《P/Taint Unified Points-to and Taint Analysis》论文笔记
最后更新时间:
P/Taint: Unified Points-to and Taint Analysis 精读
前言
本文提出的一个观点就是,信息流分析本质上等同于指针分析,只不过人工定义了需要信息源指向的抽象对象。
两者相结合的好处体现在多个方面。首先可以在不做过多修改的情况下,直接用指针分析实现来计算污点分析;并且一些增强版指针分析(如不同版本的上下文敏感指针分析)以及处理反射的分析都可以直接用在信息流分析上。最后利用了一个 Doop 分析框架来证实这些好处。
Introduction
污点分析可以用于检测敏感信息可能流动的位置;而指针分析回答了“程序中的对象指向关系”,是各种应用的底层分析引擎
两者的共同点在于它们都回答了”值在程序中的流动”。不同点在于指针分析计算的是堆抽象的引用关系;而污点分析计算的是污点 source 可以影响到哪个值并且该值是否可以到达 sink 点,并且污点值的类型可以转换。
本文提出的技术在于合并两种技术的算法细节。核心在于 changing the domain of points-to information targets 。之前的指针分析中变量指向的对象都是由堆分配,在合并的算法中,对象并不仅是源程序中预定义的,还引入了一些可动态引入的值。这种动态引入既发生在污点 source 的定义当中,也发生在污点传播过程中。算法唯一的改动实际就是操作对象当中加入了人为的 “objects”,也就是污点信息。
作者依据提出的技术对 Doop 指针分析框架做了扩展,提出了 P/Taint 信息流框架。其增加了功能:即时计算污点值、标记污点 source、在非相关类型值之间转播污点以及值的清理。本质上采用的还是 Doop 框架的算法,增强了输入。
P/Taint 框架的优势:
- P/Taint 无需对原有 Doop 框架代码作过多修改,而其他增加的功能都是如附属插件一样灵活加入,很好的适用于多种框架分析
- 继承了 Doop 框架提供的多种分析方式,以及多种上下文敏感方式,为信息流分析提高了精度,减少误报
- P/Taint 继承了 Doop 框架提供的针对 Java 语言的多种高级特性分析,使得信息流分析能检测出更多的漏洞,降低漏报
Background and Illustrations
指针分析基础
指针分析计算的是程序中的表达式所指向的抽象对象。抽象对象通常由调用点来标识,调用点就是如 new 实例对应的指令执行分配的:这里还会分上下文敏感和非上下敏感,对于前者,所有运行时对象如果是同一指令分配的则会映射到同一抽象对象,也就是忽略了上下文堆抽象。
指向分析的源头就是从一个分配指令开始
1
A a1 = new A(); // heap allocation/abstract obj.指向分析将简单地推断局部变量 a1 可以指向用上述 new 语句标识的抽象对象。指向分析的精髓实际上在于计算这些抽象对象如何在不同语言构建上流动,下面以方法的调用、返回和局部赋值语句以及堆抽象对象的 loads 和 stores 为例:
1
2
3
4
5
6
7
8
9
10
11
12Object p = foo();
bar(p);
B b1 = p.fld;
...
A foo() {
A a1 = new A(); // abstract object A1
return a1;
}
void bar(Object q) {
A a2 = (A) q;
a2.fld = new B(); // abstract object B1
}在这个例子中局部变量 a1, p, q 和 a2 都可以指向抽象对象 A1,而局部变量 b1 指向抽象对象 B1。最终,抽象对象 A1 通过方法调用和返回流动, B1 通过抽象对象的 loads 和 stores 流动。
指针分析算法的精髓就在于能尽可能精确的推断出对象流动(may analysis)。其分析结果是一个变量和它所指向的所有抽象对象(调用点)的映射 map.
信息流分析基础
信息流分析计算的是哪些作为 source 的数据产生的值可以到达特定的数据 sinks 处。它通常用在分析实际的安全和隐私问题上:计算哪些污点数据源 sources 可以产生污点数据用在可信计算上(类似越权、非授权);以及一些非授权访问、信息泄露的场景。
信息流分析计算的起点通常是一个作为 source 点的 API调用,比如下面是一个接收用户输入字符串的代码:
1
String a = source.readLine(); // taint source信息流分析的精髓在于追踪所有在程序当中传播的污点值。这里要区分污点和对象的概念。污点关心的是其数据的值,而不是它们在内存中的位置(或者说堆分配方式)。
因而,相同的污点可以通过不同的对象类型传递。它通常是利用的数据转换函数来传递的,如:
1
2String a = source.readLine(); // taint source
byte[] aAsBytes = a.getBytes();可以看到尽管 a 和 aAsBytes 变量的类型不同,但是拥有同一污点 source。污点字符串值产生了污点字节数组,但实际上污点的内容没有丢失。
最后,污点可以通过 sanitization 函数移除。如:
1
2String a = source.readLine (); // taint source
String aSafe = java.net.URLEncoder.encode(a, "UTF -8");相似点:都计算了对象在程序中的流动
区别:
- 对于指针分析,流入变量的值是抽象对象(调用点);对于信息流分析,代表的是污点 sources (方法调用)。
- 污点和对象的同一性是截然不同的概念。同一个污点可以施加到不同的对象上。而同一个抽象对象可以代表具体的污点对象也可以是非污点对象。同一对象可以在其生命周期的不同点处或污染或不被污染。Sanitization 和 数据转换函数并未在指针分析中涉及。
兼容方法:
对象通过方法调用和堆的流动与原先指针分析算法一样,增加了一些值但是保持原来的处理逻辑:识别出所有的信息流 sourses 和数据转换函数,通过手动构造抽象对象,让原有的指针分析算法按照和之前调用点抽象的处理逻辑一样进行分析。
还拿刚才的例子:
1
2
3
4String a = source.readLine ();
// artificial abstract object
byte[] aAsBytes = a.getBytes ();
// parametric artificial abstract object联合的分析会视 readLine 方法调用为手动构造的抽象对象的 source。手动构造对象表示一个特定的污点,它作为一个值与常规对象一起传递。手动构造的抽象对象和指针分析中的抽象对象实质是正交的,也就是说如果一个变量同时指向这两种抽象对象,那么说明该变量接收了一个指定调用点分配的污点对象(污点信息指向标记的 source).
类似地,对于数据转换函数的调用也会手动构造 sources 的抽象对象,区别在于为了保存每一个污点值,需要对每一个传入调用的污点值都构造一个抽象对象。
对于 sanitization 函数,只会控制 inter-procedural 传播涉及到的手动构造的抽象对象。污点值不会流入 sanitization 方法。实际上这个是原有指针分析算法逻辑为了支持联合分析所需做出的少部分改动: inter-procedural 传播在涉及到 sanitization 函数调用时需要过滤掉所有涉及的手动构建的抽象对象。
Analysis Design
这部分参考 Datalog
下面我们在一个模型上展示联合分析:最小输入语言上的基于逻辑的规范(在 Datalog 语言的语法中,等同于具有递归的一阶逻辑)。提出的模型是对标准逻辑规范的增量添加,用于Andersen风格的指针分析。它集成了几乎所有指针分析算法,并且可以增添许多特征。这些添加相对于我们对基本模型的最小更改是可以忽略的。所以这允许信息流分析可以联合不同种类的指针分析。
From Pointer to Information-Flow Analysis
首先忽略数据转换函数和 sanitization,先讨论如何将信息流分析和指针分析作同步。
下面图1展示了分析中的 domain,包括输入,关系运算和输出,以及产生新污点值的构建函数。图2代表分析。
红色框住的元素代表修改了用于支持信息流分析的部分,其余为参数和谓词的别名。语法规则:左箭头将推断出的 facts 和已知的 facts 分隔开


模式变更:定义值抽象 A , 包括指针分析中的调用点抽象 $A_H$ 和 污点值抽象 $A_T$. 它们都代表程序当中值引入的位置;重命名指针分析的输出关系 $V_{AR}P_{OINTS}TO$ 和 $F_{LD}P_{OINTS}TO$ 为 $F_{LOWS}T_{O}V_{AR}$ 和 $F_{LOWS}T_{O}F_{LD}$ . 也就是说之前所有的堆抽象概念转变为统一的值抽象
算法变更:在图2中,前8条规则时标准的上下文敏感指针分析模型。唯一的变化是在计算调用图上 (谓词 $C_{ALL}G_{RAPH}$). 在计算 virtual calls 的 receiver objects 时不是所有的值抽象都用到:因为 receiver objects 必须是标准的堆抽象。这个检查可以避免分析到达一些不可达的方法,虽然说污点对象看起来在调用点调用了。这个原因在于污点值抽象和堆抽象在传播规则上略有不同,后者的规则中引入了即使在正常对象不会传播的情况下也可以促进污点值流动的捷径。
最后两个规则时新引入的。它们只是将对信息 sources 的调用标记为创建抽象值的点,将对信息 sinks 的调用标记为泄漏点,并将其作为输出的一部分进行报告。
前两个规则中的第一条说明了当 source 方法(利用输入谓词 $S_{OURCE}M_{ETHOD}$)计算得到是可达的话(利用 $C_{ALL}G_{RAPH}$),那么接收返回值的变量将会指向一个新的抽象值。新的构造函数的引入是通过构造函数 $N_{EW}T_{AINTED}V_{ALUE}$. 这个构造函数是分析的一个参数化点,但通常将其定义来保留传递给它的所有信息。
NewTaintedValue(invo, type) = pair(invo, type) : AT
也就是说,新的抽象值回同时去编码调用点和值的类型。污点可以从一个值抽象转移到另一个值抽象,稍后我们将看到这种编码如何帮助确保值抽象只会拥有单一类型。调用点记录可以获知程序中最初引入污点值的位置。
最后一个规则只是对分析结果的利用。它表述了如果抽象的污点值到达了 sink 函数调用点的第i个参数上,且第i个参数是敏感的话,则会导致信息泄露($S_{INK}M_{ETHOD}(meth,i)$)。
Flow-Through Data Transform Functions

图3的引入是为了支持数据转换函数能够使得污点信息在不同数据类型的值之间传播,这里定义了一些额外的规则和逻辑来表示污点对象的创建。要指出这里只是列出了一些典型的污点转换规则,在 P/Taint 中定义了更多方式(这里说的也就是污点传播方式,tai-e 中有特别说明)。
图3中定义了两种新的输入关系,BaseToRetTransfer 和 ArgToRetTransfer,一个中间谓词 IsTaintedFrom,和新的构建函数 TransferTaint. 新的输入关系编码了方法返回值的污点传播方式,或者是方法调用的 receiver variable(base variable),或者是参数传递。为了方便,会列出新的污点值类型。前两条规则中将输入信息组合为更一般的中间谓词,IsTaintedFrom(from,to,type) 捕获了哪些变量作为输入以及新产生的污点值及其类型
图中的第三个规则负责处理在现有污点值流向转换函数时创建新的污点值。这个规则体中有个细节:新的污点值并不是在转换函数返回点处产生(对应变量 to),而是只要污点对象流到该点,且该点为堆对象第一次分配和赋值处。
TransferTaint 构造函数用来创建新的污点值,它是分析模型的一个参数:不同的定义将决定创建多少污点抽象对象,进而影响精度和扩展性。一个合理的定义如下:
TransferTaint(value, type) = pair(first(value), type) : AT也就是说,新的污点值会编码输入污点值的前半部分(即原始污点 source 的调用点)以及新产生污点值的类型。
Sanitization Functions
Sanitization 函数的处理要阻止所有污点值流过其预定义函数。因此引入新的输入关系,SanitizationMethod 并且修改了跨函数赋值的逻辑。
可以看到这个规则在处理堆抽象的传播时逻辑不变,而污点值只有当赋值语句的左边变量(也就是变了 to)是 Sanitization 函数的显式参数时才会传播。

Scaling to a Full Taint Analysis Framework: Benefits
前一部分构建的模型是 P/Taint 框架的基础,下面将描述如何将方法拓展至实际的编程语言以及其中的优势
Broad Support of Java Semantics
首先前面所提到的最小模型是不足以支持完备的针对 Java 字节码语言的安全分析的。对于其高级特征的建模将会对静态分析的复杂性大大提高(指数级),但是也能提高性能。
对于联合指针分析和信息流分析的方法来分析这些复杂语义的一大好处就是它们只会被处理一次。本质上,所有对于语言语义的建模都只关注值的流动,并且是不变的,而不会管这些值是堆对象还是污点对象。
Reflection
P/Taint 继承了 Doop框架针对反射的支持
Context Sensitivity and Precision
我们可以通过上下文敏感来提供指针分析的精度:通过上下文信息来量化变量和抽象对象,因而不会对不同方法调用点的对象或者同一抽象对象作合并。
首先,Doop 中已经有一套成熟的模式在规则中添加上下文敏感信息,而且通过定义构造函数 Record 和 Merge 该模式允许插入不同的上下文模型(call-site / object / type / hybrid).
下图中展示了图2中上下文敏感形式的 CallGraphEdge

Merge 用于创建 virtual 调用点的新的调用上下文。这些上下文信息用来量化方法调用,即它们将施加到方法中的所有局部变量上。Merge 函数将会获取 virtual 方法调用点的所有信息并合并创建一个新的上下文
Other Pragmatic Features
实用特征之一是能够标记 sources 和 sinks 。标记的实现是利用的 NewTaintedValue 构造函数,其参数包含 source 的标签,对污染值的来源进行索引,以便在查询 FlowsTo 时可以检索标签
其次是支持 breadcrumbs,也就是关联污点抽象值来帮助用户调试应用中的信息流。信息流中间步骤信息的添加是通过污点传播规则和函数来实现的,TransferTaint 构造函数会获得一系列预定义的 breadcrumbs 和 当污点数据发生转移时保存的抽象值信息。这些breadcrumbs 可以随后处理并通过查询拼接展示完整的信息流。
Overall Benefit
实际上就是说代码更改的地方不多,大多修改的地方是在配置 sources 和 sinks 上(利用正则表达式表示)。指针分析部分的代码已经能很好的处理污点抽象对象的传播
Discussion
Contrast whith Conventional Approaches
对于传统的基于 Datalog 的污点分析,是指针分析的应用。它定义的关系当中会有一些相对于 P/Taint 定义的关系拆分的形式,导致重复的工作产生(性能)。
而对于 P/Taint 联合方法的一个特征在于是将污点表示为独立于常规对象(指堆抽象对象)传播的新抽象值(规则一样)。与之对比,在传统的 Datalog 分析当中,对象的分配使用污点值作标记(利用独立的输入关系
IsPrivileged(obj, taintType)),这样的决策只是利用了指针分析的结果,而没有任何增强的表现。通过在堆抽象对象的分配点标记污点,指针分析将只能传播对象(就好像不考虑污点一样)。污点分析就可以观察对象在哪里传播以及传播的最大限度。在传统的 Datalog 分析中,这意味着只要对象指向污点对象(甚至没有从污点对象的 fields 中获取值)就已被视作污点。
对于传统的安全分析框架,P/Taint 框架提供了一套更普适的全程序分析框架,它为程序的依赖库也提供了分析。相反一些安全分析框架需要额外设定模型来分析程序的环境,这当然是不完备的。P/Taint的指针分析思路是流向底层数据结构,这样对污点的传播非常有效,特别是在分析一些开源产品的时候。后者常会用一些第三方组件或者自定义数据结构,而不是标准的 collections 库。
Limitations
- 模型限定了只会使用流不敏感分析
- 分析模型没有采用 access-path-based 公式。access paths 是形式如
var(.fld)*这样的表达式。它可以在指针分析中表现在概念如”这个 access path 指向这个值” 或者 “这个 access path 是别名”,拓展到污点分析就是计算被污染的以及别名 access paths。这种概念有利于进行模块化分析,避免了计算整个程序的堆映像
Practical Elements
下面是一些实践应用
Android Support
Conventional Java Program Support
P/Taint 支持对 servlet 应用的分析。利用的是针对开源程序的分析特性,也就是程序有多个公共的入口点而不是单一的 main 方法启动。因此分析只需对环境进行精确建模来构建准确的调用图,包括支持添加所有的 servlets 入口点到调用图上,以及实例化 servlet 应用的环境变量。
另外,通过对 java.lang.String 类内部进行建模,引入了一些针对字符串操作的通用处理。这种建模使得污点派生自内部字段
char[] value,意味着一旦字符串对象被污染了,其内部的字符数组也会被污染,反之亦然。由于这种方法只会作用于纯 Java 操作,因此如果是依赖于 native 代码的字符串操作则需要显式建模。对于对象的序列化和反序列化也是这样。
Evaluation
针对下面四个问题开展实验评估:
- 是否低误报?
- 是否低漏报?
- 相比于其他工具,是否在信息流分析检测中表现更高的精度
- 是否可扩展以及在运行时间上高效
实验装置上一套作为基准对照,已经做过信息泄漏的标记且源代码可知;另一套是开源程序:大规模Android应用程序,没有标记信息流。
Controlled Benchmarks
我们采用了以下几个控制基准:
- SecuriBench Micro 包含了122标记的可能安全缺陷的 servlets
- JInfoFlow-bench 采用了反射、事件驱动架构以及流行的软件设计模式
- DroidBench 2.0 多个 Android 安全风险
对于 SecuriBench Micro 的测试,由于 P/Taints 支持开源程序的特性(自动添加所有入口点到调用图上),所以不需要为每一个 SecuriBench 应用手动编写测试样例。其会同时分析完整的程序套件,结果基本一致
对于 JInfoFlow-bench 的测试,其提炼出了很多 Java 程序中难以分析的特征,需要高精度的分析以及支持反射特性的信息流检测。这个基准套件绝大多数行为并未依赖于外部库的使用,因此很难专门写一个安全优化分析出来
对于 DroidBench 2.0 的测试,P/Taints 未对其中的 implicit-flow 套件以及 emulator detection 套件作实验评估,后者更适于用动态分析来检测应用在竞争条件下的行为差异,而前者更适于对控制依赖建模的污点分析(流敏感)
Overall Effectiveness
结果如下:


总体表现出了高精度和低误报。误报的来源在于 P/Taint 非流敏感或者 path 敏感,以及数组敏感(不区分数组索引)
Sensitivity Analysis: Precision
用不同的上下文敏感支持来运行 SecuriBench Micro 以及 JInfoFlow-bench benchmarks 下面的图中展示了精度分数。
可以看到在我们联合分析的方法中,无需做更多代码上的更改,仅需选择不同的上下文敏感分析,就可以在精度和可扩展性之间做权衡。


还有一些其他的发现:
- 在不同的环境下,不同的上下文敏感方式展现出不同的精度优势
- 上下文敏感的方式对于一些并不是用来测试上下文敏感的样本(用到了JRE中的复杂数据结构)也能展现出很好的效果。依靠的就是 P/Taint 对于全 Java 语言语义的支持以及优秀的上下文敏感策略
Sensitivity Analysis: Recall
反射是影响现实信息流分析样本召回率的主要特征,我们通过是否使用 P/Taint 的反射支持来作对比。这里提一句反射的支持利用的 Doop 提供的技术(利用 substring analysis + use-based analysis).
JInfoFlow-bench 测试样本中包含更多的基于反射的行为,图示中可以看到影响变化。

Sensitivity Analysis: Running Time
图示中展示了不同的测试样本在不同分析参数下运行所需的时间。注意图表中的两部分并不在同一尺度上,首先对于 open programs 的支持使得对于所有 SecuriBench 的程序可以同时并行分析,导致更快的运行时间。而对于其他样本,都是单独分析,因此总时间达到几十分钟。


总体来看,虽然反射会使得分析时间加倍,但是还是高性能的。
UnifiedAnalysis vs. Points-To
最后,我们记录了一些联合分析与原始指针分析在性能度量上的对比。已知两者算法逻辑的核心是一样的(指针分析),只不过前者会处理更多的抽象对象。所以我们展现了分析中通过推断“流入”污点抽象对象以及堆抽象对象的相对占比。
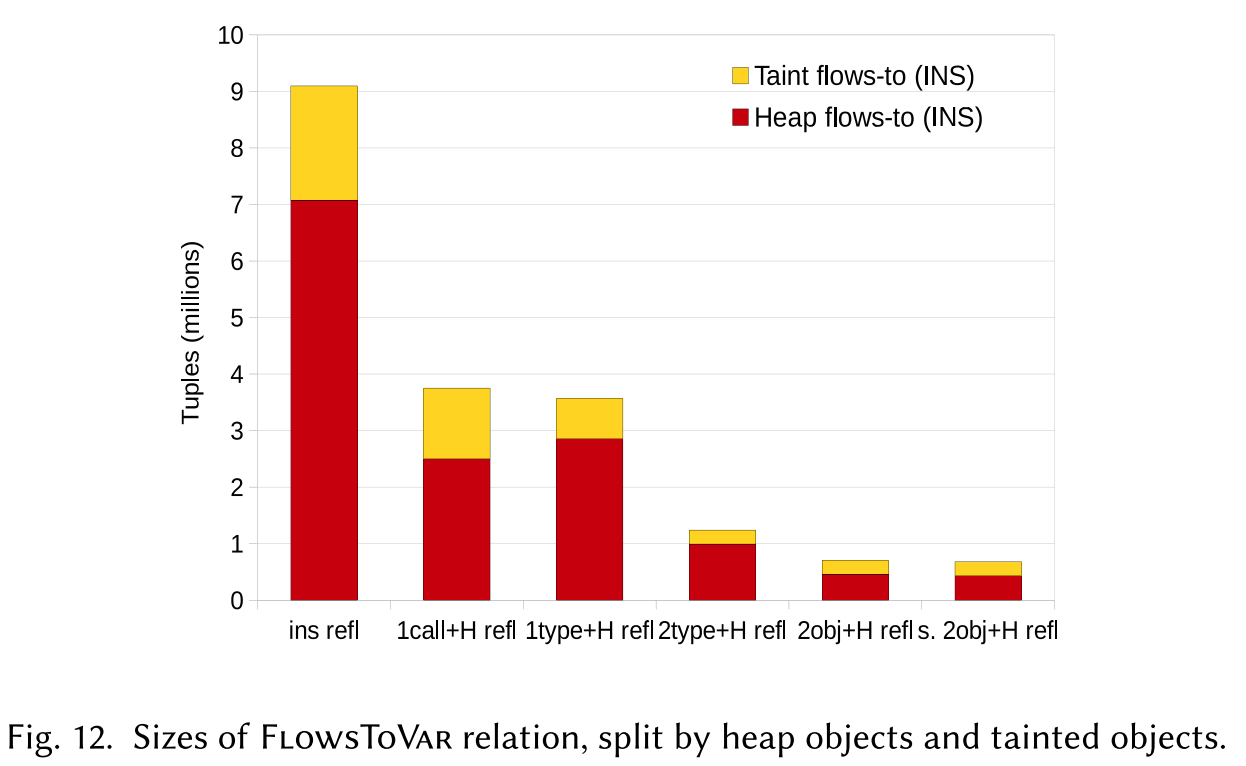
图示中表示了 FlowsToVar 关系的大小(除去了上下文信息),其中分成指向抽象污点对象的元组和指向抽象堆的元组。经过不同精度的多次分析,我们可以看到污点对象流也是整个计算的重要占比。这证实了污点传播并不是底层分析逻辑的附加任务,即使只是少量的污点 sources,也能同堆抽象对象流产生的分析推断相竞争。
Related Work
- 利用污点分析
探索利用 Datalog 进行污点分析(未使用联合的方法)
Benjamin Livshits. 2006. Improving Software Security with Precise Static and Runtime Analysis. Ph.D. Dissertation. Stanford University
提出污点分析是一种需求驱动的问题,而非完整的全程序指针分析流
Omer Tripp, Marco Pistoia, Patrick Cousot, Radhia Cousot, and Salvatore Guarnieri. 2013. ANDROMEDA: Accurate and
Scalable Security Analysis of Web Applications
程序依赖图的使用
控制依赖图对检测信息流中的隐式控制依赖比较有帮助
动态语言的分析研究
一种通用的分析组合模式是以交织的方式来执行两种分析(互相反馈)这个区别于本文提出的方法,后者利用的是一个分析的逻辑来执行另一个分析,而不是同时对两个分析进行评估,并且底层的指针分析结果并不受额外加入的污点抽象对象的影响。