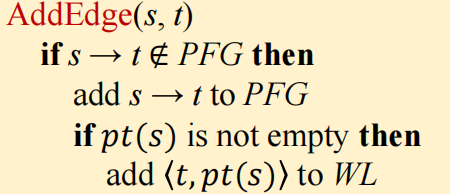
API3: void analyze()
实现 Solve方法中while 循环的部分
基本不变,指针获取方式改一下就行
API4: PointsToSet propagate(Pointer,PointsToSet)
和上次作业一样先算差集

API5:void processCall(CSVar,CSObj)
把处理静态方法的改一下就好

实现常见的上下文敏感策略
需要了解的类
pascal.taie.analysis.pta.core.cs.selector.ContextSelector
实现另外6个子类
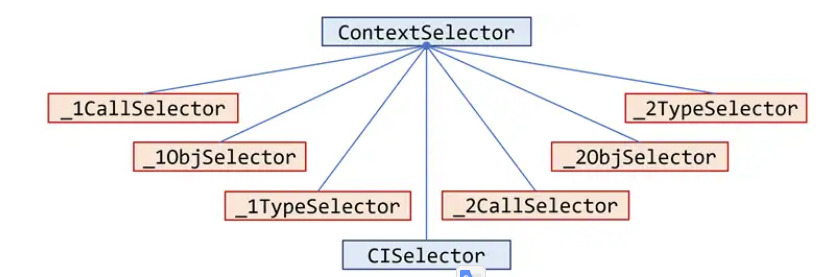
分别对应即调用点敏感(call-site sensitivity)、对象敏感(object sensitivity)和类型敏感(type sensitivity)。对每个策略,你需要分别实现两个 selector(分别针对 k-limiting 的上下文中的k=1 和 k=2)
pascal.taie.analysis.pta.core.cs.context.ListContext
该类实现了
Context接口,它将每个上下文表示为一个由若干同类型元素组成的有序列表(对三种上下文敏感策略,该列表分别采用不同的元素来表示上下文:调用点敏感使用的元素为Invoke,对象敏感使用的元素为Obj,类型敏感使用的元素为Type)。该类提供一系列静态工厂方法,即
make(...)方法来创建上下文。对每个k 层的 context selector,其堆上下文(heap context)的层数为 k-1
首先是调用点敏感上下文
对于1层的实现,其堆上下文的层数为0层,因此直接返回一个空集即可;对于静态方法的调用点上下文和实例方法,由于只有一层,因此直接返回调用点的上下文即可。对于两层的实现,其堆上下文的层数为1。细节在于其堆上下文继承于调用方法的上下文,因此直接选取调用方法的上下文并作筛选层数即可。我们要注意,调用点敏感使用的元素为
Invoke,对象敏感使用的元素为Obj,类型敏感使用的元素为Type),这个也就是ListContext类修改上下文时所操作的元素,对于调用实例方法,我们只需要将调用点的上下文与调用者组合在一起即成为被调用方法的上下文;而对于静态方法调用,由于调用者本身并没有上下文,所以只需要传递调用点上下文即可

其次是对象敏感上下文,对象敏感使用的元素为
Obj。对于静态方法调用,直接地使用调用者方法的上下文作为被调用方法的上下文。对于堆上下文的选择,是不用创建新的上下文的,因为其是基于对象进行的选择,这里并没有新的recv object,只是需要降为k-1层堆上下文即可
最后是类型敏感,其是对象敏感的进一步抽象,取调用点所在类的类型作为上下文的元素

13 - Static Analysis for Security
信息流安全
本质目标:保护信息安全,阻止危险的信息流
常见手段:访问控制但是不足,无法获知拿到信息之后的情况

信息流的定义
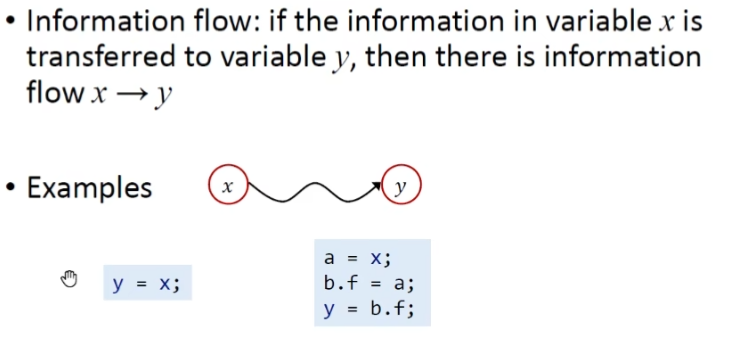
信息流如何与安全进行结合?
为程序中的变量设定等级,且规定不同等级之间的信息如何进行流动(指定策略)
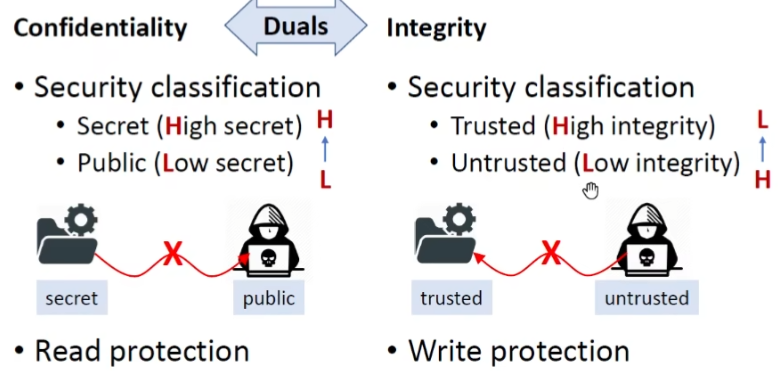
安全等级
基本模型采取两级策略

分级也可以用格的概念来表示,因为之间具有偏序关系

信息流策略
非干涉策略

public的内容可以被外界观测到的,也就是说不能通过外界观测到的public中的信息反推测出secret中的信息
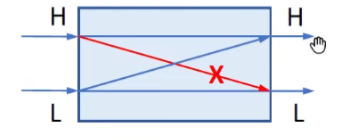
高密级信息不能流向低密级,从格的角度来看,信息流只能往上流动

保密性和完整性
组织隐私信息被观测到 -> 保密性
完整性:阻止的是不可信任的信息,防止它们污染我们关键的信息
也就是说完整性阻止的信息流是反向的
显式流和隐藏信道(程序中信息流动的方式)
直接通过copy方式的叫做显式流
隐式流:

当然,这种由密码信息泄露的控制带来的副作用要可以被观测到
这里如果能观测到异常的话比如数组越界,仍然能推断出秘密的信息

这一类信息称为隐藏信道,其本身机制的目的并不是为了信息传递


通常情况下显式流携带的隐藏信息更多,隐藏信道携带的隐藏信息有限,因此我们更多关注显式流
污点分析
将数据分为两类,污点数据是我们所关注的数据,打上标记方便追踪
其他数据即不关心数据
污点数据的源头称为source,污点分析关心数据流是否会流动到特定的位置(sinks)
两类应用:保密性和完整性

指针分析与污点分析的关系
一个污点数据是否能流到sinks? -> 调用sink方法的指针是否可以指向一个污点数据?
把污点数据视为一类特殊的object,把source视作allocation sites,也就是调用source时产生的污点数据

如何借助指针分析实现污点分析
首先需要拓展域(上下文不敏感指针分析为例)

规定输入和输出

规则
处理source
产生污点数据

传播污点数据
规则与指针分析是一样的
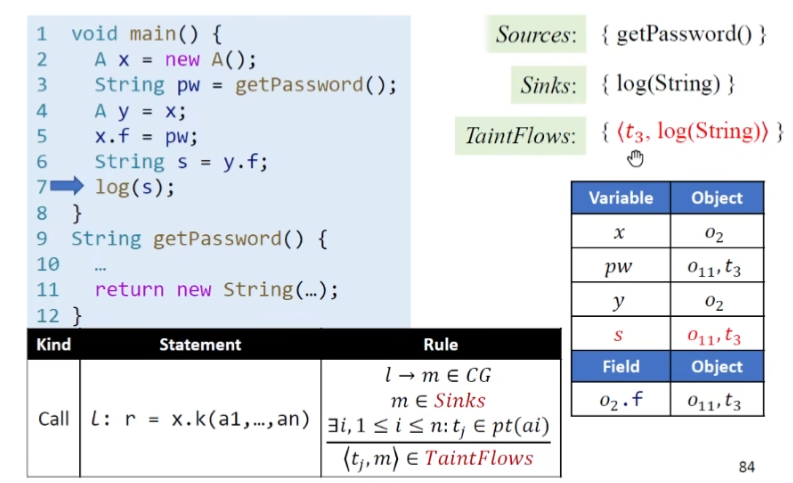
处理sinks
如果方法为sinks方法,则遍历方法参数的指针集,若其中发现了污点数据,则会产生一个taintflows输出当中

exp
14 - Datalog-Based Program Analysis
Datalog
本身是一个声明式逻辑语言

Data部分:以谓词的形式表示
什么是谓词?一系列陈述的集合,陈述了不同客体之间的事实,可以看作是一张表

fact可以看作表中的一行,由值构成的元组是表中的一行
基本元素 Atoms
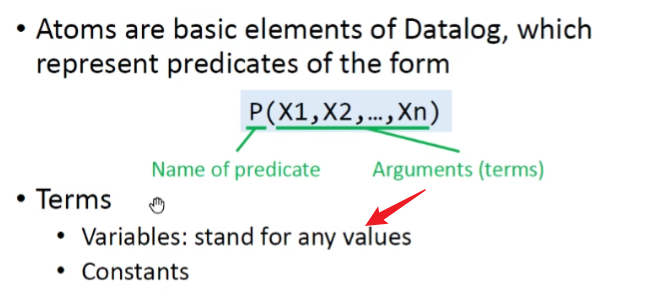
$P(X1, X2, \dots, Xn)$ 也叫作关系型谓词,Datalog也有算术型谓词 如 $age \geq 18$
Datalog Rules (Logic)
如何根据已有的谓词推导出新的谓词
推导式形式:

逗号可以看作逻辑与
如何去解读规则?枚举所有可能的谓词组合,当所有子目标为真时,head也为真,即可推导出一个新的谓词

exp


最开始的Facts从哪来的呢?
Datalog的谓词划分为两类

逻辑或关系的表示
写多条rules

使用分号逻辑运算符

逻辑非的表示
可以是原子目标的取反

支持递归Recursion规则
IDB可以直接或间接从自身推导出来
例如图的可达性

规则的安全性
对于第一个,如果y属于B且是EDB类型的,那么就会存在无穷多个x,也就推导无穷个谓词来;右边同理

因此为了避免这种情况,变量必须出现在谓词当中且无非逻辑出现,这样相当于变量是有限的,因为表是有限的

还有一种可能出现问题的情况:Recursion and Negation
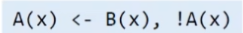

原子如果能递归的推导出它的非是没有意义的,会出现环的情况
因此Datalog的fact是单调的,且一定是有限的(为了满足规则的安全性)
实现指针分析
EDB:从程序语法上可以直接提取的指针信息
Datalog下谓词表示

exp
EDB输入

规则的定义(流不敏感)

实际处理过程

方法调用如何处理
规则如下
规则1

规则2,传参数
调用点l第i个参数对应的变量a

规则3 传返回值

全程序指针分析Datalog实现
加一条入口方法的规则;处理New的时候也加一个限定,表示allocation site在哪个 Reachable方法当中,而对于其他条件都依赖于指向关系,当没有时都不会触发

Datalog实现污点分析
EDB和IDB谓词声明
Taint谓词把每个call site关联其产生的污点数据

如果t污点数据流到sinks方法,而t也跟call site关联
规则描述
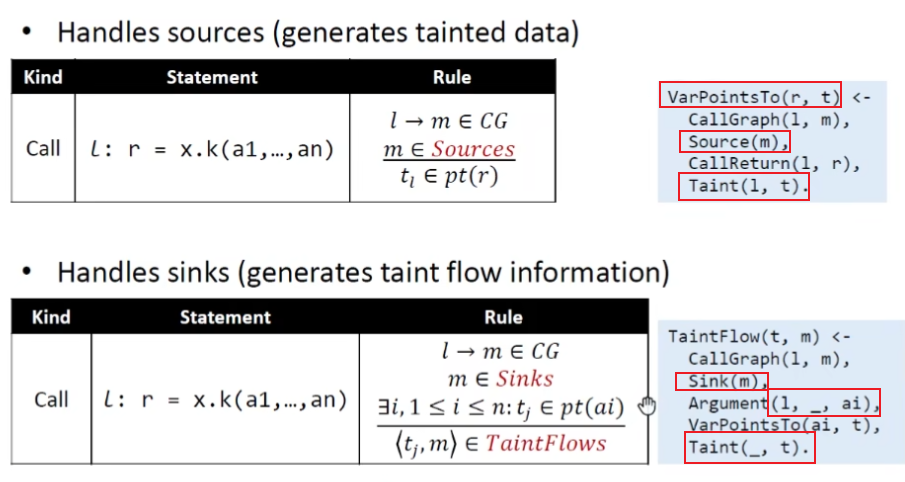
sinks的call中不关心参数的下标
实验7 Alias-Aware的常量传播
别名
指向内存中的同一位置的不同符号互为别名
在别名存在的情况下,通过对一个字段/数组的访问来修改一个实例字段/数组将会同时修改与这一访问相关的所有别名值。
Java 中的静态字段不能拥有别名
分析实例字段
我们找到所有对这一实例字段(以及其别名)进行修改的 store 语句,并将这些语句要 store 的值 meet 之后赋给 L 等号左侧的变量。
那么别名信息是怎么计算的呢?
对任意两个实例字段的访问(设为
x.f和y.f),如果它们的 base 变量的指针集(points-to set)有交集(即x和y的指针集有交集),那么我们认为对这两个实例字段的访问(x.f和y.f)互为别名分析静态字段
当处理一个静态字段的 load 语句时(假设为
x = T.f;),你只需要找到对同一个字段(T.f)的 store 语句,并将这些保存进字段的值进行 meet 后赋给 load 语句等号左侧的变量(x)分析数组
与之前处理实例字段的方式类似。
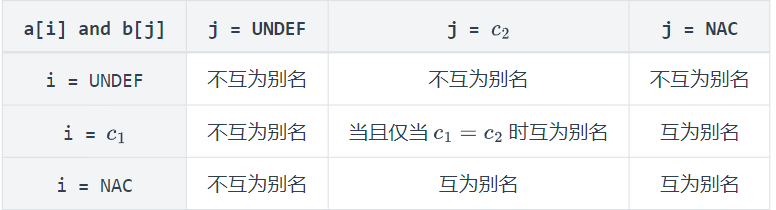
当你判断两个对数组的访问
a[i]和b[j]是否互为别名时,你不仅需要考虑它们的 base 变量(a和b)的指针集是否有交集,还需要考虑索引值i和j的关系。索引关系也可以通过常量分析来得到
特别说明:在 Java 中,和局部变量不同,字段(包括实例字段和静态字段)和数组即使没有被显式地初始化过也能被 load,这是因为 Java 会隐式地给
int类型赋初始值为 0这样会导致所有对字段和数组的处理都将无意义,因为load的值由于meet操作全变成了NAC(一旦有显示的store情况出现),因此需要作出假设:假设所有程序中的字段和数组都在被 load 之前通过 store 语句显式地初始化了,忽略隐式初始化带来的影响
需要了解的类
pascal.taie.analysis.pta.PointerAnalysisResult
提供了一系列查询指针分析结果的 API
pascal.taie.ir.exp.ArrayAccess
数组访问表达式
该类的实例在类
StoreArray和LoadArray的实例中出现
实验
更加精确地处理实例字段、静态字段和数组
我们实际上需要做的工作,首先就是维护一个别名关系。对于实例而言,当进行load/store操作时,先查找到其所有与对象关联的别名变量,进而收集所有的store/load语句,再运用meet操作计算最终的常量值。如何查找关联别名变量,就需要利用指针分析结果,这里利用到了Java中的一个特殊数据结构collection:
MultiMap,该map支持相同的重复的键,便于我们通过一个变量查找到所有关联的别名变量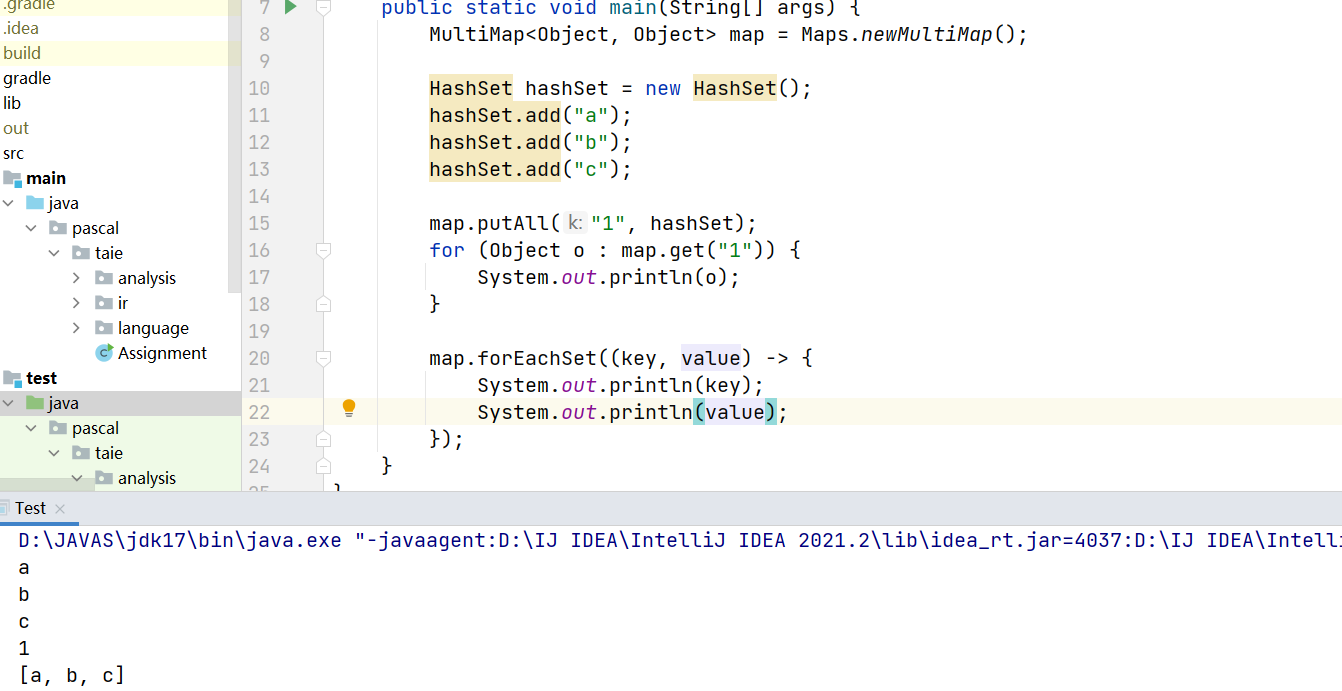
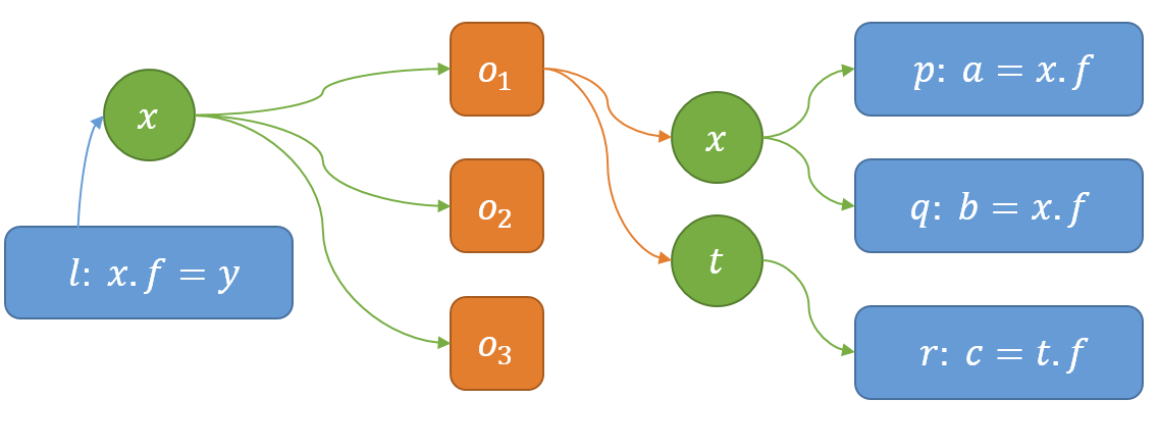
对于常数传播,我们实际上只需额外的考虑实例/静态的load/store和数组的load/array即可,其他情况均与之前的一样。对于实例变量,我们需要找到关联的别名变量的相关语句进行meet值操作;而对于静态变量,由于其没有相关语句的关联,因此一种办法就是遍历icfg上的所有stmt,进一步判断是否为静态变量
这里也需要针对store语句说明一下,因为一条语句的set操作需要同样对其关联的所有别名变量也作set操作

对于store语句,则需要把所有的别名的load加入到worklist中再次进行更新。这是因为有时候对象的field是通过getter和setter更新的,而如果在分析时先分析了getter再分析setter就会出现setter中赋的值在getter中拿不到的问题,所以setter更新时将别名的所有load语句加入worklist,就和输出变化后将后继节点加入更新传递一样
15 - CFL-Reachability and IFDS
如何用图可达的方式来表示程序分析?
我们希望尽可能误报少,也就是污点数据仅可能的少流动。尽可能的避免不合理的路径出现,但是如何避免呢?
Realizable Paths: 通过上下文敏感指针分析识别?

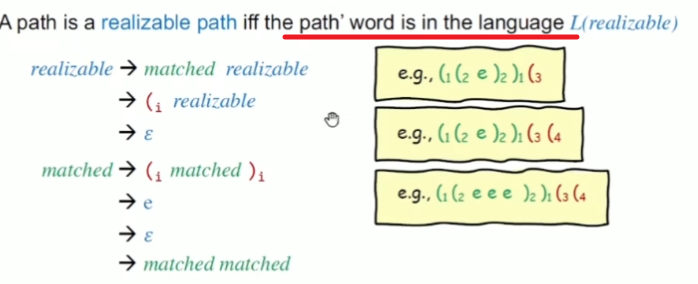
一种简单的识别方式利用括号匹配
系统的识别方式:CFL-Reachability

只要A和B之间有边构成,且各个边上的label构成的单词必须是规定的合法单词(上下文无关文法产生的单词)
context-free grammer (CFG)

通过CFL实现部分括号匹配问题
可以有左括号但是没有括号的情况,代表有call但没return

exp
IFDS
直接把程序分析过程用图可达性来表达,而没有按照之前传播的方式
IFDS满足在有限域上,且flow functions 要求是distributive的(类似分配律?)

meet-over-all-realizable-paths(MRP)
只对realizable paths 应用path function
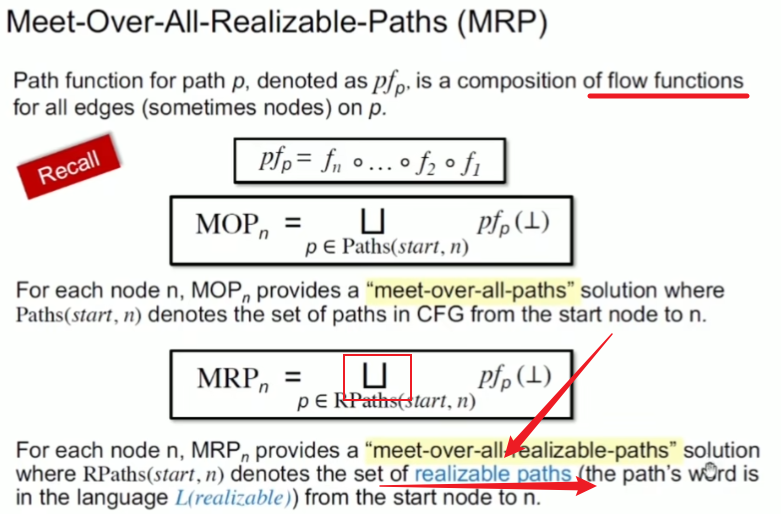
IFDS大致轮廓
前提

将superGraph分解,在其上遍历通过Tabulation algorithm来解决问题
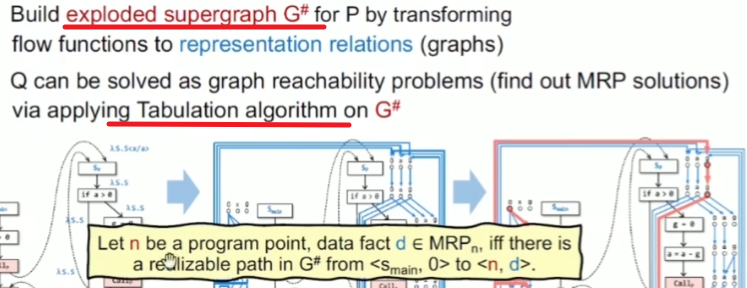
实现目标
Supergraph 里面存在的特征元素
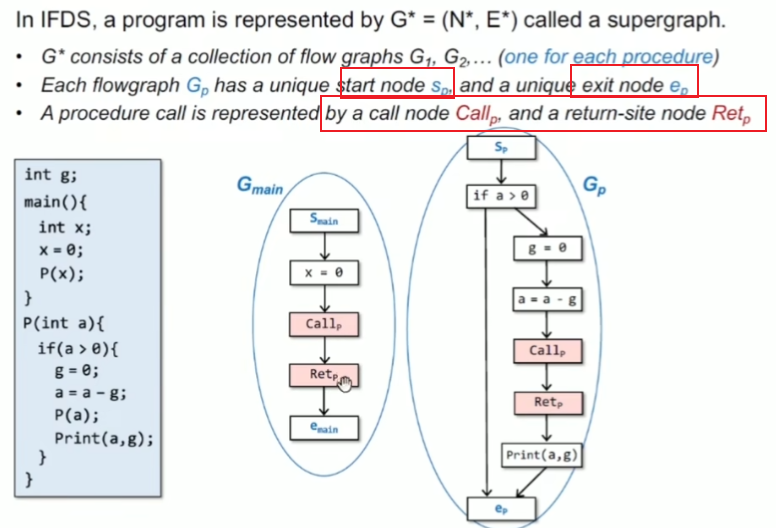
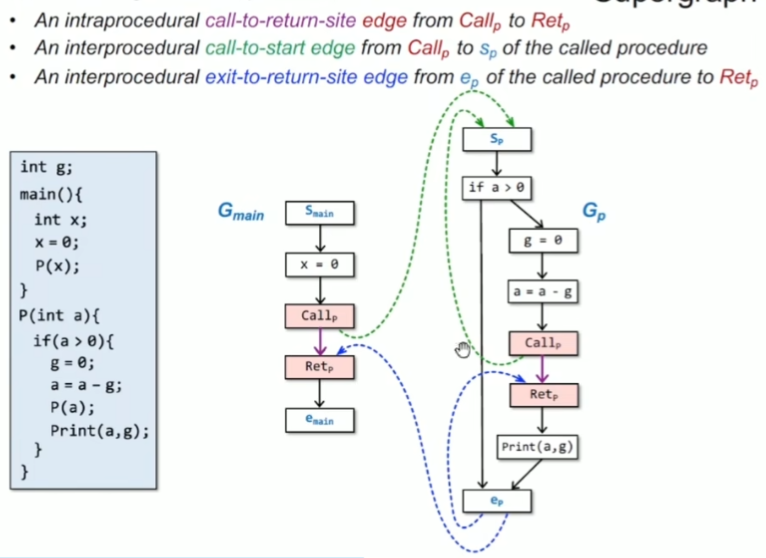
三类特殊的边 call-to-return-site call-to-start exit-to-return-site
设计 flow functions
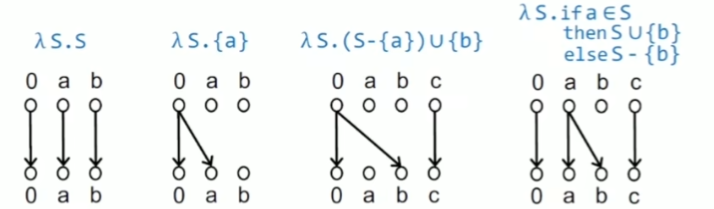
lambda expression

找出程序中哪些变量还没有被初始化
括号中输出值为未初始化变量
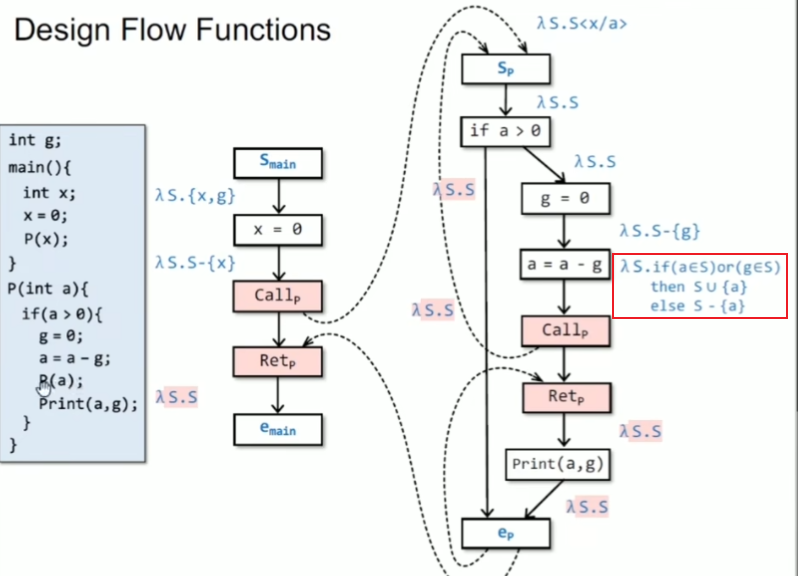
call与ret之间的边要有kill操作,为了精度提高的问题(实际上call-ret是没有这条边的),g有无真正初始化取决于右边的cfg
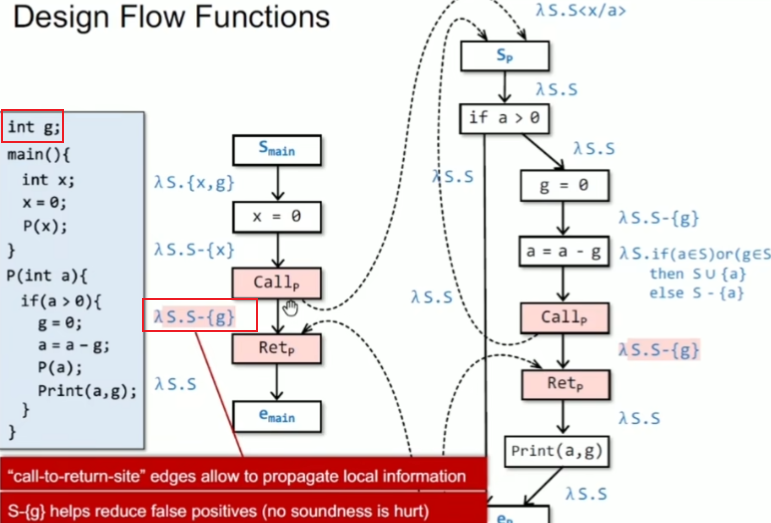
返回边把形参kill掉,符合作用域生命周期
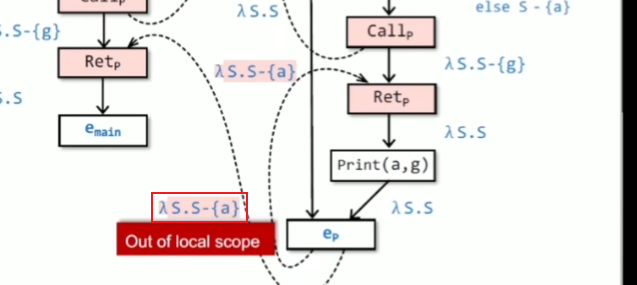
如何分解supergraph,通过flow functions转换成representation relations,fact中要加个0并复制一倍,边的条数为 $(D+1)^2$

flow function转化成一种映射关系

最后两个关系表示 如果有非0 node到y的边,那么就不存在0到y的边

为什么需要0边?
data facts的真正传播是通过一系列flow function调用起来的;对于IFDS,0到0的边实际上就是将一个个representation relation(flow functions)连接起来,这样才能表达出来图的可达性

下面开始构建分解的flow graph,实际上就是flow function到representation relation的映射表示
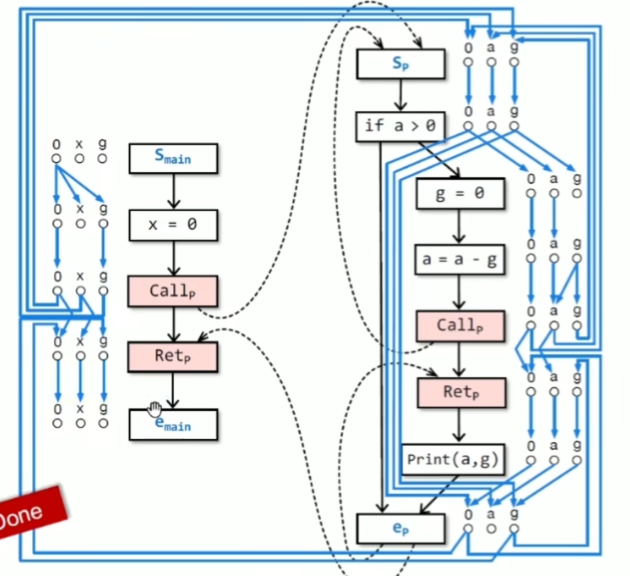
如果能够reach到最后的结点g,则是可达的
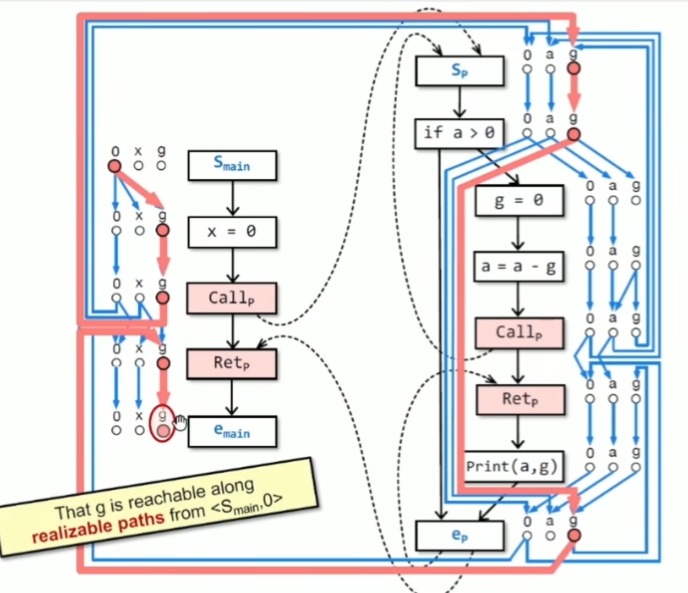
怎么样把最终的可达性结点找出来呢?Tabulation algorithm
定义

算法的核心工作机理
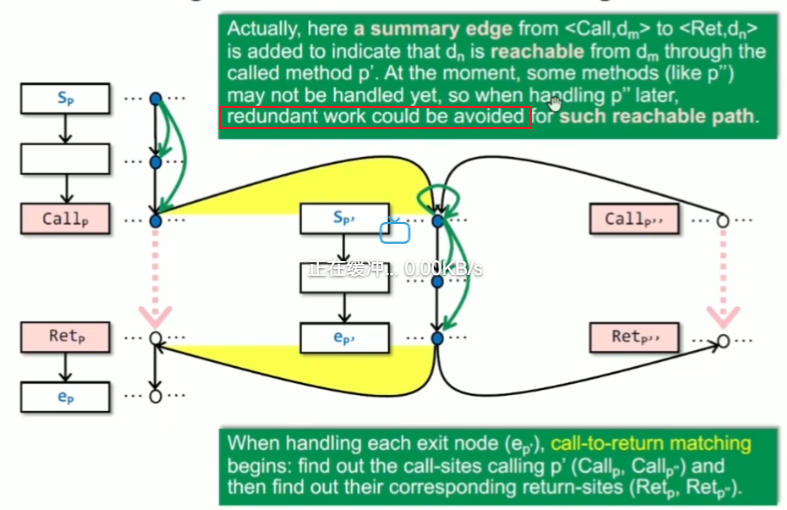
如果只关注一个 data fact,就是一点点去探索可达边,并标记可达结点。对于call边,先标记入口方法的结点 data fact,当在处理每个程序的 exit node时,开始进行括号匹配(call-to-return 匹配)。其中还会加一个summary edge,表示到 call 到 ret也是间接可达的,因为其中可能还有其他call方法未处理(相同的调用过程),这时就可以直接通过summary edge连接上就可以,减少重复的处理过程
如何理解IFDS的distributivity,也就是什么样的程序可以用它来分析?
IFD的分析框架是一次处理一个数据,等所有数据处理完之后再作meet处理

因此如何判断是否可以使用IFDS来解决,取决于问题是否需要考虑多个输入才能产出一个输出,也就是输入之间是否独立

对于指针分析,由于为了满足sound条件,需要考虑别名传播的话则需要多重输入同时关联,也就不满足IFDS独立性要求

作业8 污点分析
实现污点分析
taint sources:特定的方法(通常是产生数据的 API)
taint sinks:特定方法的某些参数

Sources 二元组 $
我们用 $t_l^u$ 来表示一个污点对象,其中 u 是这个对象的类型,l 表示创建这个对象的调用点(call site)。你只需要使用空上下文作为污点对象的堆上下文(heap context)
什么是污点传播?
污点分析中的污点是一个更加抽象的概念——它与数据的内容相关联,因此它可以在不同的对象之间传播
污点传播过程碰到各种API该如何处理其语义?
告诉污点分析哪些方法会引发污点传播以及它们是如何传播污点的
有三种污点传播的模式:

- Base-to-result:如果
receiver object(由base指向)被污染了,那么该方法调用的返回值也会被污染。StringBuilder.toString()是这样一类方法。 - Arg-to-base:如果某个特定的参数被污染了,那么
receiver object(由base指向)也会被污染。StringBuilder.append(String)是这样一类方法。 - Arg-to-result:如果某个特定的参数被污染了,那么该方法调用的返回值也会被污染。
String.concat(String)是这样一类方法。
静态方法由于没有base变量,所以不会引起 base-to-result 和 arg-to-base 的污点传播;此外,一些方法会引起多种污点传播,例如返回值中同时包含了参数和 receiver object 的内容的情况
TaintTransfers
由四元组 $

污点分析规则:

- Base-to-result:如果
需要了解的类
pascal.taie.analysis.pta.plugin.taint.Source
表示 sources
pascal.taie.analysis.pta.plugin.taint.Sink
表示 sinks
pascal.taie.analysis.pta.plugin.taint.TaintTransfer
在这个类中,我们用整数来表示污点传播被对应方法引发时的 from 变量和 to 变量。具体来说,一个大于等于 0 的整数 i 表示调用点上被调用方法的第 i 个参数;-1 表示 base 变量;-2 表示接收结果的变量
pascal.taie.analysis.pta.plugin.taint.TaintConfig
解析配置文件以及获取 sources、sinks 和污点传播信息的 API
pascal.taie.analysis.pta.plugin.taint.TaintManager
管理污点分析中的污点对象
pascal.taie.analysis.pta.plugin.taint.TaintFlow
分析算法检测到的 taint flows(由 source 的调用点和 sink 的调用点组成),也就是污点分析算法的结果
pascal.taie.analysis.pta.plugin.taint.TaintAnalysiss
本次实验的关键在于在什么地方处理source sinks 和transfer规则。sinks好说,因为它依赖于最终指针分析的结果,我需要去遍历所有callsite提取出所有invoke方法,然后判断配置文件sinks方法中的污点参数是否出现在callsite参数当中
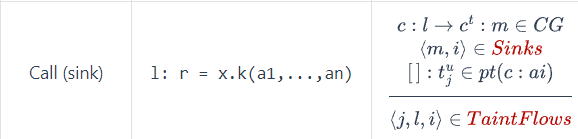
对于source和transfer的处理,我们只需关注所有invoke语句即可,source本质是从方法中产生污点对象。我们需要考虑静态调用和实例调用两种情况。这里细节就在source的处理是在出现新的调用边加入到edge时进行的判断,而transfer只要污点对象发生变化时,我就需要对其进行处理将变化的值加入到worklist当中随指针分析进行传播。污点对象的变化分为参数和base两种情况,对于base的处理是在process call当中,对于参数的变化需要自己去加

16 - Soundness and Soundiness
Hard Language Features for Static Analysis

这样会导致由于对某些hard language features不分析而对分析结果产生很大影响
Soundiness
直觉上是sound但是没有证据支撑

well-identified 清楚的挑出来并说明是如何处理的
Java Reflection

如何去分析反射?
String Constant analysis + Pointer Analysis
但是如果字符串无法被静态解析出来的话就无法处理解析
Type Inference + String analysis + Pointer Analysis


使用的时候推导出反射的参数
结合Java语言类型系统

Native Code
JNI
JVM提供的一种工作机制,可以使得JAVA和C/C++之间进行交互
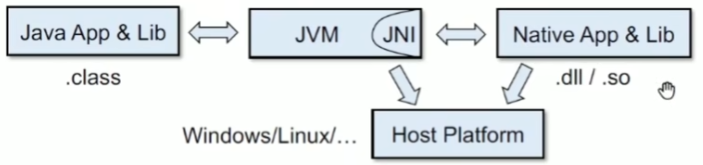
为啥难分析?
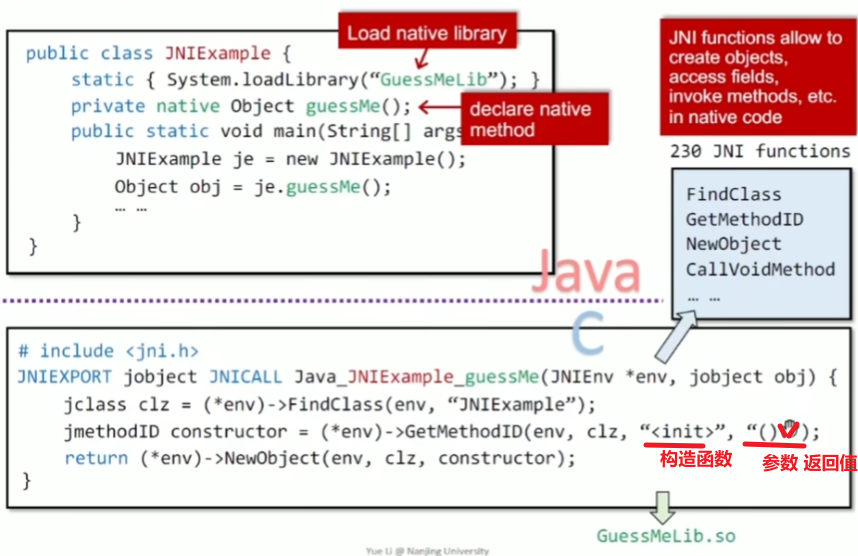
难分析点在于JAVA分析器如何去处理C代码部分
如何处理?
对关键的native code进行手动建模
exp
一种常见的建模方式

参考链接
https://github.com/RicoloveFeng/SPA-Freestyle-Guidance/blob/main/assignments
https://blog.z3ratu1.cn/%E8%BD%AF%E4%BB%B6%E5%88%86%E6%9E%90%E7%AC%94%E8%AE%B0.html
延伸

与动态分析结合

