《Toss a Fault to Your Witcher - Applying Grey-box Coverage Guided Mutational Fuzzing to Detect SQL and Command Injection Vulnerabilities》论文笔记
最后更新时间:
Toss a Fault to Your Witcher: Applying Grey-box Coverage Guided Mutational Fuzzing to Detect SQL and Command Injection Vulnerabilities
Grey-box / Coverage Guided / Mutational Fuzzing
概要
黑盒 web 应用漏洞扫描器试图在不访问源代码的情况下自动识别 web 应用中的漏洞。然而,他们通过使用人工管理的易受攻击的输入列表(POC)来实现这一点,这显著降低了黑盒扫描器探索 web 应用的输入空间的能力,并且这可能导致漏报。此外,黑盒扫描程序必须尝试推断触发了漏洞,这会导致误报。
为了克服这些限制,受到灰盒覆盖引导 Fuzzing 的启发,提出新型 web 漏洞检索框架——Witcher. Witcher 实现了 fault escalation 的概念,可用来检测 SQL 和 命令注入漏洞。
另外,Witcher 会捕获代码覆盖信息并且创建了以输出派生的输入指导来注重输入的生成,进而增加对 web 应用状态空间的探索。通过实验,Witcher 无论是在发现的漏洞数量方面,还是在 Web 应用程序的代码覆盖率方面,都优于最先进的扫描程序
1. Introduction
前人的一些漏洞自动化检测工作主要分为白盒、黑盒和灰盒三种技术,主要受制于应用的语言、漏洞类型和输入。
白盒:首先要拿到源码,其次对特定语言进行具体建模。不适于新的语言和框架

黑盒:通过输入 POC 来推断漏洞的存在性(预配置),也就是使用的硬编码形式的诱导输入,这将会减少探索 web 应用输入空间的能力,产生漏报。其次,仅通过输出响应来推断是否触发漏洞将会产生误报

灰盒:使用覆盖信息来指导输入的生成。它模糊了白盒以及黑盒的界限,其使用强度较低的静态或动态分析形式
现有技术缺点在于:仅针对单一语言、无法检测 SQL 注入或命令执行漏洞、闭源系统并且性能相对低下

本文思想:通过使用代码覆盖信息来有效地引导随机输入的生成,来探索 web 应用的输入空间(而不仅仅依赖于硬编码(POC)的试探法),很像有限自动状态机
挑战:我们所关注的 web 应用代码也就是被测目标只是整个执行对象的一部分,这将会导致灰盒 Fuzz 受到其他部分如代码执行环境(解释器或虚拟机)的干扰
支持 Web 应用的自动化 Fuzzing
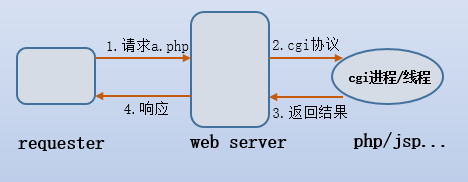
- 如何检测 SQL 和命令执行漏洞是否被触发?
- 如何生成有效的输入(语法和语义都合理)进行 Fuzz?HTTP请求格式 / 参数名
- Web 注入漏洞的增强
- 如何收集 web 应用的代码覆盖信息(可扩展且具有独立性)?传统插桩会受到解释器代码的干扰
- 如何设计一个高效的输入变异策略来增加 fuzz 的有效性?传统的策略并未利用客户端提供的上下文信息
贡献:
- 创造了一系列技术来处理在 web 应用使用灰盒覆盖引导 fuzz 的挑战,并给出了框架
- 开发 Witcher fuzz 工具,可以自动化分析服务器端二进制程序和解释型语言编写的 Web 应用程序来检测 SQL 注入、命令执行和内存中断漏洞(仅针对基于C的 CGI 二进制文件)
- 通过不同方面开展实验评估
2. Coverage-Guided Fuzzing
思想:将输入种子置于测试用例队列,并根据不同的变异策略产生新的输入加入到队列中。覆盖引导式的变异策略会利用代码覆盖信息来近似程序执行的状态(覆盖信息可通过静态或动态技术来获得),进而指导测试输入的选择。当输入使得程序到达一个新的状态或者导致错误信号响应,则会对该输入进行标记
3. Witcher’s Design
实现组件 Fault Escalator / HTTP Harness / Request Crawler 以支持 web 注入漏洞 fuzz;实现组件 Request Crawler / Request Crawler 以增强 web 注入漏洞 fuzz
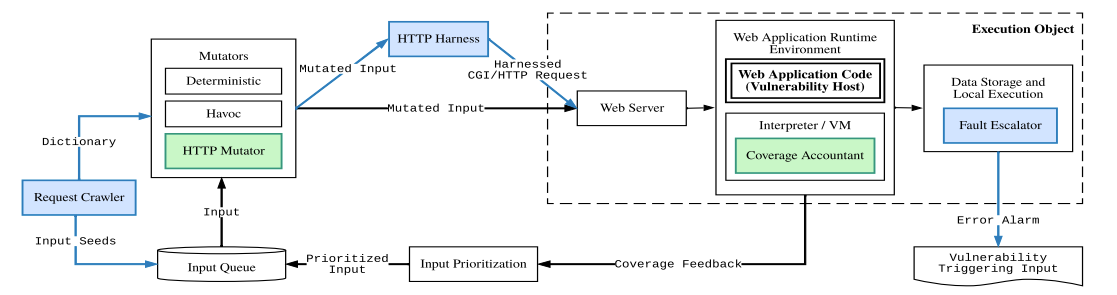
Fault Escalator
类似于二进制 fuzzers 通过检测 segmentation fault 信号来判断漏洞状态,Witcher 利用的是语法错误来判断 SQL 注入:如果攻击者控制的输入导致外部解析器中出现语法错误,则攻击者可以更改命令,很可能存在可利用的漏洞,在实现上
LD_PRELOAD模块来 hook libc 库中的 recv 函数。对于命令执行漏洞,直接用的 dash 命令行解析器(增强解析错误)。当错误发生时,Fault Escalator 就会将其提升为 segmentation fault,指示当前测试输入导致了程序进入漏洞状态。进一步通过判断是否可被利用来验证是漏洞还是 bug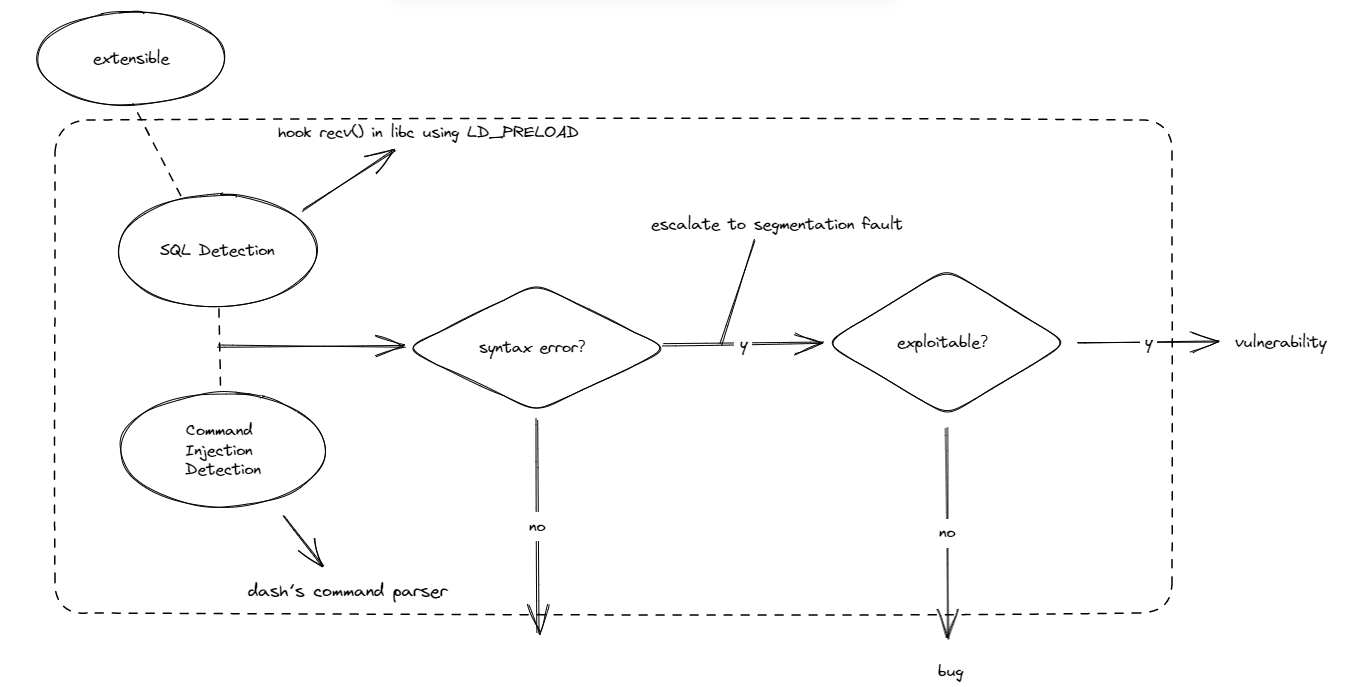
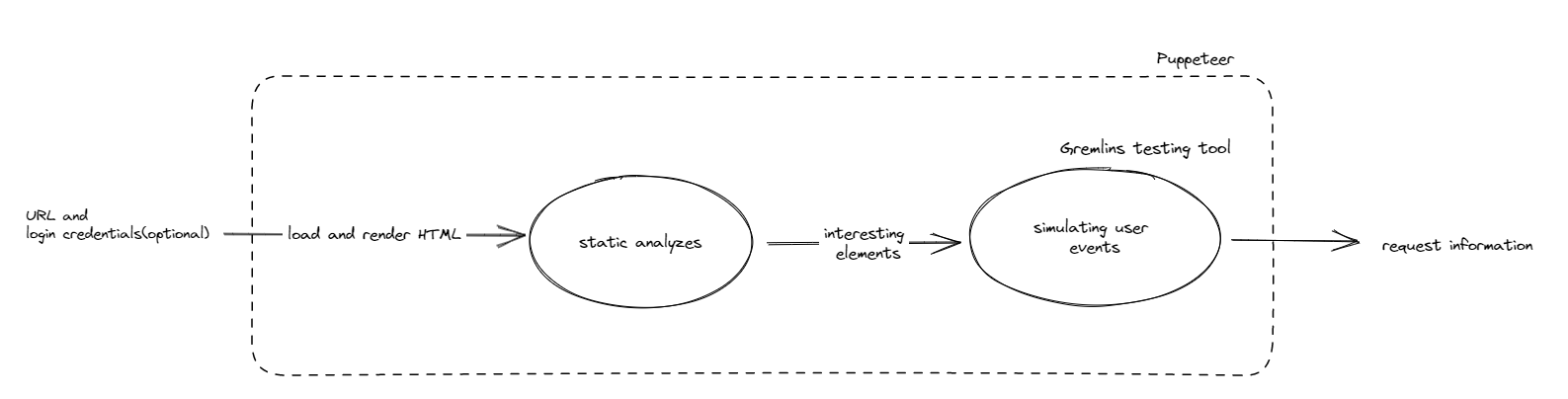
Request Crawler
Reqrle 类似黑盒扫描的爬虫,给定入口 URL 或者可选的登录凭据参数,利用 [Puppeteer][https://github.com/puppeteer/puppeteer] 来模拟用户的行为并捕获请求。首先是静态分析渲染出的 HTTP 页面,识别每一个创建 HTTP 请求或者参数的元素;然后利用测试工具 Gremlins 系统、随机地模拟用户事件并监听 HTTP 请求
Request Harnesses
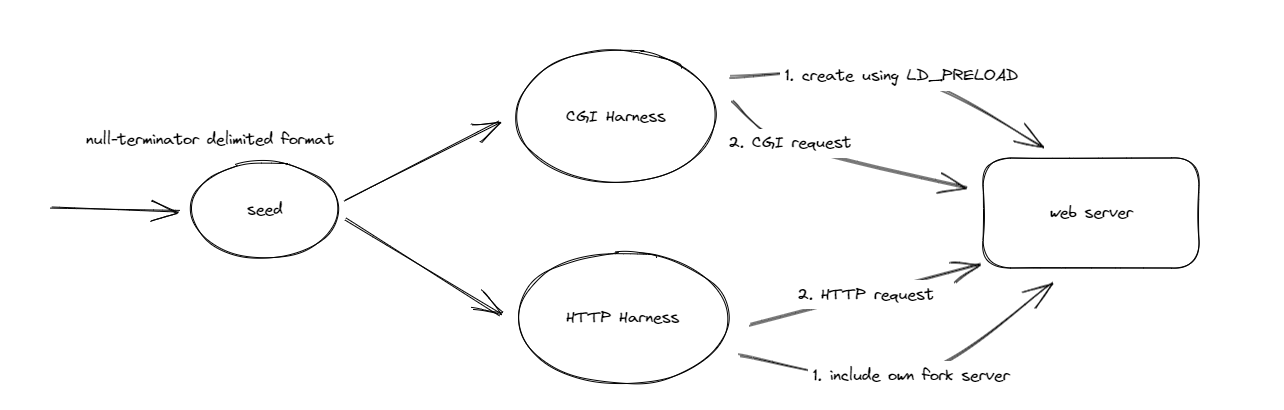
会将 fuzzer 生成的输入转换成合法的请求,对于 PHP 和 CGI 脚本编写的 web 应用转换成 CGI 请求;对于 Python \ Node.js \ Java \ 基于 QEMU 的二进制文件转换成 HTTP 请求。
CGI Harness
使用 LD_PRELOAD 来创建一个分支服务器,在处理输入之前启动解释器或二进制文件。harness 将会接收每一个新输入,将其转换为 CGI 请求并传给新创建的子进程。
HTTP Request Harness
将目标平台与 fuzzer 分离,使得能够在它不自动支持的应用程序上工作
特点:对每个 fuzzer 实例都会保持请求路径,意味着一次只会 fuzz 单一的 URL
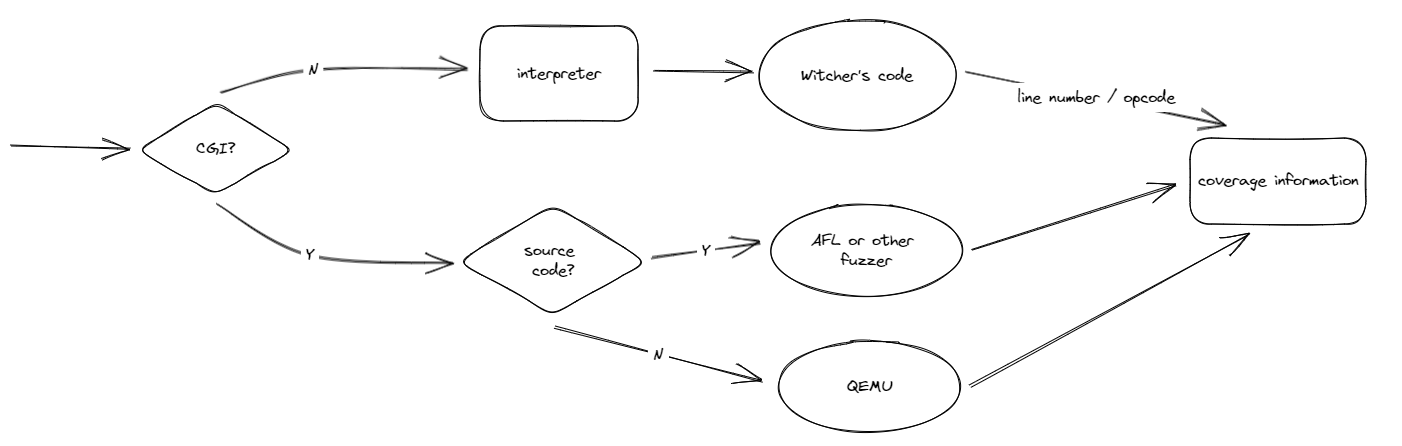
Coverage Accountant
并未采用传统针对解释器插桩的技术,因为这将会产生大量噪声。Coverage Accountant 置于解释器中,调用并覆盖库函数。其会接收行号、字节码以及当前字节码的执行参数并利用它们来更新 fuzzer 的覆盖信息。对于 CGI 二进制文件,如果二进制源码可得就用 AFL 插桩,否则通过 QEMU 动态插桩。除此之外,Witcher 支持与更先进的 fuzzer 进行结合
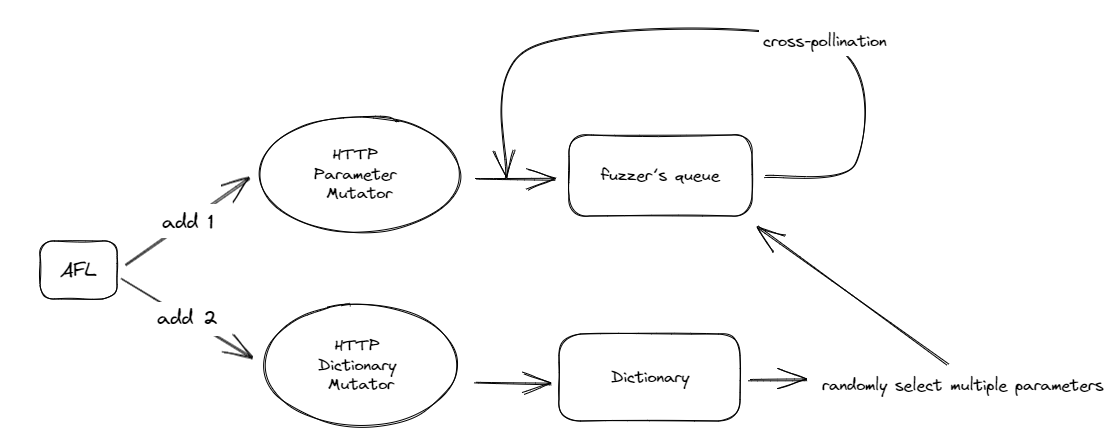
HTTP-specific Input Mutations
在 AFL 的基础上添加了两个变异阶段,来重点操作 HTTP 参数。
HTTP Parameter Mutator:对 fuzzer 的队列中的测试样本随机搭配参数名和值(进而产生新的测试输入),由于不同样本参数之间的相关性。这种策略能提供比随机字节变异更可能触发新的执行路径的目标测试输入
HTTP Dictionary Mutator:这里是考虑了一个应用节点可能有多个使用不同 HTTP 变量的请求。首先将 Reqr 模块获得的 HTTP 参数放入 fuzz 字典,随机选择1到10个变量并加入到当前测试输入中,以利用相似性变量匹配尽可能匹配当前请求。这样减少了当前输入与字典中的变量配对所需的执行次数
缺陷:
能探测的漏洞类型有限,可以进一步探索文件包含、目录穿越以及 XSS
无法检测二次注入类型的漏洞,因为无法判断对应的输入是什么
原因:没有维护应用程序的状态,只能通过应用程序数据库的状态