《面向源代码的软件漏洞静态检测综述》论文笔记
最后更新时间:
《面向源代码的软件漏洞静态检测综述》论文笔记
引言部分
软件漏洞的定义
指软件在器生命周期(即开发、部署、执行整个过程)中存在的缺陷
软件漏洞静态检测分类
基于分析对象
- 二进制漏洞检测
- 源代码漏洞检测
由于源代码当中拥有更丰富的语义信息,因此关注点更多在后者
源代码漏洞检测方法
基于中间表示的漏洞检测
首先将源代码转换为有利于漏洞检测的中间表示,然后对中间表示进行分析,检查是否匹配预定义的某个漏洞规则,从而判断源程序中是否含有对应漏洞规则相关的漏洞
基于逻辑推理的漏洞检测
将源代码进行形式化描述,然后利用数学推理、证明等方法验证形式化描述的一些性质,从而判断程序是否含有某种类型的漏洞
后者可靠性强,但是不适于大规模的项目代码
基于中间表示的源代码漏洞检测方法
2 基于代码相似性的漏洞检测
核心思想:相似的代码很可能含有相同的漏洞
缺陷:很难检测那些不是由代码复制引发的漏洞代码表征
用来抽象代码段,方式多样
基于度量的表征:从代码段不同角度采取不同的度量
基于复杂性、内聚和耦合
基于相似的导入和函数调用集合
缺陷在于无法表示比较单元的全部特征,也就是只能参考某几个角度
基于标记的表征:仅利用词法分析得到的标记序列进行比较
ReDeBug 特征散列法标记 + diff
Li 基于滑动窗口进行比对
Scandariato 文本挖掘,偏深度学习预测
Yamaguchi 将函数转换为主要API使用模式的组合,配合机器学习
CP-Miner 频繁子序列挖掘技术
缺陷在于 仅停留在词法级别,而没有分析语法语义信息
基于树的表征: 利用树来表示源码中的程序结构
Yamaguchi 提取函数的抽象语法树 + 机器学习分析结构模式
SecureSync 采用扩展的抽象语法树
缺陷在于 复杂度较高,难以用在大工程中
基于图的表征:节点表示表达式或语句,边表示控制流、数据流或控制依赖,在前面的基础之上还加入了语义信息
Yamaguchi 提出代码属性图的概念,其结合了抽象语法树、控制流图和程序依赖图 (YAMAGUCHI F, GOLDE N, ARP D, et al. Modeling and discovering vulnerabilities with code property graphs[C])
CBCD 子图同构匹配 + 4种PDG查询的优化法
SecureSync 基于图的API
缺陷在于 建立图、匹配图的算法复杂度都很高
代码段级别
代码段抽象的粒度级别
不带上下文的补丁级
用于错误检测切片级
基于程序依赖图,代码相似性通过子图间的同构来表示(李赞, 边攀, 石文昌, 等. 一种利用补丁的未知漏洞发现方法)
带上下文的补丁级别
函数片段 函数作为独立单元
文件/构件代码段级别
比较方法
向量比较法首先将程序的表征转换为向量,然后通过向量进行比对;近似/精确匹配法通过一些匹配策略来查找漏洞表征
3 基于符号执行的漏洞检测
分为符合执行和约束求解两部分技术,前者用于将程序变量值转换为符号值和常量组成的计算表达式;后者用来判断变量取值是否满足约束,一方面检测路径可达,另一方面检测漏洞触发条件。
动静态结合 (沈维军, 汤恩义, 陈振宇, 等. 数值稳定性相关漏洞隐患的自动化检测方法)
符号执行可以生成触发漏洞的具体输入,验证并分析漏洞
但是无法扩展到大规模程序4 基于规则的漏洞检测
人工分析漏洞规则 + 源代码建模,进行数据流分析、污点分析等
(王蕾, 李丰, 李炼, 等. 污点分析技术的原理和实践应用)
很依赖规则的定义
5 基于机器学习的漏洞检测
按照是否需要人工定义表征来划分:
基于传统机器学习的方法
针对特定漏洞类型的方法:机器学习技术学习漏洞模式,前提需要借助专家知识
给定一个sink,自动识别 source-sink 系统以及构建系统中数据流和净化的模式
(YAMAGUCHI F, WRESSNEGGER C, GASCON H. et al. Chucky: exposing missing checks in source code for vulnerability discovery[C])
针对漏洞类型无关的方法:也需要手工定义特征。这里的特征也就是前面提到的漏洞表征
基于深度学习的方法
可以自动生成漏洞模式
缺陷在于:1)粗粒度 2)数据集涵盖不足 3)深度学习模型有限 4)止步于检测出是否有漏洞
利用深度学习进行API学习 (GU X, ZHANG H, ZHANG D, et al. Deep API learning[C])
6 实例1: 基于源代码相似性的漏洞检测
问题阐述
需求:当某个漏洞的补丁公布时,在给定漏洞和源代码的前提下自动判断源代码是否含有该漏洞,给出漏洞的位置
待解决的问题:
- 不存在能够用来评测基于代码相似性进行漏洞检测研究的数据集
- 不存在某个代码相似性算法适用于所有漏洞
解决方案
架构如下:
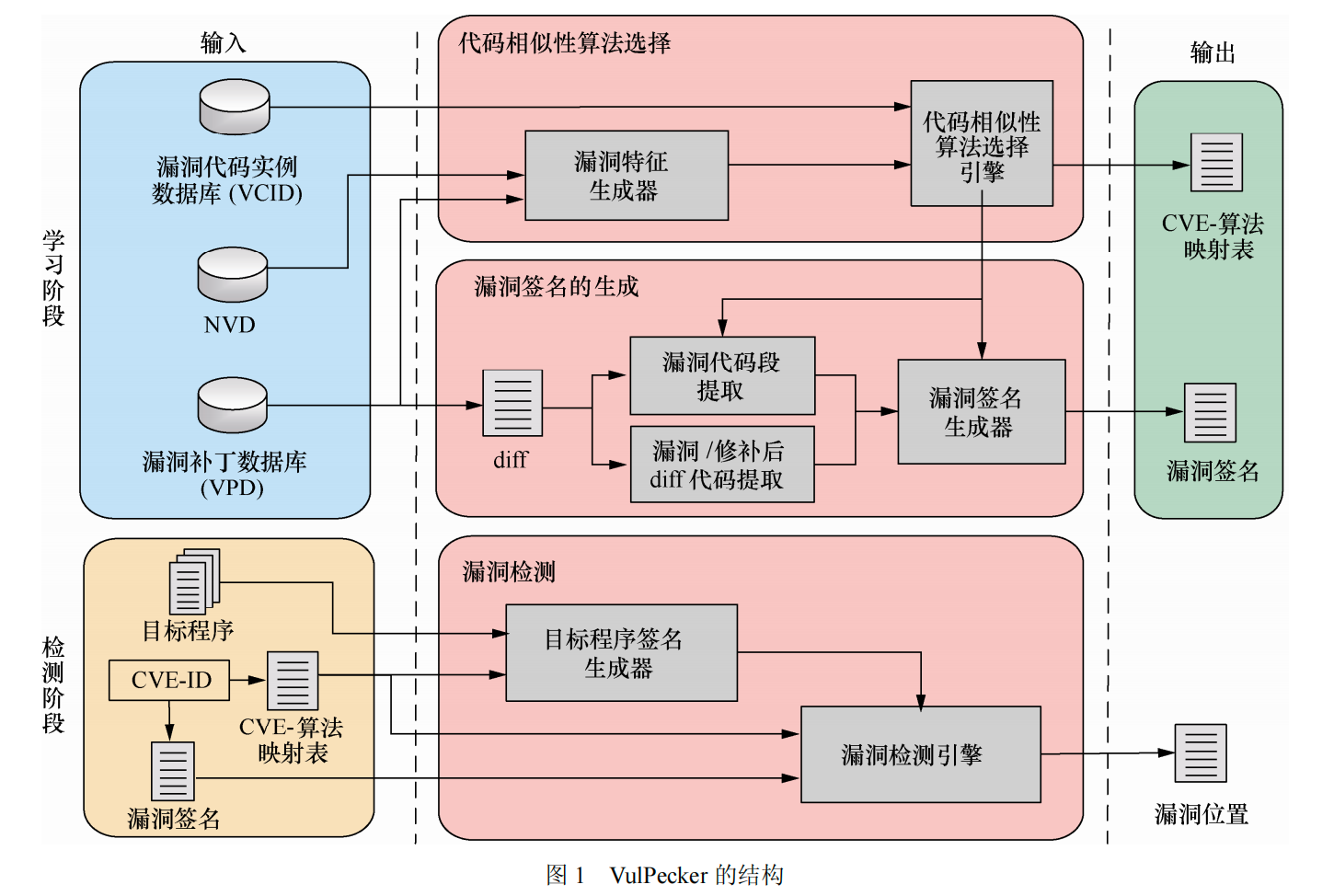
学习阶段:选择对给定漏洞有效的代码相似性算法,选择的算法反过来知道漏洞前面的生成
检测阶段:复制漏洞检测
首先给定漏洞及其补丁,该漏洞可通过描述漏洞补丁的diff文件来刻画,由基本特征和修补特征集合来表示
大致流程:
通过diff块及对应的漏洞代码复制实例构件数据集
基于数据集,首先对diff块进行文本分析和语法分析,提取定义的类型特征;然后通过在函数级构件抽象语法树,利用算法进行节点匹配,生成操作序列,进一步提取类型特征
代码相似度算法:
输入:候选代码相似性算法、漏洞 diff 块特征向量、准确率阈值和 VCID 数据库
输出:CVE-算法映射表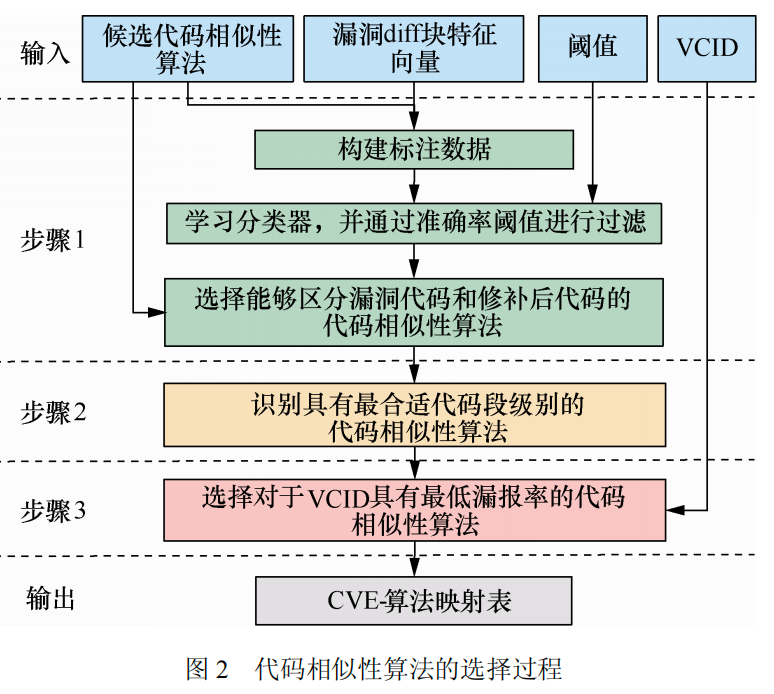
生成漏洞签名:
首先提取漏洞代码和修补diff代码;根据算法的代码段级别从源码中提取漏洞代码段;预处理并表示,最后应得到相应的代码表征作为漏洞签名漏洞检测部分:
首先CVE-算法映射表的作用是可以根据diff块及选择的代码相似性算法使用的代码表征生成目标程序签名;然后通过在目标程序签名中匹配漏洞签名来确定漏洞位置
7 实例2: 面向源代码的软件漏洞智能检测
问题阐述
当前想解决的问题在于基于人类专家定义漏洞特征的手段主观性较强,质量参差;同时漏报较高
目标:漏洞检测系统低漏报,误报在可接受的范围内
方向:深度学习,借鉴 CV 中的目标检测
待解决的问题:
- 没有明显的细粒度代码结构来描述漏洞的候选区域
- 数据集无法涵盖所有类型,且标注困难
- 模型不合适
解决方案
架构如下:
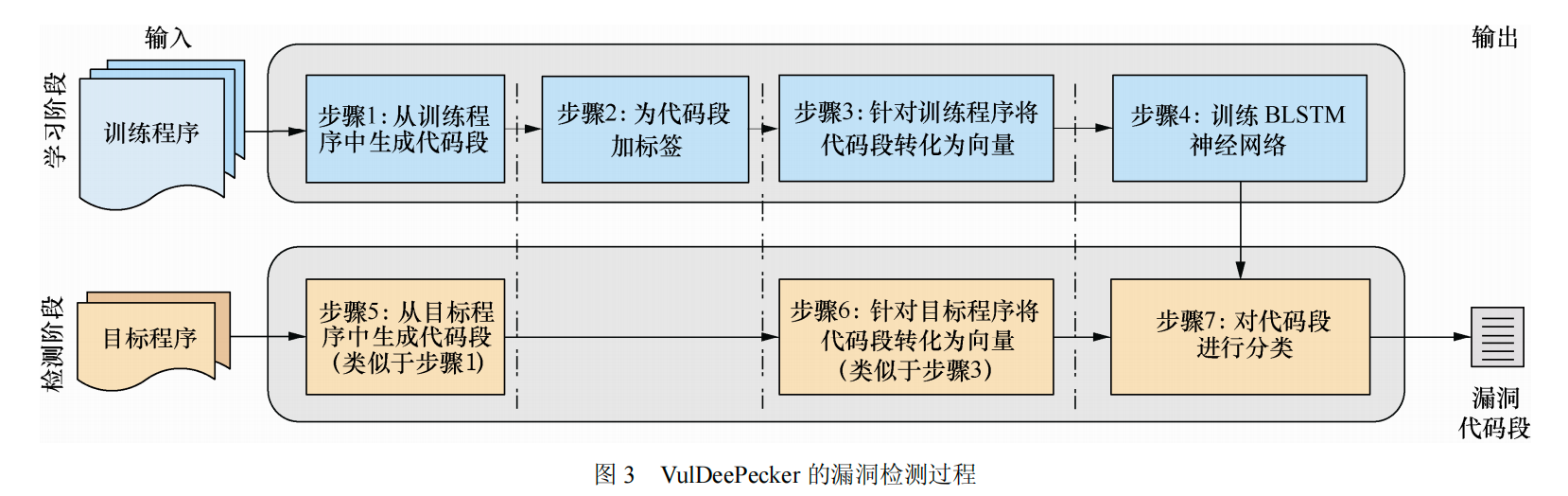
基于 BLSTM 自动学习生成漏洞模式
学习阶段:
- 提取API调用的多个切片组合成为一个代码段
- 为代码段根据已知漏洞信息加标签
- 代码段 -> 符号表征 -> 向量(BLSTM 输入)
- 训练 BLSTM 神经网络
检测阶段:
前面步骤和学习阶段类似,最后是针对有无漏洞对代码段进行分类
效果上优于基于代码相似性的方法