《Modeling and Discovering Vulnerabilities with Code Property Graphs》论文笔记
最后更新时间:
Modeling and Discovering Vulnerabilities with Code Property Graphs
Abstract
当前安全漏洞的威胁大多源于不安全的代码所致,因此为解决该问题需要专业人员单调且易出错的大量审计工作。在本文中,提出了一种有效地挖掘大量源代码漏洞的方法。通过引入一种针对源代码的新型表示——代码属性图,也就是结合经典程序分析当中概念:抽象语法树、控制流图以及程序依赖图,构成一种联合数据结构。这种表示使我们可以利用图遍历的方式对常见漏洞进行建模。用图数据库来实现。
Keywords
漏洞;静态分析;图数据库
I. Introduction
计算机系统的安全性取决于底层软件的代码质量。这是因为常见的漏洞通常都会在程序代码当中表现出来,例如未考虑缓冲区边界或者对输入数据的不充分检查。
由于一个程序不能识别另一个程序的非平凡属性(这个属性不对所有程序都为真或者为假),因此查找软件漏洞的一般问题是不可判定的(莱斯定理)。当前的方法要么仅限于指定类型的漏洞,要么就是大量的人工审计。特别是针对操作系统内核这样的大型程序工程,即使一个漏洞都可能会导致整个程序的安全问题,然后即使是一些存在已久的经典类型漏洞,如缓冲区溢出等,如果没有大量的专家知识储备,也是很难发现的。
安全研究最初关注在指定类型漏洞的挖掘上,后来基于软件测试的概念,衍生出利用动态分析来检测,包括从简单的模糊测试到高级污点追踪和符号执行技术。但是这些方法会受制于运行时间过长或执行路径呈指数增长需要考虑。所以作为补救,通常是利用专家知识扩充静态程序分析来辅助人工审计。
本文提出的方法结合了程序分析的经典概念和图挖掘领域的最新发展。方法的思想在于许多漏洞只能通过综合考虑代码的结构、控制流和依赖性才能发现。因此我们为处理这个需求,引入源程序的新型表示——代码属性图。该图结合了抽象语法树、控制流图以及程序依赖图构成联合数据结构,这种对代码的综合视角使得我们可以利用图遍历的方式对常见的漏洞进行建模。类似于数据库的查询,图遍历的方式使得我们可以审查程序结构中相应结点的属性,从而为几种类型的漏洞做成简洁的模板,从而帮助审计大量代码的漏洞。
实验过程是先用流行的图数据库实现并针对几种已知的漏洞设计图遍历,并运用在 2012 Linux Knernel 的漏洞检测中。
II. Representations Of Code
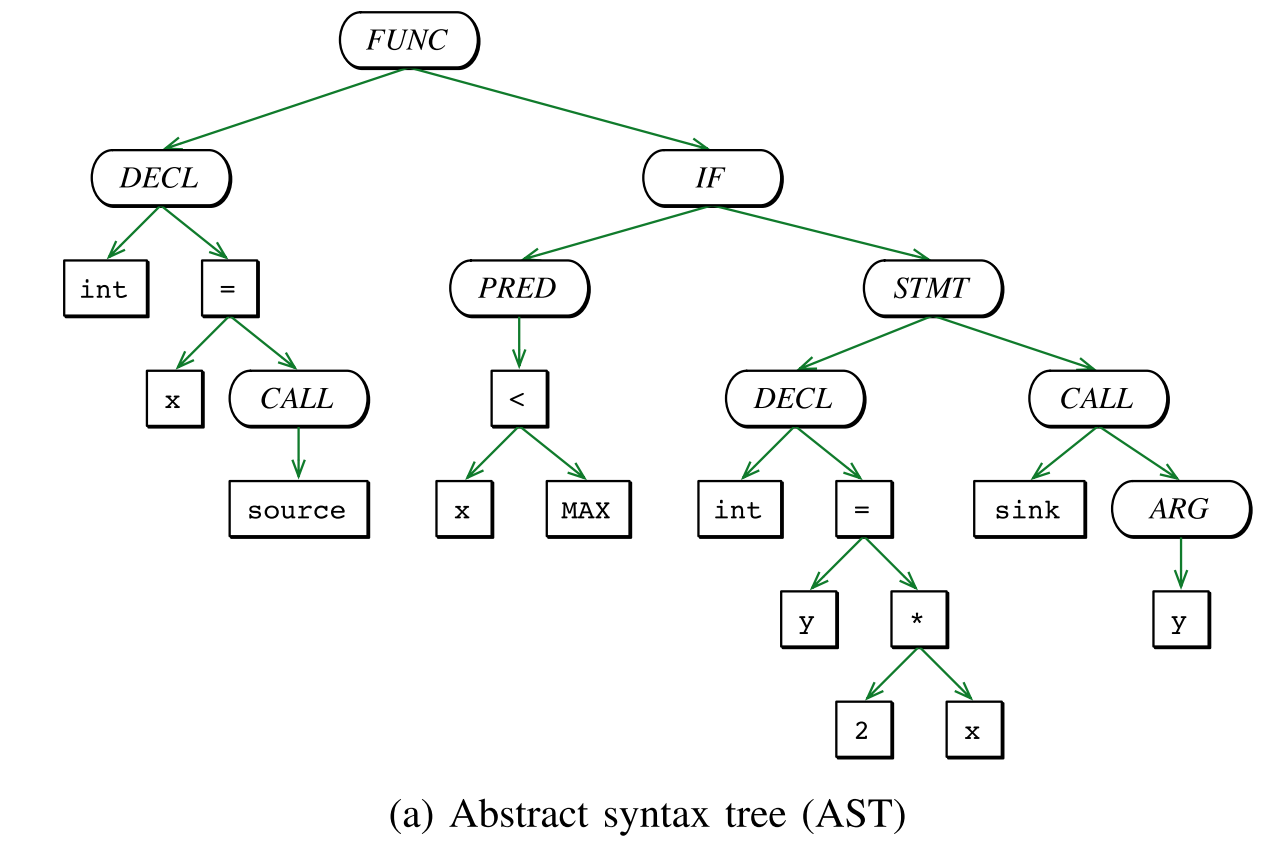
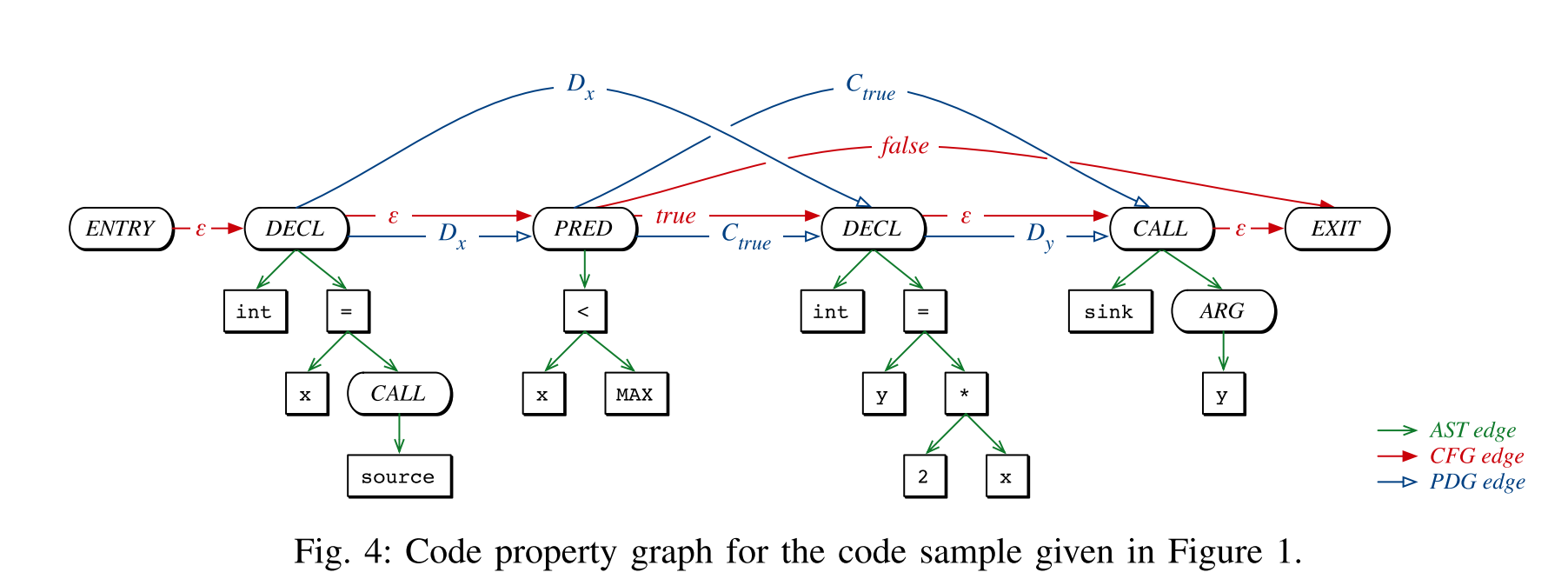
本文关注于三种代码表示:抽象语法树(AST)、控制流图(CFG)以及程序依赖图(PDG),以图1为例作说明

A. AST
抽象语法树通常作为编译器分析器产生的第一个中间表示,它如实编码了 statements 和 expressions 是如何嵌套生成程序的。与解析树相比,抽象语法树不再表示为表达程序而选择的具体语法。
抽象语法树是一种有序树,其内部结点表示操作符,而叶子结点表示操作数。 虽然抽象语法树非常适合于简单的代码转换,并且已经被用来标识语义相似的代码,它们不适用于更高级的代码分析,例如检测死代码或未初始化的变量。原因在于这种形式的表示既没有明确表示控制流图,也没有明确的数据依赖关系。
B. CFG
控制流图明确地描述了代码语句的执行顺序以及触发特定执行路径所需满足的条件。为此,statements 和 predicates 由结点来表示,利用有向边连接来指示控制的转移。虽然这些边不需要排序,但需要指定 $true,false$ 或 $\epsilon$ 标签。特别地,statement 结点拥有标记为 $\epsilon$ 的出边,同时 predicate 结点具有对于其计算结果的 $ture,false$ 两条出边。控制流图可以从抽象语法树以两个步骤的过程构造:1. 结构化控制语句(例如,if、while、for)来构建初步控制流图;2. 通过额外考虑诸如goto、break和continue之类的非结构化控制语句来校正初步控制流图。
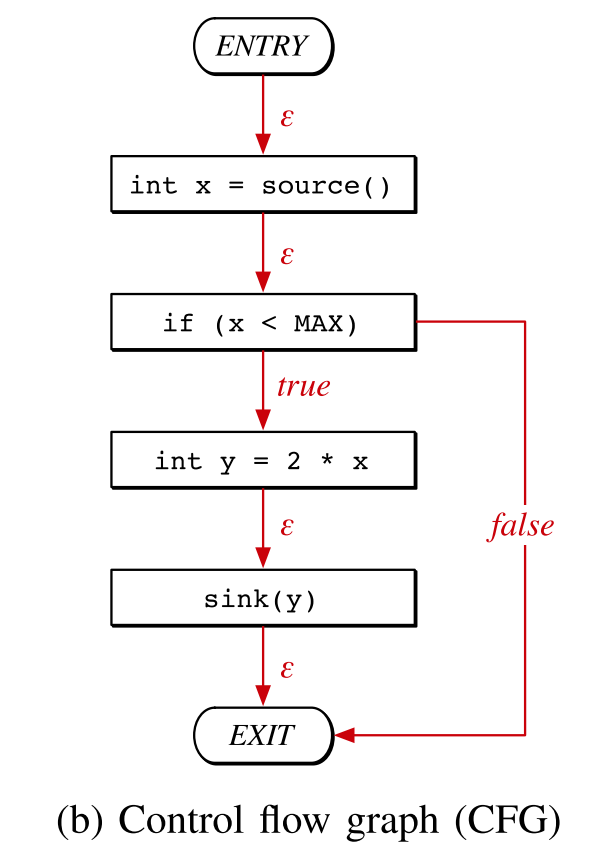
缺点在于控制流图不能提供数据流信息,在漏洞分析中这意味着不能识别到那些处理受攻击者影响数据的 statements
C. PDG
程序依赖关系图显式地表示 statements 和 predicates 之间的依赖关系。图由两种类型的边构建:数据依赖边反映变量之间的相互影响,而控制依赖边 predicates 对变量值的影响。程序依赖图边的构建可以通过控制流图首先确定每个 statement 定义的变量集和使用的变量集,然后计算每个 statement 和 predicate 的 reaching definitions。
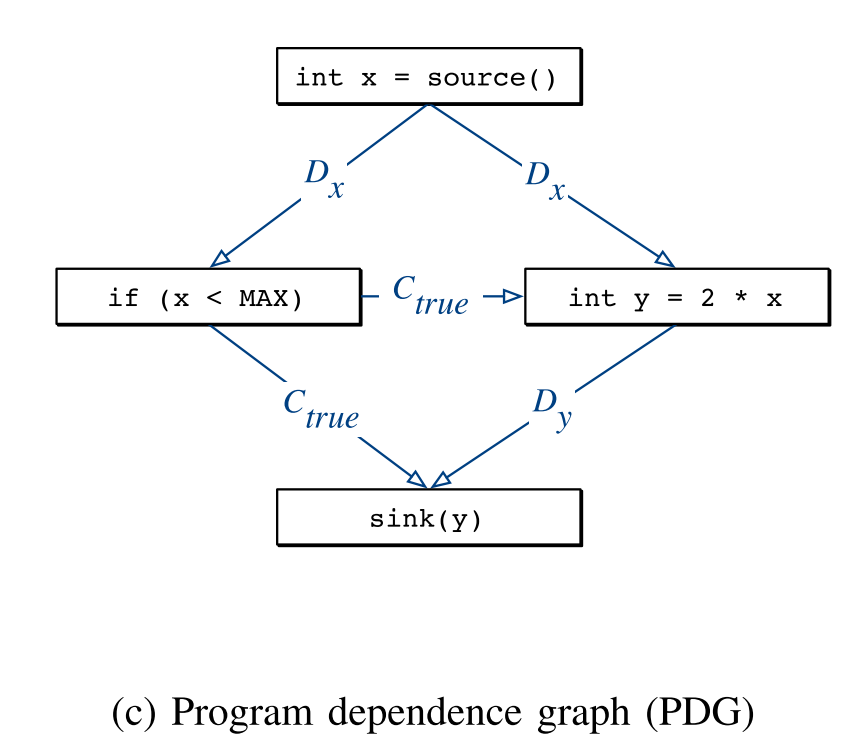
可以看到相比于 CFG,statements 的执行顺序不再能从图中确定,而 statements 和 predicates 之间的依赖关系却清晰可见。
- III. Property Graphs And Traversals
首先给出代码属性图的定义:
Definition 1. 属性图 $G = (V,E,\lambda, \mu)$ 是有向的、标记边的、具有多重属性图。其中 V 是一系列结点,E是有向边集合,且 $\lambda:E \to \sum$ 是一个边标记函数,其将来自字母表 Σ 的标记分配给每个边。属性可以通过函数 $\mu:(V\ \cup\ E) \times K\to S$ 来指定,其中 K 是属性的 key 集合,S 是属性的值集合。
图的遍历定义如下:
Definition 2. 图遍历是函数 $T : P(V) → P(V)$ ,其是结点到结点根据属性图 G 的映射,其中 P 是 V 的幂集。
这个通用定义允许我们将多个遍历连接起来,利用一个函数组合符号 $◦$.
首先我们先定义一个简单的过滤遍历:
它将返回所有集合 X 中匹配布尔谓词 p(v) 的结点。
前向分析:
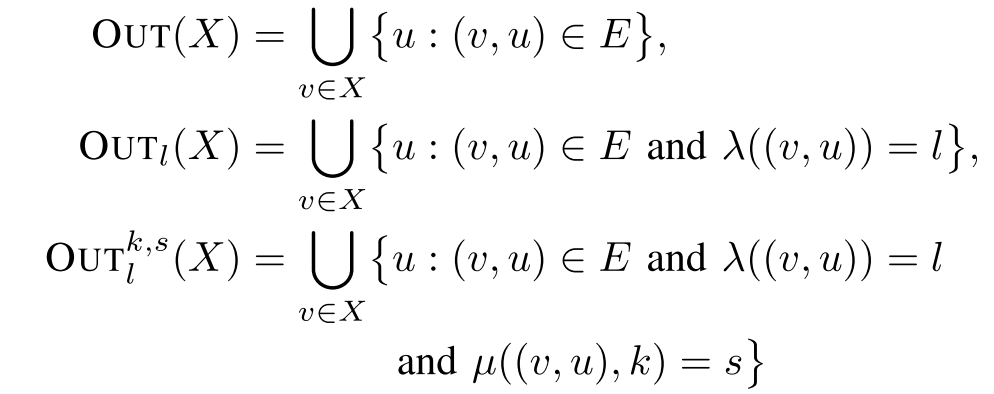
由上至下增加边标记以及属性的指定过滤。类似地后向分析如下:
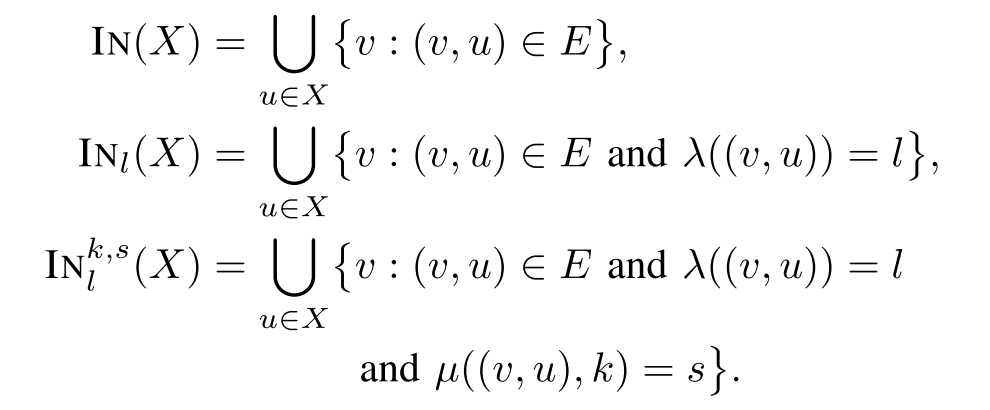
最后定义两种遍历 OR 和 AND 来将其他遍历的结果作聚合:
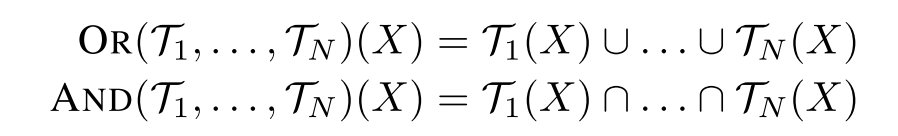
IV. Code Property Graphs
我们首先将 AST、CFG 和 PDG 建模为属性图,然后将它们合并成一个图,提供各个表示的所有优点
A. Transforming the AST
AST 提供提供源代码到语言结构的详细分解。我们将 AST 表达为 $G_A=(V_A,E_A,\lambda_A,\mu_A)$ ,其中 $V_A$ 代表树结点而边 $E_A$ 对应的是树中被标记函数 $\lambda_A$ 标记为 AST 的边。此外,我们使用 $µ_A$ 函数为每个节点分配一个属性 code,属性值就对应于节点所代表的运算符或操作数;最后,每个节点指定属性 order 以反映树的有序结构。
B. Transforming the CFG
我们将 CFG 表达为属性图 $G_C = (V_C,E_C,\lambda_C,·)$,其中结点 $V_C$ 对应 AST 中的 statements 和 predicates,也就是所有带有属性 code 对应值为 $STMT$ 和 $PRED$ 的结点 $V_A$. 另外定义边标记函数 $\lambda_C$ 来用集合 $Σ_C = \{true, false, \epsilon\}$ 标记属性图中的所有边。
C. Transforming the PDG
PDG 可以表示为属性图 $G_P = (V_C, E_P, λ_P, µ_P)$,其中定义一个新的边集合 $E_P$ 及 边标记函数 $\lambda_P: E_p \to \sum_P$ ,里面 $Σ_P = \{C, D\}$ 对应控制和数据依赖关系。另外,指定属性 symbol 给每一个数据依赖边来指示对应的符号;指定属性 condition 给每一个控制依赖来指定原始 predicate 的状态为 true 或 false。
D. Combining the Representations
构造此图所需的关键条件是,在这三个图中的每一个图中,源代码中的每个 statement 和 predicate 都存在一个节点。
Definition 3. 代码属性图是一个属性图 $G = (V, E, λ, µ)$ 由源代码中的 AST, CFG 和 PDG 构建而成,其中
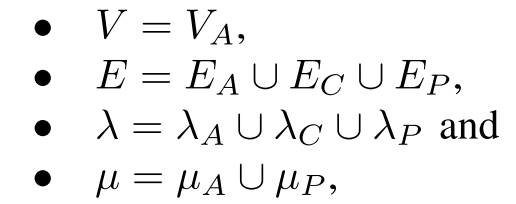
效果如下:
V. Traversals For Well-Known Types Of Vulnerability
这节要说明的是代码属性图可以有效的收集来识别不同类型的安全缺陷并形成可描述漏洞的模板。
A. Motivational Example
以 SSH实现中的缓冲区溢出为例,最初用的正则表达式来发现的

漏洞的 statement 利用了函数 LIBSSH2 ALLOC 来为缓冲区 exit_signal 分配内存,分配内存量直接由参数变量 namelen + 1 表示。由于这个参数可控,只要指定其为32位无符号整数的最大值,求和结果将会翻转并将0传入分配函数,这将导致对缓冲区仅分配几个字节的填充。当 namelen 个字节被复制到过小缓冲区中时,则将产生缓冲区溢出漏洞。
正则表达式的描述如下:
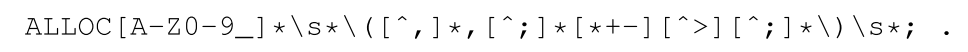
它的缺陷在于它只能用来描述分配内存的调用中的求和部分,而它只是漏洞产生的必要条件之一。由于正则表达式无法匹配代码的嵌套结构,因此描述本身就很模糊。实际上这种方式最大的缺陷在于无法对攻击者可以控制变量 namelen 进行建模。其次,如果变量被合理的净化了,漏洞也将不存在。最后,变量的范围对于漏洞至关重要。
因此,要想描述漏洞模式,以下方面需要涉及到:
- 敏感操作。安全敏感操作,如调用受保护的功能、复制到缓冲区或内存分配都需要可描述
- 类型使用。许多漏洞与程序中使用的数据类型紧密相关。这个信息会在 AST 中展示
攻击者可控。分析人员必须能够表示哪些数据源处于攻击者的控制之下。为了对此进行建模,需要 PDG 所表示的数据依赖关系
净化。最后,许多漏洞只有在程序没有对攻击者控制的数据进行适当的过滤时才会出现。因此,对 CFG 所表示的语句顺序进行建模至关重要
B. Syntax-Only Vulnerability Descriptions
AST 能描述攻击者可控的 sources、敏感操作以及 sanitizers,但是不能捕获 statements 之间的相互作用。就上图例子而言,漏洞的产生关键属性是求和直接发生在分配函数的参数中,因此带来两个挑战:
- 判断函数是否包含求和以及调用
- 捕获临近的代码结构
对于第一个问题,需要遍历所有函数节点并过滤出其中所有拥有调用或求和出来的,这又会带来一个重复遍历 AST 树的问题。解决方法就是通过定义一个可重用遍历 TNODES ,其可以从 AST 的根节点遍历至所有节点。TNODES + 过滤的结果即可让我们立即判断出 AST 中是否包含目标节点。形式化表达如下:
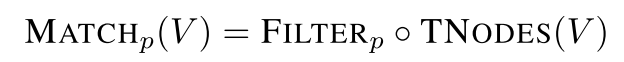
遍历以所有 $v ∈ V$ 为根的 AST 中包含的所有节点,并根据 predicate p 过滤这些节点。因此如果要定位分配函数,只需运行 MATCHp(V) 遍历所有函数节点,谓词判断是否为分配函数。
第二个问题在于识别嵌套在调用参数内的求和,只需再前面的基础上增加一个 $ARG_f^i$ ,它是 $MATCH$ 遍历返回的调用名为 f 的函数第 i 个参数,如果 µ(v,code) = Summation 为真则 $p(v)$ 为真。
下面是一些漏洞类型通过 $MATCH$ 遍历的描述:
Insecure arguments
对于格式化字符串漏洞产生的必要条件是传递到
printf/sprintf/fprintf这样函数的格式化字符串非常量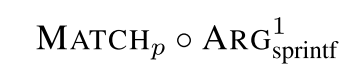
谓词条件是 $µ(v, code)\neq String$
Integer overflows
形式化描述如下:
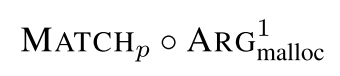
谓词判断 v 是否为算数运算
Integer type issues
以整数截断为例,其产生于赋值语句右边的变量类型存储大于左边的变量类型。这里我们需要通过遍历赋值语句左右两边的子树,为此定义函数 $PAIRS_{T_1}^{T_2}$,$PAIRS$ 将执行两个独立的遍历 $T_1$ 和 $T_2$ ,将两边遍历的结果组合进一步用类似的过滤函数 $PAIRFILTER_p$ 筛选符合 predicate p 的组合
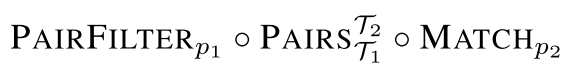
$p_1$ 为真当且仅当第二个结点代表的变量类型大于第一个结点类型;$p_2$ 为真当且仅当结点为赋值语句;最后 $T_1$ 和 $T_2$ 分别遍历赋值语句的左右子树
我们也可以通过 $AND$ 和 $OR$ 连接符来组合不同的 $MATCH$ 遍历
Definition 4. 纯语法漏洞描述 S 是一个2元组 $(M_0,M_1)$,其中 $M_0$ 和 $M_1$ 是 $MATCH$ 遍历的集合。如果 AST 节点与 $M_0$ 中的所有 $MATCH$ 遍历都匹配,但与$M_1$ 中的任何遍历都不匹配,则该节点与 syntax-only 描述匹配
这种表示缺陷在于无法表达攻击者的控制或者 statements 的交互。
C. Control-Flow Vulnerability Descriptions
控制流边可以建模出 statement 的执行顺序。漏洞对应的是控制流图中的路径,如下即可描述出来:
- Resouce leaks 资源释放不当
- Failure to release locks 并发锁未释放
- Use-after-free vulnerabilities 代码访问已释放的内存区域
用如下定义作描述:
Definition 5. 基于控制流的漏洞描述用四元组来表示:$(S_{src}, Send, S_{dst}, \{(S^i
_{cnd}, t_i)\}_{i=1…N})$ , 其中 $S_{SRC}$ 是对 source statements 的语法描述, $S_{end}$ 则为 end-statements。$S_{dst}$ 负责目的 statements,而 $\{(S^i_{cnd},t_i)\}_{i=1…N}$ 是一个对条件和关联输出 $t_i \in \{true, false\}$ 的基于语法的描述列表。
结点 v 匹配漏洞描述的条件如下:
AST 中以 $v_{SRC}$ 为结点的子树要匹配 $S_{SRC}$
存在一条路径从 $v_{SRC}$ 到 $S_{end}$ ,但中间不经过 $S_{dst}$ 节点
- 如果对于所有 $1\leq i \leq N$,存在节点匹配所有描述 $S^i_{cnd}$ ,则必须将源自该节点的路径的所有边标记为 $t_i$
执行一遍深度优先遍历即可作一次控制流漏洞描述匹配。缺陷在于仍无法追踪攻击者控制的数据
D. Taint-Style Vulnerability Descriptions
每一个 statements 节点的输入数据流边来自所有可达的赋值语句和变量的定义处,我们只需沿着这些数据流边即可遍历所有产生有用变量的 statements。特殊在于如果想要遍历从某个函数调用的参数到它对应的产生点,则需要先从临近的 statement 开始遍历。则变量的产生点可有下面的遍历计算得到:
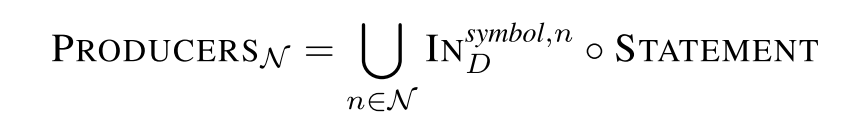
其中 N 是一系列关注点的标识符,它允许我们限制分析变量的范围。
为了方便又设计了一个遍历 SOURCES ,它结合了敏感操作的语法描述和一些数据源来判断攻击者可控的数据被用于敏感操作。
这里的一个问题是我们还没有考虑的 sanitizers 在里头的作用。但是如果仅添加额外的语法描述的话,则未关注到语句执行的顺序。为此我们需要结合控制流和数据流信息。
因此我们替换 $SOURCES$ 遍历改为 $UNSANITIZED$ ,额外允许指定 symbol 且基于语法的 sanitizer 描述 $S^S_{val}$, 符号 s 用来排除所有变量被合理净化的情况。
也就是说如果遍历能返回攻击者可控的 sources 需要满足:
- 存在 source 到 sink 的路径且不会匹配任何 sanitizer 的描述
- source 定义的变量如果可达 sink 点,中间不能被重定义
Definition 6. 污点风格的漏洞描述是一个三元组 $(S_{src},S_{dst},S_{san}^s)$,$S_{src}$ 为基于语法的攻击可控的 sources 点描述,$S_{dst}$ 为安全敏感 sinks,$S_{san}^s$ 为一系列基于语法的 sanitizers 描述。结点 v 的匹配原则为如果以 v 为根的AST 包含一个以 $v_{source}$ 为根结点的子树且可以匹配 $S_{src}$,并且另一颗以 $v_{sink}$ 为结点的子树匹配 $S_{dst}$,还需满足:
- 存在一条数据依赖路径从 $v_{source}$ 到 $v_{sink}$,也就是结点序列 $(v_0,\dots,v_n)$ 满足 $v_0=v_{source},v_n=v_{sink},e_i=(v_i,v_{i+1})\in E$ 且 $\lambda(e_i)=D\ for \ all\ i=0,\dots,n-1$
- 对于每一个上述数据依赖边 $e_i=(v_i,v_{i+1}),$ 从 $v_i$ 到 $v_{i+1}$ 存在控制流图中的一条路径 $(v_0,\dots,v_m)$ 对于所有 k,$0\leq k\leq m$,$v_k$ 都没有定义属性 $\mu(e_i,symbol)$ 并且 $v_k$ 也不会匹配 sanitizer $S_{san}^{\mu((v_i,v_{i+1},symbol))}$
利用 Definition 6 对常见漏洞类型作形式化表达
Buffer overflow

通过连接上 $UNSANITIZED$ 遍历,我们便可以将漏洞遍历扩展至对于间接污点遍历的追踪
Code injection

Missing permission checks

VI. Evaluation
研究对象:Linux kernel 源代码
步骤:
- 调研已发现的所有漏洞,并筛选所有可以利用图遍历建模的漏洞类型
- 通过构建普遍存在的漏洞图遍历,并应用在 Linux kernel 的代码属性图上进行效果评估
A. Implementation
代码属性图的构建:
- 利用语法分析器提取源代码中每个函数的 AST
- 将 ASTs 转换为 CFGs 和 PDGs,然后将这三种表示合并为代码属性图
- 引入一些全局变量和结构声明结点
- 基于 caller-callee 关系可视化展示
遍历代码属性图依靠图数据库,这里以 Neo4J Version 1.9.5 为例
图数据库语言选择 Gremlin 来实现图的遍历,它支持用户自定义的遍历插件,机制类似于 SQL 的存储程序
B. Coverage Analysis
团队首先从到2012年为止收录的所有 CVE 编号中找到了88个针对 kernel 的漏洞,并将其划分为12个常见类型,如下图所示

为了评估分析表示的覆盖率,设置对照:单独 AST、AST+PDG结合、AST+CFG结合、代码属性图,分析结果如下:
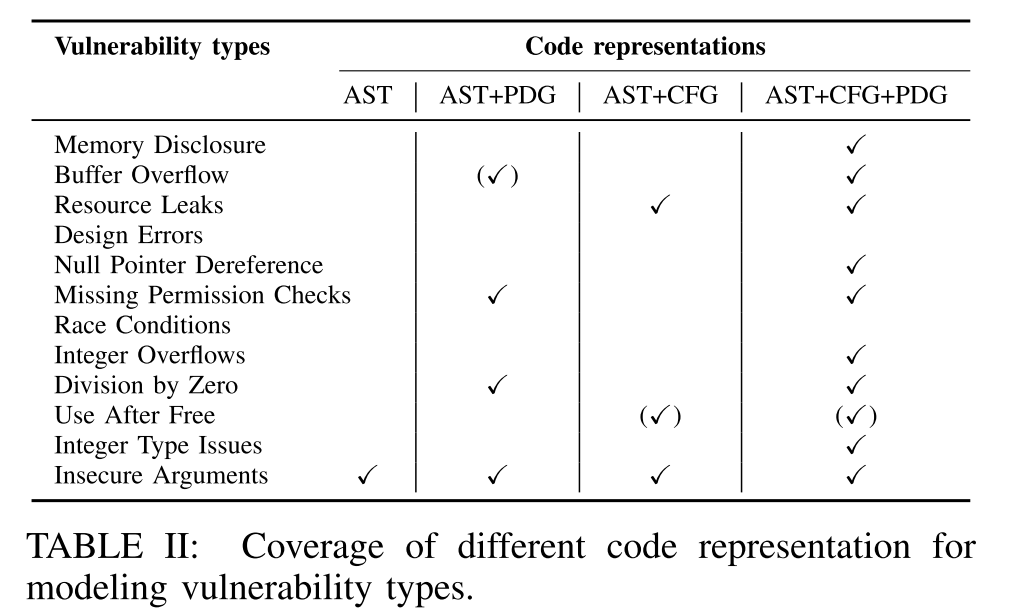
这里看到代码属性图无法针对 Race Conditions 以及 Design Errors 进行识别,原因在于前者依赖于运行时属性,而后者无法对程序的设计意图进行建模
C. Discovery of Vulnerabilities
Buffer overflows
构建遍历基于漏洞原理:对攻击者可控的长度字段未作检验,细节参考 VI-D
Memory disclosures
漏洞原理是不合理的初始化结构被用户空间所占用。挖掘通过构建污点风格的遍历,从结构的本地声明处到复制到用户空间的操作,中间不经过
memset函数。另外,还会去查看结构类型并使用基于语法的描述来判断所有结构的字段是否被赋值Memory mapping
对于 kernels 来讲该漏洞更具针对性,需要确保用户不能将任意物理地址映射至用户空间,以避免敏感信息的泄漏以及代码执行。我们构建了基于语法的漏洞描述规则来识别,表现出来代码属性图的方法对于挖掘程序指定漏洞来言非常适配。
Zero-byte allocations
与上面的案例类似,也是程序指定漏洞。源于分配函数接收了一个零字节长度字段,导致分配函数返回错误而使得 Linux Kernel 崩溃。我们这里构建的是基于污点风格的遍历。
结果如下:

D. Case Study:Buffer Overflow Identification
从前面已知污点风格的描述可以如下:
为此,我们只需要定义合适的遍历 $T_0$ 来定位攻击者可控的 sources,$T_1^s$ 定位 sanitizers 以及 $T_2$ 来定位安全敏感的 sinks
sources: 指定应用,需要人工检查
User/kernel space interfaces
可以使用多种 API 函数将数据从用户空间复制到内核空间
Parameters of system call handlers
攻击者通过调用相应的系统调用,直接控制系统调用处理程序的参数
sinks:
copy_from_user
memcpy
均关注第三个参数,谓词表示也就是:
$T^0_2 = ARG^3_{memcpy}$ 和 $T^1_2 = ARG^3_{copy_from_user}$
sanitized 触发条件:
- Dynamic allocation of the destination buffer
- Relational expressions
因此用谓词定义即 $OR(V_0^S,V_1^S)$ ,其中 $V_0^S$ 匹配第一个参数包含 s 的分配函数,$V_1^S$ 匹配关系表达式和调用了包含 s 的 min 函数。最终遍历表达式即:
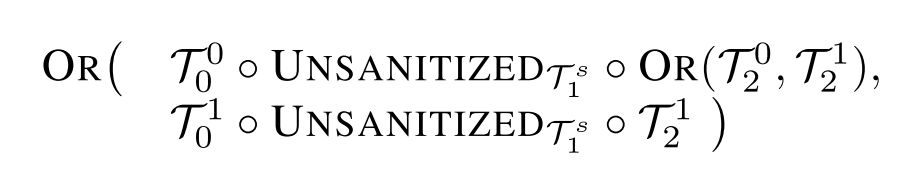
VII. Limitations
- 虽然实现了控制流和数据流追踪,但是并未解释代码。因此运行时行为产生的漏洞无法用代码属性图进行建模
- 只能发现潜在的漏洞代码(不可判定)
- 当前实现并未处理过程间程序分析
相关
M. Martin, B. Livshits, and M. S. Lam. Finding application errors and security flaws using pql: Program query language. In Proc. ofACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages and Applications (OOPSLA), 2005