Soot文档学习(1)
最后更新时间:
写在前面
有了静态分析基础,开始看看这个Soot,一定得实践与理论结合着来,把文档看一遍
A Survivor’s Guide to Java Program Analysis with Soot
1 Introduction
Soot研发出来的目的是为了提供一种更好、更快的理解Java程序执行的工具。
Soot主要的优势之一在于它提供了四种不同的中间表示(IR)用作分析。每一种IR都是不同水平的抽象,使得分析时带来不同方面的便利。分别是 Baf, Grimp, Jimple和Shimple
Soot构建了如下几种数据结构表示:
Scene
该类表示程序分析时涉及到的完整环境。通过它,你可以设置例如,应用类(提供给Soot用于分析的类)、主类(包含 main 方法的类)和关于过程间分析的访问信息(例如,指向信息和调用图)
SootClass
代表一个装入到Soot当中或者使用Soot创建的类
SootMethod
代表一个类中的方法
SootField
代表方法中的成员属性
Body
代表方法体。根据不同的IR表示,有不同的方法体格式
1.1 安装Soot
这里需要注意在下载soot时分为两种类型,soot-<RELEASE>-jar-with-dependencies.jar是包含了所有所需库的文件;而soot-<RELEASE>.jar仅仅包含Soot本身,需要手动选择需要分析的依赖。
1.2 Road-map to this guide(路线图)
- 内部表示 详细描述Soot中的四种中间表示
- 基本的Soot框架 简述了构成方法体的基础对象
Soot作为独立的工具 描述了如何使用Soot作为独立的工具。为此,本节介绍了Soot的内部工作原理、在命令行使用Soot及其接收的不同参数、Soot提供的一些内置分析框架以及如何使用用户自定义分析框架来扩展该工具
数据流框架 细致地描述了如何利用Soot内置数据流框架,伴随一个复杂表示分析的完整实例实现。这部分还讲述了标记Eclipse插件的代码以可视化地显示结果
调用图构建 介绍如何在整个程序分析期间获取调用图,并使用它提取各种信息
指针分析 介绍了两种高级指针分析框架 SPARK and Paddle
- 抽象控制流图的提取 描述了如何使用Soot来提取抽象控制流图的定制IR,以用作分析的起点,该分析可能受益于在抽象过程中所做的简化,如Java字符串分析
2 Basic Soot Constructs
在这一节我们描述贯穿在Soot使用当中的常用基础对象。具体来讲,我们关注那些组成方法中代码的对象。由于这些都是非常简单的构造,因此这些描述相当简短
2.1 Method bodies
Soot类Body代表一个方法体,它表示代码的风格取决于使用的IR,分别有:
- BafBody
- GrimpBody
- ShimpleBody
- JimpleBody
我们可以使用Body来访问各种信息,特别是我们可以检索局部声明(getLocals())的 Collection 类变量(Soot使用它自己的Collection实现,称为 Chain),构成方法体中的语句(getUnits())和方法体中的异常处理(getTraps())
2.2 Statements
Soot中的语句由接口Unit来表示,其中对于不同的IR存在不同的实现方式-例如,Jimple使用Stmt,而Grimp使用Inst
通过Unit类,我们可以获取到所有变量值(getUseBoxes()), 值定义的地方getDefBoxes()以及两者都取getUseAndDefBoxes(). 另外,我们可以获取跳转到当前unit的所有unit(getBoxedPointingToThis())以及当前unit要跳转到的所有unit(getUnitBoxs()). 这里的跳转指的是控制流而非顺序执行。Unit类也提供不同的方法来查询分支行为,如fallsThrough() 和 branches().
对于
getDefBoxes()的解释返回一个 valueBox 的列表,对应 unit(语句)中所有已被定义的变量
fallsThrough()如果执行可以顺利流到紧挨着的下一条语句,就会返回True
branches()如果执行可以继续流下去,但是并不会流到紧挨着的下一条语句,返回True
redirectJumpsToThisTo()改变所有曾经指向这个Unit的跳转,让他们都指向这个新的
newLocation
Values
Value表示一个数据。Value的表示可以是局部变量(Local),常量(Jimple Constant),表达式(Jimple Expr)等等. Expr 表达式又拥有不同的实现,比如BinopExpr 和 InvokeExpr,通常可视为对一个或多个值执行某些操作并返回另一个值
其中一些常用的类型:
Local
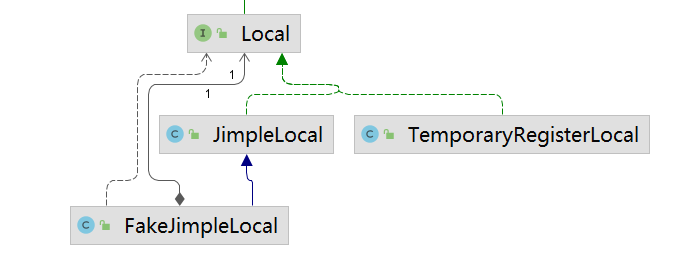
Constant
StringConstant 和 NumericConstant
stmt 与 Expr 的区别:
前者无返回值,后者有返回值
实现 stmt 接口:AbstractStmt
AbstractStmt 子类说明:
AbstractDefinitionStmt子类 1:
JAssignStmt复制语句
子类2:
JIdentityStmt显式或隐式赋值给变量
函数传参
1
r1 := @parameter0: java.lang.Stringthis 传参
1
r0 := @this: com.spring.Controller
两者区别:
AbstractSwitchStmtswitch语句主要由于JVM对于不同的Switch语句,会生成不同的操作指令
子类1:
JLookupSwitchStmt子类2:
JTableSwitchStmtAbstractOpStmt
表达式 Expr 部分
AbstractInvokeExpr调用的表达式
具体类型如下:
| 类型 | soot | 具体用途 |
| :————————— | :———————————- | :—————————————————————————————- |
| invokestatic | JStaticInvokeExpr | 调用static静态方法 |
| invokevirtual | JVirtualInvokeExpr | 调用虚方法、final方法 |
| invokeinterface | JInterfaceInvokeExpr | 调用接口方法,在运行时搜索实现了这个方法的对象,进行合适的调用 |
| invokespecial | JSpecialInvokeExpr | 调用实例方法,init构造方法、private、父类方法 |
| invokedynamic | JDynamicInvokeExpr | 动态解析出需要调用的方法,然后执行 invoke lambda |AbstractBinopExpr数学运算操作
References
当Unit包含另一个Unit的时候,需要通过Box来访问
引用在Soot中被称作 boxes,其中有两种不同的类型:
- UnitBoxes 针对Units类,当一个unit类存在多个后继时使用,比如分支语句的情况
- ValueBoxes 针对Values类,如前所述,每个unit都有一个value使用和定义的标识,当替换成use或者def boxes在units中将会很有用,比如在执行常量传播时
3 Intermediate Representations
Soot框架为代码提供了四种中间表示形式:Baf, Jimple, Shimple和Grimp. 这些表示针对不同的用途为代码提供了不同的抽象级别. 比如,baf是一种字节码标识,类似Java字节码;而Jimple是一个无堆栈的、类型化的3地址代码,适用于大多数分析。这节详细描述一下Jimple表示,简述一下其他几种
3.1 Baf
Baf是一种基于堆栈的线性字节码表示。用于将Java字节码作为堆栈代码进行检查,但将常量池抽象出来,并将指令的类型相关变体抽象为单个指令(例如,在Java字节码中,有许多用于添加整数、长整数等的指令,在Baf中,它们都被抽象为单个加法指令)。Baf中的指令对应Soot的Units类,因此所有指令的实现都实现了Inst接口,后者又实现了Unit和Switchable接口。
Baf表示的实现存放在soot.baf和soot.baf.internal包中。
Baf对于基于字节码的分析、优化和转换(如peephole)非常有用
作为基于Baf表示的Soot框架的一部分提供的优化可以在soot.baf.toolkits.base包中找到
3.2 Jimple
Jimple是Soot中的主要表示。其是类型化的、3地址码的、基于语句的中间表示。
Jimple表示可以直接由Soot创建,或者基于Java源代码、字节码或者class文件创建。
从字节码到Jimple的转换通过从字节码到无类型Jimple的naive转换,具体通过为隐式堆栈位置引入新的局部变量并使用子例程移除JSR指令。从无类型的Jimple当中推断出局部变量的类型并添加进来。其还会清除Jimple代码中的冗余代码,如未使用的变量或赋值。转换到Jimple的一个重要步骤是表达式的线性化(和命名),使得一个语句最多只能引用3个局部变量或常数。从而为执行优化提供了更规则、更方便的表示。在Jimple表示下,分析只需要处理15种语句,而Java字节码中可能有200多种指令。
在Jimple中,语句对应Soot中的Units类并且可以如此使用。其拥有15种语句,核心的有:NopStmt, IdentityStmt 和 AssignStmt。过程内控制流语句有IfStmt, GotoStmt, TableSwitchStmt(对应JVM的tableswitch指令) 和 LookupSwitchStmt(对应JVM的lookupswitch指令). 过程间分析语句有InvokeStmt, ReturnStmt,ReturnVoidStmt. 监控语句有EnterMonitorStmt 和 ExitMonitorStmt,最后两个是ThrowStmt 和 RetStmt(从JSR中返回,如果是从字节码中生成Jimple语句则不创建)
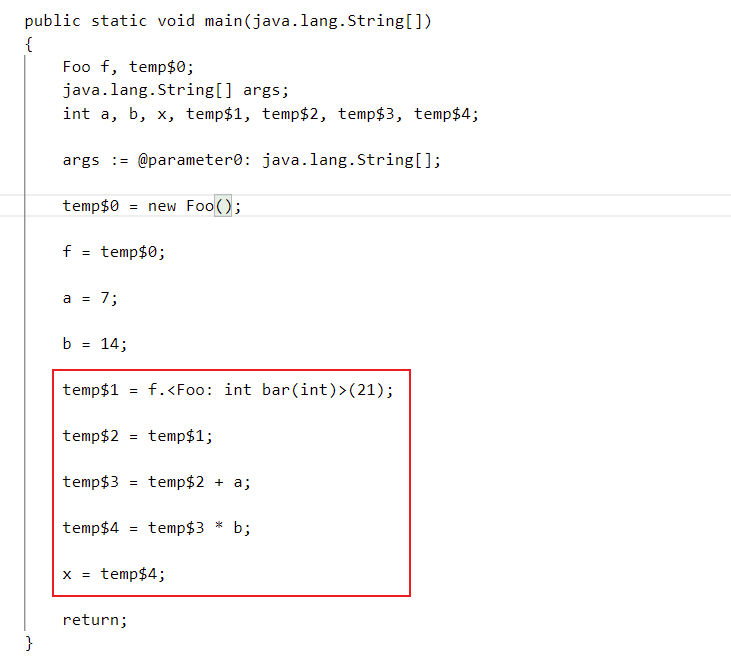
将下面的例子生成Jimple语句
1 | |
执行下列命令用于生成Jimple文件
1 | |
Jimple文件如下
1 | |
上述代码片段为main和bar方法生成的Jimple语句。Jimple是Java源代码和Java字节码的混合体。Jimple中拥有类似Java的语句结构那样的局部变量的声明和赋值,但是对于控制流和方法调用,风格又和Java字节码类似。以的变量表示真实的局部变量。
线性化过程将语句int x = (f.bar(21) + a) * b分解成三地址码的形式temp$3 = temp$2 + a;
temp$4 = temp$3 * b;
在Jimple中,参数值和this引用使用IdentityStmt进行赋值,例如bar方法中的语句n := @parameter0: int;以及this := @this: Foo; 。通过使用IdentityStmt,确保所有局部变量至少有一个定义点,因此this变量在哪里被定义就很清晰了。
所有局部变量都是类型化的。在分析过程中使用类型信息很有帮助
请注意,Jimple不是Java源代码,特别是当您将Java源代码与生成的Jimple代码进行比较时,引入新的唯一变量可能会导致结果与预期之间的巨大差异
Jimple中间表示在以下依赖中提供soot.jimple和soot.jimple.internal,在soot.jimple.toolkits.*特别是 soot.jimple.toolkits.scalar和soot.jimple.-
toolkits.annotation.*中有很多优化的集合类可以使用
3.3 Shimple
Shimple中间表示是Jimple表示的静态单赋值形式,SSA-form保证每个局部变量都有一个静态定义点,这大大简化了许多分析。
除了单静态定义点和所谓的phi-nodes比较特殊,其他形式均与Jimple一样,因此两者几乎可以同等对待
下面实例类
1 | |
利用下面的指令生成Shimple文件
1 | |
(我自己生成的更复杂,先看paper上的样例)
1 | |
相比于Jimple结构,这里有两点不同。新引入的Phi-node以及i0变量被拆分成了4个变量i0,i0_1,i0_2,i0_3
在SSA形式下,i0_1的值依赖于控制流图中涉及的路径,其与Phi-nodes相关。该值可能来自(0)、(1)或(2)。Phi-node可以被看作是一个函数,如果流从(0)到达则返回i0的值,如果流从(1)到达则返回i0_2的值,或者如果流从(2)到达则返回i0_3的值。
Simple对控制流进行了显式编码,因此可以方便地对Simple代码进行控制流敏感分析
实际上,在上面的示例中x是常量,因此test方法可以是常量传播并合并到单个return语句中,大多数控制结构都是不必要的
为了说明Shimple和Jimple表示之间的差异,我们基于每种表示优化程序并比较结果
Soot提供这样一种优化参数 -O

在这里将会运行常量传播并作合并处理
1 | |
基于Jimple处理的结果如下
1 | |
这与我们之前看到的输出完全相同,即运行未经优化的Soot时的输出!基于Jimple表示,优化不能推导出x是常数
利用Shimple进行分析
1 | |
基于Shimple的结果如下
1 | |

这与预期一致。因为成员变量as_long_as_it_takes非静态的,因此还是得保留while循环,但是优化器推断出了x是个常量,因此phi-node在三个相同的值之间作了选择并且优化掉了。
结论:Shimple显式地暴露了控制结构,并且变量只有静态的单个赋值
Shimple中间表示可在依赖 soot.shimple / soot.shimple.internal,并且soot.shimple.
toolkits.scalar可以获得constant-folder(常量合并这个功能?)
3.4 Grimp
Grimp类似于Jimple,但允许表达式树与New操作符一起使用。在这方面,Grimp比Jimple更接近于Java源代码,因此更容易阅读,因此是人类读者检查反汇编代码的最佳中间表示
下面用指令运行一下Foo类的例子生成Grimp中间表示
1 | |
结果如下:

这两个main方法之间(Jimple 和 Grimple生成的)有三个非常明显的区别
- 表达式树未线性化
- 对象实例化和构造函数调用合并为new操作符
- 由于表达式树不是线性化的,所以不会创建新的临时局部变量(以$开头的局部变量),但是我们确实需要新的临时局部变量例如在while中
Grimple表示适用于某些类型的分析,如available expressions(如果既需要复杂表达式,也需要简单表达式)。Grimp也是一个很好的反编译起点
Grimple中间表示位于依赖soot.grimp / soot.grimp.internal,一些优化可以在soot.grimp.toolkits.base中得到
4 Soot as a stand-alone tool
完整内容可在 https://github.com/soot-oss/soot/wiki/Tutorials
Soot可以作为一个独立的工具用于许多不同的目的,例如对代码做一些内置分析或转化。本节将介绍如何将Soot用作独立工具、如何根据其用途对选项进行分组,并详细介绍一些最常用的选项
如果类路径中包含Soot,则可以按如下所示从命令行调用Soot
1 | |
其中[sootOptions]表示Soot接受的各种选项,classname表示待分析的类
获取Soot支持的选项列表:
1 | |
类划分:在Soot中,我们区分三种类:参数类、应用程序类和库类
参数类是指定给Soot的类。使用命令行工具时,这些类是显式列出的类(直接给出的),也可以是在-process-dir选项指定的目录下的类
应用程序类是要由Soot分析或转换并转换为输出的类
库类相当于应用程序中所要依赖的类,会被用于分析和转换但本身不会转换输出
还有两种模式会影响类的分类方式:应用模式和非应用模式
在应用程序模式下,参数类引用的所有类除了JRK中的一些类之外本身也都是应用程序类。在非应用程序模式下,这些类将是库类
Soot提供了更多选项来偏向哪些类是应用程序模式下的应用程序类
1 | |
4.1 Soot phases
Soot的执行分为几个阶段,称为 packs。第一步是生成Jimple代码,然后分配到不同包中,这是通过解析类、jimple或java文件,然后将其结果传递给 jimpleBody(jb)包来完成的。
包的命名格式很简单,第一个字母表示包接受哪个IR表示,比如s代表Shimple,j代表Jimple,b代表Baf,以及g代表Grimp。第二个字母指定包的职责,B用于方法体创建,t用于用户定义的转换,o用于优化,a用于属性生成(注释),包名结尾的p代表“包” 。
允许用户定义转换的包如jtp(Jimple转换包)和stp(Shimple转环包)比较特殊。任何用户定义的转换(例如,来自分析的标记信息)都可以注入到这些包中,然后它们将包含在Soot的执行中
包的执行流图如下所示:(程序内分析)
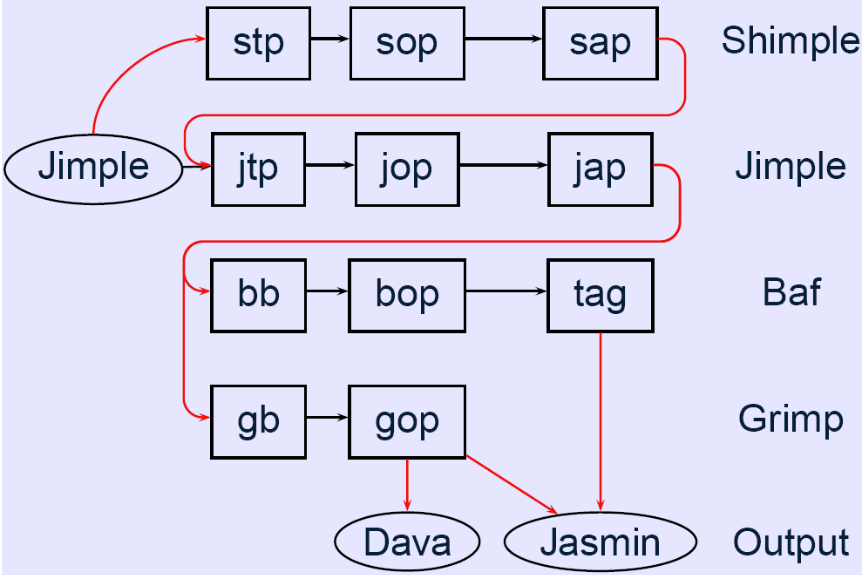
每个应用程序类都通过此执行流中的路径进行处理,但它们无权访问处理其他应用程序类时生成的任何信息
注意这里的 t 类似插件的作用,可以在其中执行自定义的转换
1 | |
程序间分析:对于过程间分析,执行流稍有不同。我们需要通过指定选项 -w 将Soot设置为Whole-program模式。在此模式下,Soot在执行周期中将包含三个其他程序包:cg(调用图生成)、wjtp(完整Jimple转换包)和wjap(完成Jimple注释包)。此外,为了添加整个程序优化(例如静态内联)功能,我们指定选项 -W 进一步向包中添加 wjop(完整Jimple优化包)。这些包与程序内分析使用的包之间的区别在于,这些包中生成的信息可通过Scene 供Soot的其余部分使用
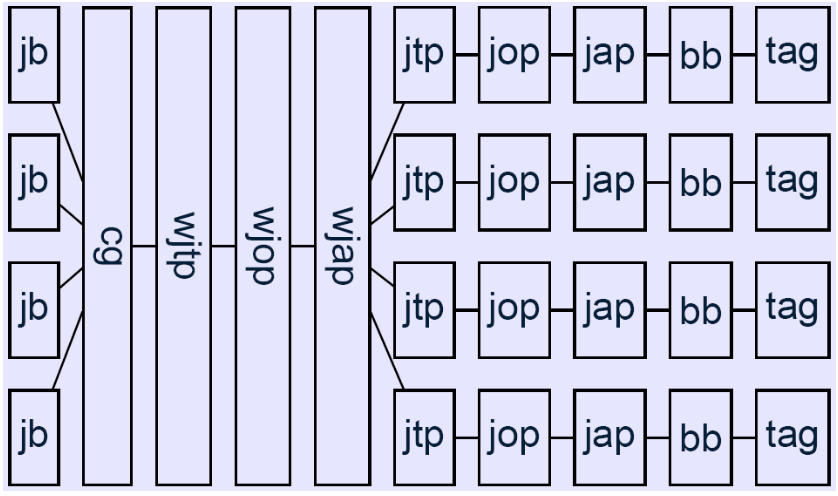
Phase options:
要生成Soot中所有可用包的列表,请执行以下命令
1 | |
此信息可用于获取有关不同包及其包含的操作(例如,内置分析)可用选项
要列出包的帮助信息和可用选项,可用
1 | |
要为包设置选项,需要指定-p选项,后接包名和OPT:VAL形式的键值对。OPT是想设置的选项,VAL是对应的值。
4.2 Off-The-Shelf Analysis
Soot包括几个示例分析来演示其功能
Null Pointer Analysis:内置的空指针分析位于jap包中,并进一步分为两个单独的实体:空指针检查器和空指针着色器。前者查找有可能抛出NullPointerException的指令,而后者使用该信息为Eclipse插件添加标记信息,要运行空指针着色器以在程序中生成空值的可视化效果,可以:
1 | |
这将产生一个Jimple文件,当在Eclipse中查看此文件时,引用类型将根据其是否为null进行颜色编码(绿色表示肯定不为空,蓝色表示未知,红色表示肯定为空)
Array Bounds Analysis:内置分析的另一个很好的例子是数组边界检查器,分析器会去检查数组是否越界。这种分析可以使编译器通过不在字节码中插入显式数组边界检查来达到优化效果。此分析也位于jap.abc下的jap包中。运行它以生成可视化效果的最简单方法是
1 | |
分析结果说明了对于上界和下界,是否存在不安全的访问
Liveness Analysis:内置的活动性分析会对语句中确定存在的变量进行着色。它只有一个选项,即是否启用
1 | |
结果指出了语句中的所有活跃变量
4.3 Extending Soot’s Main class
设计和实现一个分析后,我们还希望能够从Soot中配合其他特征(比如内置分析)来使用。为此,我们需要扩展Soot的Main类以包含我们自己的分析。请注意,这不是Java意义上的扩展,而是一个中间步骤的注入,在这个步骤中,我们的分析被放入Soot。换句话说,我们希望Soot运行我们的分析,并且仍然处理我们传递给它的所有其他选项。
如何完成取决于注入的分析是否为程序间分析或程序内分析。前者需要注入到wjtp阶段,而后者进入jtp阶段。下面的代码示例演示如何将类MyAnalysisTagger(执行某些过程内分析)的实例注入到Soot中。

5 The Data-Flow Framework
一般来说,我们可以将流分析设计为四个步骤:
- 确定分析的性质。它是一个前向还是后向分析?我们是否需要特别考虑分支?
- 确定预期的approximation。这是一个may还是一个must的分析?实际上,这个在决定合并流经节点的信息时是并集还是交集
- 执行实际流,本质上是为中间表示中的每种语句编写等式,比如如何处理赋值语句
- 确定入口节点(如果是反向流,则为出口节点)和内部节点的初始状态或近似值,通常是空集empty或全集top,取决于分析的保守程度
执行数据流分析时,我们需要某种结构来表示数据如何在程序中流动,例如控制流图(cfg)。Soot数据流框架旨在处理任何形式的cfg实现接口soot.toolkits.graph.DirectedGraph
5.1 Step 1: Nature of the analysis
Soot提供了三种不同的分析实现:ForwardFlowAnalysis, BackwardFlowAnalysis 和ForwardBranchedFlowAnalysis。前两个图除了流向不同外都是相同的,其结果是两个maps:节点到IN集合以及节点到OUT集合。最后一个分析实现提供通过分支节点的每个分支传播不同信息的能力,比如:从包含语句if(x>0)的结点流出的信息,可以是x>0到一个分支或者$x\leq 0$到另一个分支。因此,该分析的结果是三个maps:节点到IN集合、节点到满足fallthrough 的OUT集合以及节点到分支OUT集合。所有这些的实现基于了不动点原理的worklist算法。如果您想以其他方式实现它,可以扩展其中一个抽象超类:AbstractFlowAnalysis (the top one), FlowAnalysis或BranchedFlowAnalysis,否则,将特定分析插入框架的方法是扩展前三个类中的一个
对于上述非常复杂的表达式的例子,我们需要使用反向分析,因此我们的类签名将是:
1 | |
现在,为了利用框架的功能,我们需要提供一个构造函数。在这个构造函数中,我们需要做两件事:
- 调用父类构造函数
- 调用不动点机制实现分析

5.2 Step 2: Approximation level
分析的approximation程度取决于分析如何执行lattice元素的JOINs操作。通常分析要么是may analysis,要么是must analysis.。在may分析中,我们使用union连接元素,而在must分析中,我们使用intersection连接元素。在流分析框架中,连接是在merge方法中执行的。在非常复杂的表达式分析例子是must analysis,因此我们使用交集来连接:

从这里可以看出,流分析框架被设计成具有这样的抽象,即它不关心如何表示格。这个例子中我们使用了FlowSet类。由于这种抽象,我们还需要提供一种将一个lattice的内容复制到另一个lattice的方法

5.3 Step 3: Performing flow
这是分析的真实工作发生的地方,信息通过cfg中的节点流动。所涉及的框架方法是flowThrough,我们可以将此过程视为包含两个部分:
我们需要将信息从IN集合复制到OUT集合,同时排除掉节点删除的信息
我们需要向节点生成的OUT集合添加信息

在表达式复杂的例子中,节点将删除那些引用的已经被定义过的表达式

kill和gen方法不是框架的一部分,而是用户定义的方法。
5.4 Step 4: Initial state
这一步包括决定入口点的lattice元素和其他lattice元素的初始内容,在流分析框架中,这是通过重写两个方法来实现的:entryInitialFlow 和newInitialFlow。对于复杂表达式分析的例子,入口点是最后一条语句(出口点),我们用空集初始化。至于其他格点,我们也用空集初始化。

这里注意ValueArraySparseSet的构造是我们自己对于ArraySparseSet类的特殊化实现。
5.5 Limitations
对于像复杂表达式分析这样的例子,我们需要记住实际分析的是什么。在我们的例子中,我们正在分析Jimple代码,作为一个三地址代码,复合表达式将被分解为中间部分(比如 a+b+c将变为temp = a+b以及temp + c)。这使我们认识到,我们的特定分析如果没有修改,只能分析原始源代码中可能表达式的一小部分。在这种特殊情况下,我们可以分析Grimp代码,并特别考虑复合表达式。
5.6 Flow sets
在 Soot中,flow sets (tai-e中叫 data-sets) 表示在控制流图中结点关联的数据(比如对于活跃表达式来说,结点的flow set就是一系列活跃的表达式)
flow set有两种不同的概念,有界(BoundedFlowSet接口)和无界(FlowSet接口),有界set是一个知道其可能值的全域的集合,无界set相反
实现FlowSet接口的类需要实现以下方法(以及其他方法):

这些操作足以使流集合成为有效的格元素。
另外当实现BoundedFlowSet时,需要提供生成该集合的补集以及top集
Soot提供了四种flow sets的四种实现:ArraySparseSet, ArrayPackedSet ,ToppedSet和DavaFlowSet。
ArraySparseSet 是一个无界flow set,集合表示为引用数组。请注意,在比较元素是否相等时,它使用从Object继承的方法equals。这里的问题是soot元素(表示某些代码结构)不会重写此方法,相反,它们实现了接口soot.EquivTo。因此,如果您需要一个包含例如二元运算表达式的流集,您应该使用equivTo方法来比较是否相等
ArrayPackedSet 是一个有界flow set,这里要求提供FlowUniverse对象,其只是某种集合或数组的包装,并且它应该包含可以放入集合中的所有可能值。集合由整数和对象之间的双向映射表示,以及指示全域的哪些元素包含在该集合内的位向量(如果设置了索引0处的位,则该集合包含整数0在映射中的元素)。这个实现同样也有ArraySparseSet关于元素相等的限制
ToppedSet:包装另一个流集合(有界或无界),添加关于它是否是格的top集合的信息
在我们活跃表达式示例中,我们需要包含表达式的流集合,因此我们希望比较它们的等价性。a + B的两次不同出现将是实现BinopExpr接口的某个类的不同实例化,因此它们永远不会相等。为了解决这个问题,我们使用ArraySparseSet的修改版本,其中我们更改了contains方法的实现:

5.7 Control flow graphs
Soot在soot.toolkits.graph包中提供了几种不同的控制流图(CFG)。这些图的基础是接口 DirectedGraph。它定义了用于获取以下内容的方法:图的入口点和出口点、给定节点的后继节点和前驱节点、以某种未定义的顺序迭代图的迭代器以及图的大小(节点数)
这里给出 API
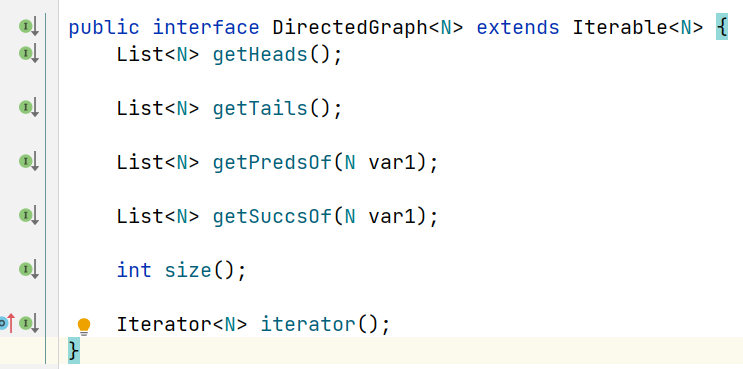
我们将在这里描述的实现是表示CFG的实现,其中节点是Soot单元。此外,我们将只描述表示过程内分析流
这类图的基类是 UnitGraph,它是提供构建CFG工具的抽象类。它有三种不同的实现方式:BriefUnitGraph, ExceptionalUnitGraph 和 TrapUnitGraph.
BriefUnitGraph 是非常简单的,因为它没有表示由于抛出异常而产生的控制流的边
ExceptionalUnitGraph 包含从throw子句到其处理程序(catch块,在Soot中称为Trap)的边,前提是 trap 是方法体中的局部变量。此外,此图还考虑了j计算语句可能隐式抛出的异常(例如ArrayIndexOutOfBoundsException). 对于每个可能抛出隐式异常的单元,从每个单元的前导到相应陷阱处理程序的第一个单元之间都有一条边。此外,如果异常单元包含副作用,则还将从异常单元向陷阱处理程序添加边(这里指的异常单元中出现异常的情况吧)。如果它没有副作用,则可以利用传递给图构造器之一的参数来选择性地添加或不添加该边,这是执行控制流分析时通常使用的CFG。
TrapUnitGraph 类似 ExceptionalUnitGraph,也需要考虑抛出的异常。这里有三个主要区别:
- 从每个 trap 单元添加边(即,在try块内)到陷阱处理程序
- 不存在可能向陷阱处理程序抛出隐式异常的单元的前趋项的边(除非它们也被陷阱捕获)
- 单元中总是有可能会向陷阱处理程序抛出隐式异常的一条边
要为给定的方法体构建CFG,只需将方法体传递给CFG构造函数之一
1 | |
5.8 Wrapping the results of the analysis
特定分析的结果可通过 AbstractFlowAnalysis#getFlowBefore 方法,FlowAnalysis#getFlowAfter方法,BranchedFlowAnalysis#getBranchFlowAfter和getFallFlowAfter方法。这些方法都只是返回表示lattice元素的对象. 为了更加稳固,通过给分析提供一个接口,屏蔽掉结果?而返回一个以lattice作为元素的不可修改的列表。
对于活跃表达式分析示例,我们选择遵循内置Soot分析中使用的约定—提供通用接口及其一种可能的实现。接口非常简单,只是提供相关数据的访问器

这个接口的实现(我们将其命名为SimpleVeryBusyExpressions)执行实际的分析,并将数据收集到它自己的maps中,内含单元映射到不可修改的表达式列表
下面实例如何手动运行活跃表达式分析:

6 Annotating code
Soot中的注释框架最初设计用于支持使用Java类文件属性优化Java程序,其思想是将信息标记到代码的相关位上,然后虚拟机可以使用这些标记来执行某些优化,比如排除不必要的数组边界检查。这个框架(位于soot.tagkit)由四个主要的概念:Hosts, Tags, Attributes 和 TagAggregators
Hosts 是可以保存和管理标记的任何对象,在 Soot中 SootClass,SootField, SootMethod, Body, Unit, Value 和 ValueBox均实现了这个接口
Tags 是可以标记到hosts的任何对象,这是将名称-值对连接到hosts的一种非常通用的机制
Attributes 是标记概念的扩展。任何属性都可以输出到类文件中,特别是任何对类、字段、方法或主体的标记都应该实现此接口。属性应该映射到类文件属性中,并且因为Soot使用一个名为Jasmin的工具来输出字节码,所以任何应该输出到类文件的内容都必须继承JasminAttribute,Soot中的一个此类实现是CodeAttribute
TagAggregators 是BodyTransformers(参见第6.1节),它收集某种类型的标记,并生成一个新的属性以输出到类文件。聚合器必须决定在哪里标记相关信息—例如,一个单元可能被转换成几个字节码指令,因此聚合器必须决定该单元上的注释应该引用哪一个。Soot为其内置标记提供了几个聚合器—比如FirstTagAggregator将标记与用其标记的第一条指令相关联. 一般来说,如果我们只使用内置标签,就不需要关注聚合器
6.1 Transformers
Transformers实际上并不是标记框架的一部分,但用于注释代码。一般来说,Transformers是将某个代码块转换为另一个代码块的对象。在Soot中有两种不同的Transformers:BodyTransformers 和 SceneTransformer 。它们被分别设计为在单个方法体上(即过程内)和整个应用(即过程间)作transformations。要实现一个transformer,需要继承其中一个上述的Transformers并提供internalTransform方法的实现
一个示例:
1 | |
6.2 Annotating very-busy expressions
让我们看看如何使用这种标记机制将运行活跃表达式分析的结果可视化地传达给用户。由于我们的示例是过程内分析,为了使用结果标记代码,我们继承BodyTransformer并实现了它的internalTransform方法。我们要做的就是为每个流出活跃表达式的单元作StringTags标记。此外,我们还希望对持续保持活跃的表达式作ColorTag标记。有了这些信息,用户可以很容易地看到活跃表达式通过他的方法,并快速识别到哪里可以优化。此过程的伪代码如下所示(有关完整详细信息,请参阅示例源代码):

为了将分析插入到Soot中,我们重写Soot的Main类,将我们的标签插入到Jimple转换包中(如第4节所述)。
7 Call Graph Construction
CallGraph构建
前提:开启全局模式
1 | |
在执行过程间分析时,应用程序的调用图是一个基本实体. 调用图可用时(仅在whole-program 模式),它可以通过环境类(Scene)使用getCallGraph方法进行访问。CallGraph类和其他相关的构造类位于soot.jimple.toolkits.callgraph包中。最简单的调用图是通过 类层次分析(CHA)获得的,不需要进行设置。CHA很简单,因为它假设所有引用变量都可以指向正确类型的对象。以下是使用CHA获取调用图的示例:

7.1 Call Graph Representation
Soot中的调用图是表示所有已知方法调用边的集合,这里包括:
- 显式方法调用
- 静态初始值的隐式调用
Thread.run()的隐式调用- 常量类对象的隐式调用
- AccessController的隐式调用
调用图中的每条边包含四个元素:源方法、源语句(如果适用)、目标方法和边的类型。不同种类的边例如用于静态调用、虚拟调用和接口调用。
调用图具有查询进入函数边的方法,出函数边的方法以及来自特定语句的边的方法(分别对应edgesInto(method), edgesOutOf(method), edgesOutOf(statement))。每一种方法都返回一个基于构建边的迭代器。Soot提供了三个所谓的适配器,用于在边的特定位置上迭代:
Sources 迭代源方法边
Units 迭代源语句边
Targets 迭代目标方法边
因此,为了遍历特定方法的所有可能调用它的方法,可以:

7.2 More specific information
Soot还提供了另外两种构建,以更详细的方式查询调用图:ReachableMethods和TransitiveTargets
- ReachableMethods:此对象跟踪哪些方法可从入口点访问,其中
contains(method)测试指定方法是否可达,listener()方法返回一个迭代器遍历所有可访问的方法 - TransitiveTargets:对于迭代所有从特定方法调用的函数或者其调用的其他函数(遍历调用链)是很有用的,构造函数接收(除了调用图之外)一个可选的过滤器参数
Filter,过滤器表示调用图中满足给定EdgePredicate(一个简单接口,有两个具体实现:ExplicitEdgesPred与InstanceInvokeEdgesPred)谓词的边集合
8 Points-To Analysis
在本节中,我们将介绍在Soot中进行指针分析的两个框架:SPARK和Paddle框架
指针分析的目标是计算一个函数,该函数在给定变量的情况下返回可能的目标集,为了进行许多其它种类的分析,如别名分析,或者为了提高例如调用图的精度,从指向分析得到的集合是很有用的。
Soot提供了PointsToAnalysis和PointsToSet接口,任何指针分析都应该实现这些接口。PointsToAnalysis接口包含reachingObjects(Local l)方法,该方法将l所指向的对象集作为PointsToSet返回。PointsToSet包含用于测试与其他PointsToSet的非空交集的方法,以及一个用于返回集合中对象的所有可能运行时类型的集合的方法。这些方法对于实现别名分析和virtual method调度非常有用。当前的 points-to 集合可以通过Scene.v().getPointsToAnalysis()方法获得。至于如何创建取决于所使用的接口实现。
Soot提供了points-to接口的三种实现:CHA(dumb版本)、SPARK和Paddle。dumb版本只是假设每个变量都可能指向其他变量,这是保守合理的,但不是非常准确。然而,dump版的指针分析实现可能具有一些价值,例如创建不精确的调用图,该调用图可以用作例如指针分析的起始点,从该点分析可以构造更精确的调用图
SPARK和Paddle框架以更复杂的设置和速度为代价提供更准确的分析,这两种算法都是基于子集的,如Anderson算法,而不是基于等价的Steensgaard算法。
8.1 SPARK
SPARK是一个用于在Java中试验指向分析的框架,它支持基于子集和基于等价的指向分析,以及介于两者之间的任何分析。SPARK是非常模块化的,这使得它非常适合于对不同的技术进行基准测试,以实现指针分析的各个部分。
在本节中,我们将展示如何使用SPARK来设置和试验SPARK提供的基本指针分析。
SPARK作为Soot框架的一部分提供,位于soot.jimple.spark中。*包中。作为SPARK的一部分,提供了一个指针分析,并且可以使用选项控制分析的细节。例如,传播算法可以是一个简单的迭代算法,也可以是一个更有效的worklist算法。
Using SPARK
SPARK强大的模块性提供了一组丰富的选项,使得为任何对象设置SPARK都变得不那么容易。为了能够使用SPARK,我们建议使用Eclipse从示例源代码加载示例代码,或者创建一个新项目并将Jasmin、Polyglot和Soot jar文件添加到类路径中,在设置运行配置时,应该向JVM添加参数-Xmx512m来增加虚拟内存。
接下来介绍一下待分析的实例方法,方法用到了Container类和它的内部类Item。Container类有一个私有属性和一对get/set方法,Item类有一个object类型的私有属性data。
go方法创建了两个Container类实例,并分别设置了Item类实例属性。此外第三个Container对象声明并被第二个Container对象的引用所赋值。



我们希望在此示例上运行SPARK,并期望它发现c1的指针集不与c2或c3的指针集相交,而c2和c3应该共享相同的指针集。此外,我们期望在(1)和(2)处分配的Container对象的Item字段指向不同的对象i1和i2(上下文敏感)
要运行SPARK,我们设置Soot Scene以加载Container和Item类以及包含go方法的类。使用Scene.v().loadClassAndSupport(name); 和c.setApplicationClass();

设置SPARK的代码如下,其中我们列出了最有趣的选项,并展示了如何使用SparkTransformer类的transform方法,将选项maps作为参数来运行SPARK分析

参数信息如下:
- verbose SPARK分析时输出日志信息
- propagator SPARK支持两种指针集传播算法,一种简单的迭代算法和一种更有效的基于worklist的算法
- simple-edges-bidirectional 如果为真,此选项将使所有边双向,从而允许基于等效的指针分析,如
Steensgaard算法 - on-fly-cg 如果调用图是即时创建的,这通常给出更精确的分析点和生成的调用图
- set-impl 描述了指针集的实现,可能的值为散列、位、混合、数组和Double。散列的实现基于Java hash set。位是使用位向量实现的。Hybrid是一个集合,它保存最多16个元素的显式列表,并在集合变大时切换为位向量。数组是使用始终保持排序顺序的数组实现的。Double使用两个集合实现,一个用于尚未传播的新指向对象集合,另一个用于已传播且需要重新考虑的旧指向对象集合。
- double-set-old 和 double-set-new 描述了double实现中新的和旧的指向对象集的实现,并且
double-set-old和double-set-new仅在double是set-impl的值时有效
使用示例代码运行SPARK,得到的输出如下所示:

左列中的数字表示变量初始化点,比如[4,8] Container intersect? false 指的是在第4行初始化的变量c1和在第8行初始化的变量c2。右列说明两个变量的指向集是否有空交集(true表示有)
首先,作为一个简单的一致性检查,我们看到每个变量都有一个指针集-与自身的交集,正如预期的那样,指向变量集c1和c2以及c1和c3的指针集不相交,而c2和c3的指向集合相交。
至于item字段,我们看到所有指向集合都彼此相交,即使它们属于不同的Container对象。结果与我们的期望之间的这种不匹配的原因是我们期望中的错误。我们希望SPARK能够区分两次setItem调用,但是SPARK对上下文不敏感,因此只分析一次setItem方法,并合并每次调用setItem方法时的指向集。
SPARK是一个大而健壮的框架,用于试验上下文不敏感指向分析的许多不同方面。我们只介绍了许多选项中的一小部分,还有更多的组合可用,您应该使用源代码示例来熟悉SPARK,并尝试一些此处未介绍的其他选项组合。
8.2 Paddle
Paddle是Soot的上下文敏感指向分析和调用图构造框架,使用二元决策图(BDD)实现。Paddle在上下文不敏感分析中的准确度与SPARK相当,但当前的实现非常缓慢,主要是由于组成实现的不同程序的拼凑在上下文敏感分析中也提供了非常好的准确度。BDD的使用保证了时间和空间方面的效率,特别是在大型程序上。因为BDD提供了比SPARK和其他框架中更紧凑的集合表示,当前的实现非常缓慢,主要是由于组成实现的不同程序的拼凑
Obtaining and setup of Paddle
Paddle前端沿着Soot框架分发,为了避免在编译Soot时需要Jedd,“后端”是单独分发的。Paddle需要BDD实现和Jedd运行时环境才能运行,而这又需要Polyglot和SAT求解器。Jedd运行时提供了两个BDD实现:BuDDy(缺省)和CUDD BDD实现;也可以使用其他BDD实现,如JavaBDD和SableJBDD
所有这些条件使得正确安装Paddle比较复杂,所以我们现在给予了一个彻底的展示如何安装Paddle
- 下载最新的Paddle发行版,您应该使用夜间版本获取最新的更新和错误修复,夜间构建可从以下位置获得http://www.sable.mcgill.ca/~olhota/build/
- 下载
zChaf SAT解算器 http://www.princeton.edu/~chaff/zchaff.html ,通过make all安装,确保程序zchaff和zverify df可由您执行

Using Paddle
Paddle是一个用于上下文敏感指针分析的模块化框架,它允许对分析的各个组件进行基准测试,比如以上下文敏感的变化进行基准测试,使其成为一个非常有趣的工具。Paddle也是一种早期α-release,因此请注意Paddle的稳健性较差。
Paddle配备了大量选项,可根据您的特定需求配置分析。使用Soot命令行工具可以获得选项的完整说明,
1 | |
Paddle选项的指定类似于SPARK中使用选项名称和值的map,选项verbose、set-impl、double-set-new和double-set-old与SPARK中的相同。q选项确定队列的实现方式,并且enabled必须为true才能运行分析。propagator控制在将指针集进行传播时使用哪种传播算法,我们将其留给Paddle来选择并设置为auto。conf控制是即时还是提前创建调用图。Paddle的实现是基于子集的,但可通过将simple-edges-bidirectional选项设置为true来模拟基于等效的分析。最后四个选项是最重要的,所以我们描述一些细节:
- bdd:控制BDD是否启用
- backend:控制BDD后端选项 (BuDDy), cudd (CUDD), sable (SableJBDD), javabdd(JavaBDD) or none
- context:控制分析中使用的上下文敏感程度。如果值设置为
insens,则它的执行与SPARK框架执行上下文不敏感分析一样。1cfa Paddle执行1-cfa上下文相关分析。kcfa Paddle k-cfa执行上下文相关的,其中k是使用k选项指定的(这里的k应该指的是上下文调用深度)。objsens和kobjsens使Paddle分别执行1-object-sensitive分析和k-object-sensitive敏感分析。uniqkobjsens使Paddle执行unique-k-object-sensitive分析。默认为insens - k k选项指定用作上下文的调用链或
receiver Object的最大长度当上下文选项的值是kcfa、kobjsens或uniqkobjsens之一时

k-CFA上下文敏感分析基于作为上下文的调用点串,并且k描述的是调用串的最大长度。正常情况下调用点敏感分析运行良好,但如果添加了额外的间接层,例如同样的函数在setItem()方法中调用了,则仅依赖于调用点的上下文敏感分析将会合并对setItem方法的两个调用的 points-to-sets 集合,因为他们对同样的函数调用点一样。例如如下这种情况:

通过使用一串调用点,我们能够区分对相同函数的两个调用,从而使 points-to-sets 集保持分离。程序中的调用链长度可以是任意大的,因此我们需要将长度固定为k —因此使用了 k-cfa
下面测试一下利用 Paddle 的上下文敏感分析是否能推断出作为第4行声明的Container变量创建的item字段不与任何其他item字段共享 points-to 集。当设置选项为 1-cfa 时,Container.item变量的信息也与SPARK示例相同,这不是我们所期望的。
出现此意外行为的原因是以下行:
1 | |
这条语句位于 Container 类中,Paddle默认不使用上下文敏感的堆抽象,因此每个容器对象的item字段都使用相同的堆抽象表示的。如果我们将这行语句改成private Item item; 则容器的item字段不指向同一个抽象对象,并且在新的Container类上运行Paddle会产生预期的结果(如下所示)

获得正确结果的另一种方法是启动上下文相关的堆抽象选项 opt.put("context-heap","true"); 这使得 Paddle 能够区分分配给不同 Container 类的 Items 字段。
8.3 What to do with the points-to sets?
在最后两个小节中,我们详细描述了如何使用SPARK和Paddle指向分析框架,通过上下文不敏感或上下文敏感分析获得给定程序中变量的指向集。我们看到设置这两个框架相当复杂,因此这里需要阐明一下原因。
为了在许多分析和变换中获得精度,指向(或别名)信息是必需的。例如,精确的指向分析可用于获得精确的空指针分析结果或更精确的调用图,这又可导致其它分析中的更精确。精确的指向信息对于以下各项的准确性也至关重要,比如命令式和面向对象语言的部分求值。
9 Extracting Abstract Control-Flow Graphs !!
在本节中,我们将展示如何使用Soot提取抽象控制流图的自定义中间表示IR,该中间表示可用作您自己的分析和转换的起点
抽象控制流图捕获控制流的相关部分,并抽象掉不相关的部分。为了获得易于处理但又足够的表示来实施分析,通常需要去除不相关的部分。
一个很好的例子是Java字符串分析(JSA),其中跟踪和分析了Java字符串上的各种操作,如拼接。在 JSA 中,只有与控制流相关的字符串是待分析的部分,因此,在抽象期间控制流的其他部分被移除。同时分析基于抽象表示。

我们将使用上图所示的Foo类,它有一个操作对象状态的方法foo方法(可以是java.lang.String 的连接方法)。我们希望能够跟踪Foo对象在程序执行过程中是如何演变的,因此我们需要一个抽象的控制流图,它只关心与Foo对象有关的控制流部分。
9.1 The Abstract Foo Control-flow Graph
抽象Foo控制流图是对与Foo程序相关的控制流的描述。我们将控制流图表示为Java的一个非常小的子集,称之为Foo中间表示,如下图中的BNF所述。Foo中间表示仅包含六种不同的语句和三种类型,因此非常紧凑和易于管理。Foo 程序的中间表示是由一系列方法构成,其中包含图示中由 BNF 描述的语句,其中f的范围是Foo类型的标识符,m的范围是方法名,int是Java整数类型,τ是Foo类型或任何其他类型。

这六种语句为:Foo对象的初始化、对Foo类的foo方法的方法调用、调用其他方法并返回其他类型、方法调用foo以外的其他方法,返回类型等于Foo,最后是 nop 语句。
图中可以看到语句与执行行为的映射,与预期一致。Foo对象的实例化映射到Foo初始化。对foo方法的方法调用映射到Foo方法调用,Foo类型的赋值语句转换为Foo赋值语句。foo方法以外的方法调用分别转换为具有或不具有Foo返回类型的方法调用。在中间表示中,我们将非Foo对象实例化视为某个方法调用,它恰好是对构造函数方法的调用,我们将对Foo的强制转换视为某个方法调用,Foo作为返回类型。为了简洁起见,我们完全忽略了控制结构和异常,任何基于这种抽象表示的分析对于抛出异常的程序都是非sound的,因为异常可能会影响Foo对象的值
9.2 Implementation
实现从Java到Foo中间表示的转换包括两个步骤:首先实现Foo中间表示,然后实现Java和中间表示之间的转换。
Foo中间表示的实现非常直接,每种语句都继承了Statement类,该类提供了成为控制流图中的节点所需的一些常规功能,比如:存储前导语句和后继语句的集合。
代码被组织在 dk.brics.soot.intermediate 包的五个子包中。main子包包含主程序(Main.java),它使用转换来显示 foo 子包中的测试程序 FooTest.java 抽象控制流图的文本表示,这将作为运行或检查代码时的起点。在foo子包中,可以找到如上所述的Foo类。在表示子包中,可以找到中间表示的实现以及一些用于变量和方法的附加类。此外,还提供了一个访问者(StatementProcessor.java)来遍历语句(访问者模式)。在子包 foonalasys 中,可以找到类Foonalasys,它是基于中间表示上执行分析的表示,因此 Foonalasys 首先需要实例化并运行从Java到Foo中间表示的转换。 translation 类位于 translation 子包中。在这里,您将找到负责translation 的三个类:JavaTranslator, StmtTranslator, and ExprTranslator。
从 Java 的转换是通过 Jimple 完成的,因此转换需要理解清 Jimple 以及各种 Java 构造是如何映射到 Jimple 的,以便在从 Jimple 转换到 Foo 中间表示时识别它们。比如对象创建和初始化是在Java中的一个 new 表达式中完成的,但是在 Jimple 中已经像在Java字节码那样被分离成了两个构造,因此在从Jimple到Foo中间表示的转换中必须小心处理这一点。
Soot为 translation 提供了基础架构,特别是 AbstractStmtSwitch 和soot.jimple.AbstractJimpleValueSwitch 类非常有用。AbstractStmtSwitch 是一个抽象访问器,它为 Java(Soot)中可用的不同类型的语句提供方法(操作)。类似地,soot.jimple.AbstractJimpleValueSwitch 是一个抽象访问器,它为不同的 Jimple 值(如virtualInvoke、specialInvoke 和 add 表达式)提供方法(操作)。
translation 由三个类来实现:JavaTranslator、StmtTranslator 和 ExprTranslator。JavaTranslator 类负责翻译给定 Java 程序的各种方法,并将翻译后的语句连接在一起。JavaTranslator维护一个在 makeMethod 方法中初始化的方法数组。translate方法主要来完成实际翻译和已翻译语句的链接。
使用继承 AbstractStmtSwitch 类的 StmtTranslator 类转换各个语句。根据我们的经验,我们在StmtTranslator中使用的子集应该足以满足大多数用途。StmtTranslator的主要方法是translateStmt 方法,它将 StmtTranslator 应用于语句,并维护从 Soot 语句到 Foo 表示中相应代码的第一个语句的映射。这个 map 便于报告错误。此外,StmtTranslator还有一个方法addStatement,它将给定的 Foo 语句添加到正确的方法中,并维护对第一个语句的引用。addStatement 方法用于在翻译期间添加语句。
子表达式使用 ExprTranslator 进行转换,ExprTranslator 是soot.jimple.AbstractJimpleValueSwitch 类的扩展,因此会覆盖许多方法以实现转换。入口点是 translateExpr 方法,该方法基本上将 ExprTranslator 应用于给定的 ValueBox。我们只实现了运行示例所需的方法,因为我们的目标只是介绍如何创建抽象控制流图。指的注意的方法是caseSpecialInvokeExpr 和 handleCall 方法。caseSpecialInvokeExpr 方法检验我们是否正在处理 Foo 对象的初始化操作,如果是的话则创建一个 Foo 初始化语句,否则则它只是某个其他方法调用,执行 handleCall 方法。在这一点上,源代码与上面描述的表示不同,在源代码中,我们不区分这两种其他方法调用。
Concluding
Soot为创建自己的抽象控制流图提供了一些支持,但是Java是一种大型语言,在实现从Jimple到自己的表示的转换时,必须考虑许多不同的方面。此外,您必须弄清楚Java构造如何映射到Jimple,然后Jimple构造应该如何映射到您的表示。但是除此之外,两个抽象类AbstractStmtSwitch和soot.jimple.AbstractJimpleValueSwitch为翻译提供了很好的起点,并且工作得很好。