算法提升——哈希篇
最后更新时间:
数据结构复习-哈希篇
HashMap 底层原理
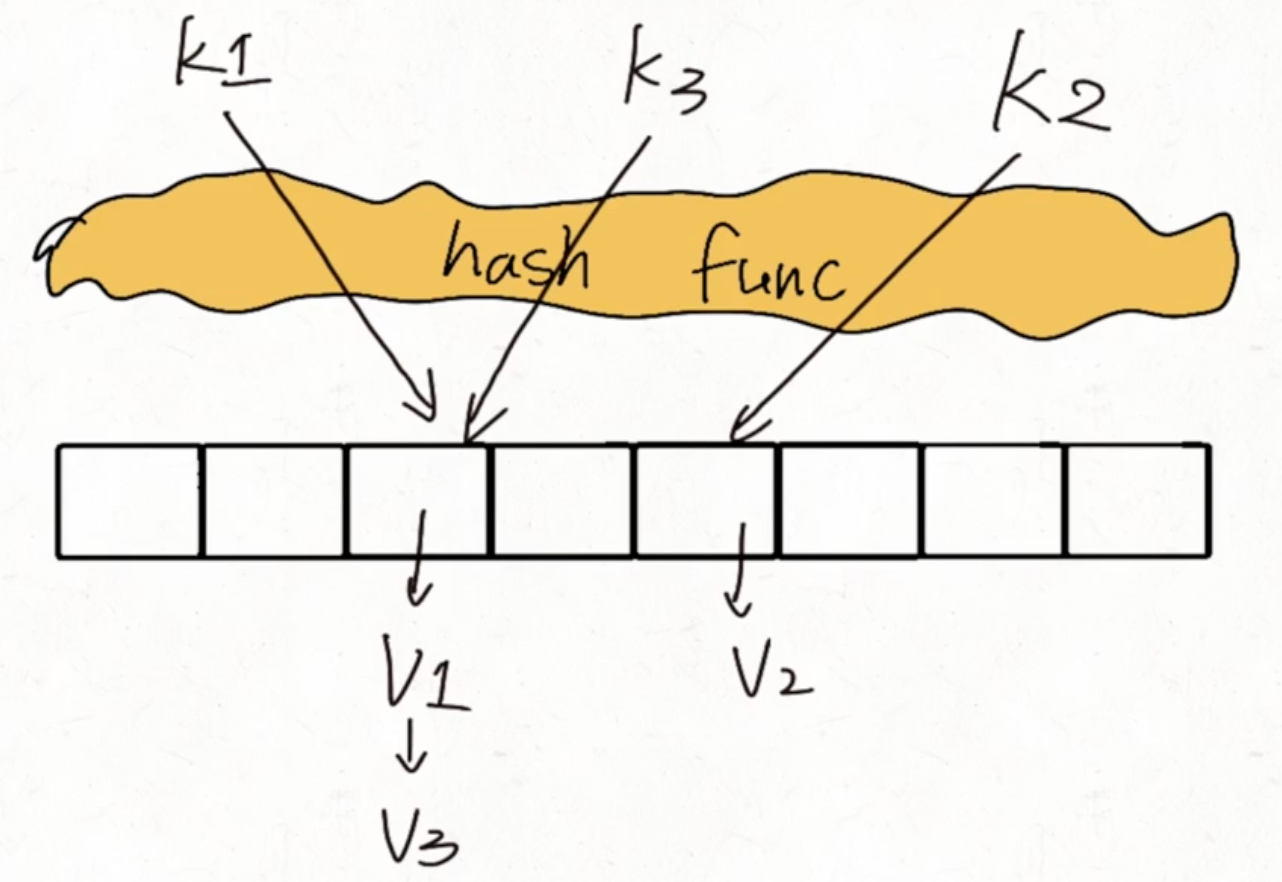
由数组和哈希函数构成,后者计算出元素的索引存在对应数组的位置中。
拉链法解决哈希冲突
当计算出来的索引相同时,即出现哈希冲突,就通过维护一个链表将所有同索引的元素(K, V 对)串起来
-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83class MyHashMap {
private class Pair {
private int key;
private int val;
public Pair(int key, int val) {
this.key = key;
this.val = val;
}
public int getKey() {
return key;
}
public int getVal() {
return val;
}
public void setVal(int val) {
this.val = val;
}
}
private LinkedList[] table;
public MyHashMap() {
table = new LinkedList[759];
for (int i = 0; i < table.length; i++) {
table[i] = new LinkedList<Pair>();
}
}
public void put(int key, int value) {
LinkedList<Pair> p = table[hash(key)];
Iterator<Pair> iter = p.iterator();
while (iter.hasNext()) {
Pair entry = iter.next();
if (entry.getKey() == key) {
entry.setVal(value);
return;
}
}
p.addLast(new Pair(key, value));
}
public int get(int key) {
LinkedList<Pair> p = table[hash(key)];
Iterator<Pair> iter = p.iterator();
while (iter.hasNext()) {
Pair entry = iter.next();
if (entry.getKey() == key) {
return entry.getVal();
}
}
return -1;
}
public void remove(int key) {
LinkedList<Pair> p = table[hash(key)];
Iterator<Pair> iter = p.iterator();
while (iter.hasNext()) {
Pair entry = iter.next();
if (entry.getKey() == key) {
p.remove(entry);
return;
}
}
}
private int hash(int key) {
return key % table.length;
}
}
/**
* Your MyHashMap object will be instantiated and called as such:
* MyHashMap obj = new MyHashMap();
* obj.put(key,value);
* int param_2 = obj.get(key);
* obj.remove(key);
*/
-
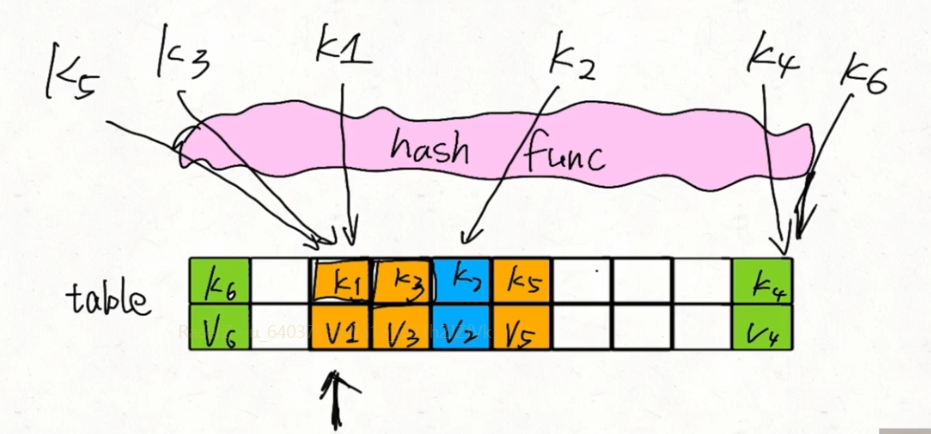
线性探查法解决哈希冲突
当哈希计算得到的索引已被其他元素占有时,就线性后移直至找到一个空位置插入元素(移到最后一个元素的话就重新从第一个元素开始)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183import java.util.LinkedList;
import java.util.List;
import java.util.Map;
public class MyHashMap23<K, V> {
private static class Node<K, V> implements Map.Entry<K, V> {
K key;
V val;
Node(K key, V val) {
this.key = key;
this.val = val;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return val;
}
@Override
public V setValue(V val) {
V oldVal = this.val;
this.val = val;
return oldVal;
}
}
// 真正存储键值对的数组
private Node<K, V>[] table;
// HashMap 中的键值对个数
private int size;
// HashMap 的容量,即 keys 和 vals 的 length
private int cap;
// 默认的初始化容量
private static final int INIT_CAP = 4;
public MyHashMap23() {
this(INIT_CAP);
}
public MyHashMap23(int initCapacity) {
size = 0;
cap = initCapacity;
table = (Node<K, V>[]) new Node[initCapacity];
}
/***** 增/改 *****/
// 添加 key -> val 键值对
// 如果键 key 已存在,则将值修改为 val
public V put(K key, V val) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
if (size >= cap / 2) {
resize(cap * 2);
}
int i = getNodeIndex(key);
// key 已存在,修改对应的 val
if (i != -1) {
Node<K, V> entry = table[i];
V oldVal = entry.val;
entry.val = val;
return oldVal;
}
// key 不存在,找个空位插入
i = hash(key);
while (table[i] != null) {
i = (i + 1) % cap;
}
// 此时 table[i] 为一个空位
Node<K, V> x = new Node<>(key, val);
table[i] = x;
size++;
return null;
}
/***** 删 *****/
// 删除 key 和对应的 val,并返回 val
// 若 key 不存在,则返回 null
public V remove(K key) {
// TODO
}
/***** 查 *****/
// 返回 key 对应的 val
// 如果 key 不存在,则返回 null
public V get(K key) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
int i = getNodeIndex(key);
if (i == -1) {
return null;
}
return table[i].val;
}
// 判断 key 是否存在 Map 中
public boolean containsKey(K key) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
return getNodeIndex(key) != -1;
}
/***** 其他工具函数 *****/
public List<K> keys() {
LinkedList<K> keyList = new LinkedList<>();
for (Node<K, V> entry : table) {
if (entry != null) {
keyList.addLast(entry.key);
}
}
return keyList;
}
public List<Map.Entry<K, V>> entries() {
LinkedList<Map.Entry<K, V>> entryList = new LinkedList<>();
for (Node<K, V> entry : table) {
if (entry != null) {
entryList.addLast(entry);
}
}
return entryList;
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
// 哈希函数,将键映射到 table 的索引
// [0, table.length - 1]
private int hash(K key) {
// int: 0000 0000 0000 ... 0000
// : 0111 1111 1111 ... 1111
return (key.hashCode() & 0x7fffffff) % cap;
}
// 对 key 进行线性探查,返回一个索引
// 若返回 -1 说明没有找到
private int getNodeIndex(K key) {
int i;
for (i = hash(key); table[i] != null; i = (i + 1) % cap) {
if (table[i].key.equals(key))
return i;
}
return -1;
}
private void resize(int newCap) {
MyHashMap23<K, V> newMap = new MyHashMap23<>(newCap);
for (Node<K, V> entry : table) {
if (entry != null) {
newMap.put(entry.key, entry.val);
}
}
this.table = newMap.table;
this.cap = newMap.cap;
}
}细节在于如何处理
remove()方法,这里有两种思路:将删除元素置空,并且为了防止后面哈希冲突元素无法被探查的,也需要将它们一并置空并重新放入,
put()方法将会把他们放在正确的位置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public V remove(K key) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
if (size < cap / 8) {
resize(cap / 2);
}
int i = getNodeIndex(key);
if (i == -1) {
// key 不存在,不需要 remove
return null;
}
// 开始 remove
V deletedVal = table[i].val;
table[i] = null;
size--;
// 保持连续性
i = (i + 1) % cap;
for (; table[i] != null; i = (i + 1) % cap) {
Node<K, V> entry = table[i];
table[i] = null;
// put 里面又会加一
size--;
put(entry.key, entry.val);
}
return deletedVal;
}删除结点时不置空,而是做一个特殊标记,来保证哈希冲突元素的连续性
特殊标志可由如下 dummy 表示
1
private final Node<K, V> DUMMY = new Node<>(null, null);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public V remove(K key) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
if (size < cap / 8) {
resize(cap / 2);
}
int i = getNodeIndex(key);
if (i == -1) {
// key 不存在,不需要 remove
return null;
}
// 开始 remove
V deletedVal = tables[i].val;
// 直接用占位符表示删除
tables[i] = DUMMY;
size--;
return deletedVal;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222import java.util.LinkedList;
import java.util.List;
import java.util.Map;
public class MyHashMap24<K, V> {
private static class Node<K, V> implements Map.Entry<K, V> {
K key;
V val;
Node(K key, V val) {
this.key = key;
this.val = val;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return val;
}
@Override
public V setValue(V val) {
V oldVal = this.val;
this.val = val;
return oldVal;
}
}
// TODO: 被删除的 Node 的占位符
private final Node<K, V> DUMMY = new Node<>(null, null);
// 真正存储键值对的数组
private Node<K, V>[] tables;
// HashMap 中的键值对个数
private int size;
// HashMap 的容量,即 keys 和 vals 的 length
private int cap;
// 默认的初始化容量
private static final int INIT_CAP = 4;
public MyHashMap24() {
this(INIT_CAP);
}
public MyHashMap24(int initCapacity) {
size = 0;
cap = initCapacity;
tables = (Node<K, V>[]) new Node[initCapacity];
}
/***** 增/改 *****/
// 添加 key -> val 键值对
// 如果键 key 已存在,则将值修改为 val
public V put(K key, V val) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
if (size >= cap / 2) {
resize(cap * 2);
}
int i = getNodeIndex(key);
if (i != -1) {
// key 已存在,修改对应的 val
Node<K, V> entry = tables[i];
if (entry != null) {
V oldVal = entry.val;
entry.val = val;
return oldVal;
}
}
// key 不存在,插入
Node<K, V> x = new Node<>(key, val);
// 在 table 中找一个空位或者占位符
i = hash(key);
// 不仅找空的,还可以找占位符
while (tables[i] != null && tables[i] != DUMMY) {
i = (i + 1) % cap;
}
tables[i] = x;
size++;
return null;
}
/***** 删 *****/
// 删除 key 和对应的 val,并返回 val
// 若 key 不存在,则返回 null
public V remove(K key) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
if (size < cap / 8) {
resize(cap / 2);
}
int i = getNodeIndex(key);
if (i == -1) {
// key 不存在,不需要 remove
return null;
}
// 开始 remove
V deletedVal = tables[i].val;
// 直接用占位符表示删除
tables[i] = DUMMY;
size--;
return deletedVal;
}
/***** 查 *****/
// 返回 key 对应的 val
// 如果 key 不存在,则返回 null
public V get(K key) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
int i = getNodeIndex(key);
if (i == -1) {
return null;
}
return tables[i].val;
}
// 判断 key 是否存在 Map 中
public boolean containsKey(K key) {
if (key == null) {
throw new IllegalArgumentException("key is null");
}
int i = getNodeIndex(key);
return i != -1;
}
// 对 key 进行线性探查,返回一个索引
// 根据 keys[i] 是否为 null 判断是否找到对应的 key
private int getNodeIndex(K key) {
int i;
int step = 0;
for (i = hash(key); tables[i] != null; i = (i + 1) % cap) {
Node<K, V> p = tables[i];
// TODO:遇到占位符直接跳过
if (p == DUMMY) {
continue;
}
if (p.key.equals(key)) {
return i;
}
step++;
// TODO: 防止死循环
if (step == tables.length) {
resize(cap);
return -1;
}
}
return -1;
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
public List<K> keys() {
LinkedList<K> keyList = new LinkedList<>();
for (Node<K, V> entry : tables) {
if (entry != null) {
keyList.addLast(entry.key);
}
}
return keyList;
}
public List<Map.Entry<K, V>> entries() {
LinkedList<Map.Entry<K, V>> entryList = new LinkedList<>();
for (Node<K, V> entry : tables) {
if (entry != null) {
entryList.addLast(entry);
}
}
return entryList;
}
// 哈希函数,将键映射到 table 的索引
// [0, table.length - 1]
private int hash(K key) {
// int: 0000 0000 0000 ... 0000
// : 0111 1111 1111 ... 1111
return (key.hashCode() & 0x7fffffff) % cap;
}
private void resize(int newCap) {
MyHashMap24<K, V> newMap = new MyHashMap24<>(newCap);
for (Node<K, V> entry : tables) {
if (entry != null && entry != DUMMY) {
newMap.put(entry.key, entry.val);
}
}
this.tables = newMap.tables;
this.cap = newMap.cap;
}
}
HashSet 底层原理
底层就是 HashMap, 复用的是它的键,因为键是唯一的(哈希冲突解决)。值直接用 dummy 作占位符即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import java.util.HashMap;
public class MyHashSet<K> {
// val 占位符
private static final Object PRESENT = new Object();
// 底层 HashMap
private final HashMap<K, Object> map = new HashMap<>();
public boolean add(K k) {
return map.put(k, PRESENT) == null;
}
public boolean remove(K k) {
return map.remove(k) == PRESENT;
}
public boolean contains(K k) {
return map.containsKey(k);
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}应用
-
首先,可以沿用之前双指针 + 维护索引的方法,即索引保存后数组排序,利用双指针扫描;麻烦点就在于可能出现相同的元素,这种情况 HashMap 无能为力,因此只能自己维护一个数据结构。这里的另一个思路就是直接保存值和索引映射在 HashMap 当中,边查边存,找 need = target - num。 对于两数之和肯定不会撞上。
1
2
3
4
5
6
7
8
9
10
11
12
13public int[] twoSum(int[] nums, int target) {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int need = target - nums[i];
if (map.containsKey(need)) {
return new int[] {map.get(need), i};
}
map.put(nums[i], i);
}
return null;
} -
这题考察点在深拷贝,可以利用 HashMap 来维护原结点和新结点的映射
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public Node copyRandomList(Node head) {
HashMap<Node, Node> map = new HashMap<>();
for (Node p = head; p != null; p = p.next) {
map.put(p, new Node(p.val));
}
for (Node p = head; p != null; p = p.next) {
Node tmp = map.get(p);
if (p.next != null) {
tmp.next = map.get(p.next);
}
if (p.random != null) {
tmp.random = map.get(p.random);
}
}
return map.get(head);
} -
作字符统计再比较即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public boolean isAnagram(String s, String t) {
int[] count1 = encodes(s);
int[] count2 = encodes(t);
for (int i = 0; i < count1.length; i++) {
if (count1[i] != count2[i]) {
return false;
}
}
return true;
}
private int[] encodes(String s) {
int[] count = new int[26];
for (char c : s.toCharArray()) {
count[c - 'a']++;
}
return count;
}
} -
这里利用 HashMap 来维护相同字符编码到字符串集合也就是字母异位词的映射,这里对于字符编码需要额外的处理,为了保证可比较,所以最后还是得转换为字符串的形式,需要计数的时候直接用
char[]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, List<String>> map = new HashMap<>();
for (String str : strs) {
// 得到每个字符串的编码值
String count = encode(str);
// 已存在的不执行
map.putIfAbsent(count, new LinkedList<String>());
map.get(count).add(str);
}
LinkedList<List<String>> res = new LinkedList<>();
for (List<String> value : map.values()) {
res.addLast(value);
}
return res;
}
// 需要做一些改造
private String encode(String s) {
char[] count = new char[26];
for (char c : s.toCharArray()) {
count[c - 'a']++;
}
return new String(count);
}
} -
HashMap 维护字符计数即可,寻找第一个字符计数为 1 的索引值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public int firstUniqChar(String s) {
int[] count = encode(s);
char[] p = s.toCharArray();
for (int i = 0; i < p.length; i++) {
if (count[p[i] - 'a'] == 1) {
return i;
}
}
return -1;
}
private int[] encode(String s) {
int[] count = new int[26];
for (char c : s.toCharArray()) {
count[c - 'a']++;
}
return count;
}
} -
这里可以不采用 HashMap 计数的方式,因为待求众数数量是大于一半的,因此联想正负电性混合起来的现象,采用 count 去吸引出众数也就是代表正电性的元素,最终该元素一定是使得 count 大于 0 的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public int majorityElement(int[] nums) {
int count = 0;
int target = 0;
for (int i = 0; i < nums.length; i++) {
if (count == 0) {
target = nums[i];
count++;
} else if (target == nums[i]) {
count++;
} else {
count--;
}
}
return target;
} -
常规哈希表做法,统计字符出现次数即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public char findTheDifference(String s, String t) {
int[] count1 = encode(s);
int[] count2 = encode(t);
for (int i = 0; i < 26; i++) {
if (count1[i] != count2[i]) {
return (char) (i + 'a');
}
}
return ' ';
}
private int[] encode(String s) {
int[] count = new int[26];
for (char c : s.toCharArray()) {
count[c - 'a']++;
}
return count;
}
}位运算法,将两个字符串逐位异或起来,最终的结果一定是新添加的字母
1
2
3
4
5
6
7
8
9
10
11
12public char findTheDifference(String s, String t) {
int res = 0;
for (char c : s.toCharArray()) {
res = res ^ c;
}
for (char c : t.toCharArray()) {
res = res ^ c;
}
return (char) res;
}
-
这题有个巧妙的做法,审题可以发现“长度为
n的整数数组nums,其中nums
的所有整数都在范围[1, n]内”,也就是说 nums 数组本身就可以看作是哈希表,其元素和索引存在着某种映射关系,对于出现两次的元素,其如果看作索引的话,一定会映射到相同的值上。因此可以对第一次出现的元素做个标记,在第二次检查标记PS:注意这里做标记是乘 -1,因为元素值均为正数,但是放在索引上时记得取绝对值方式负数越界
1
2
3
4
5
6
7
8
9
10
11
12
13
14public List<Integer> findDuplicates(int[] nums) {
LinkedList<Integer> res = new LinkedList<>();
for (int num : nums) {
if (nums[Math.abs(num) - 1] > 0) {
// 第一次出现
nums[Math.abs(num) - 1] *= -1;
} else if (nums[Math.abs(num) - 1] < 0) {
res.add(Math.abs(num));
}
}
return res;
} -
这题可以沿用上题的思路,标记所有出现过的元素(依然用 nums 自身做映射),对于没标记过的元素,就返回它的索引值
i + 1,也就是未出现过的数字1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public List<Integer> findDisappearedNumbers(int[] nums) {
LinkedList<Integer> res = new LinkedList<>();
for (int num : nums) {
if (nums[Math.abs(num) - 1] > 0) {
nums[Math.abs(num) - 1] *= -1;
} else {
continue;
}
}
for (int i = 0; i < nums.length; i++) {
if (nums[i] > 0) {
res.add(i + 1);
}
}
return res;
}
-
LinkedHashMap
特性:可以顺序访问所有 key
为什么 HashMap 无序?源于 hash 输出的随机性
LinkedHashMap 原理
多增加一个 LinkedList 来存储元素插入顺序
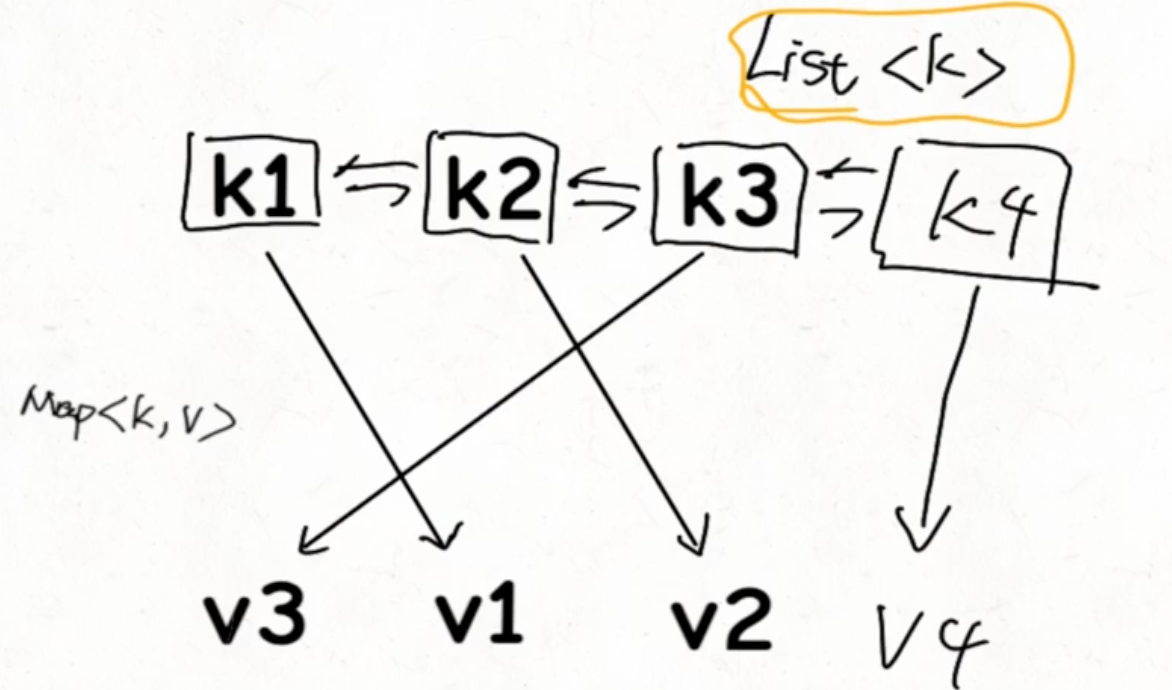
这里在删除元素时就会增加时间复杂度,因为链表本身需要先遍历索引找到对应的待删除节点。如果想以 O(1) 时间删除元素,则 HashMap 应改为维护索引到节点的映射
LinkedHashMap 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105import java.util.HashMap;
import java.util.LinkedList;
public class MyLinkedHashMap<K, V> {
private HashMap<K, Node<K, V>> map = new HashMap<>();
public MyLinkedHashMap() {
// dummy Node
head = new Node<>(null, null);
tail = new Node<>(null, null);
head.next = tail;
tail.prev = head;
}
public V get(K key) {
Node<K, V> x = map.get(key);
if (x != null) {
return x.val;
}
return null;
}
public V put(K key, V val) {
// 若为新插入的节点,则同时插入链表和 map
if (!map.containsKey(key)) {
// 插入新的 Node
Node<K, V> x = new Node<>(key, val);
addLastNode(x);
map.put(key, x);
return null;
}
// 若存在,则替换之前的 val
Node<K, V> x = map.get(key);
V oldVal = x.val;
x.val = val;
return oldVal;
}
public V remove(K key) {
// 若 key 本不存在,直接返回
if (!map.containsKey(key)) {
return null;
}
// 若 key 存在,则需要在链表中也删除
Node<K,V> x = map.remove(key);
removeNode(x);
return x.val;
}
public boolean containsKey(K key) {
return map.containsKey(key);
}
public Iterable<K> keys() {
LinkedList<K> keyList = new LinkedList<>();
for (Node<K, V> p = head.next; p != tail; p = p.next) {
keyList.addLast(p.key);
}
return keyList;
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
private static class Node<K, V> {
K key;
V val;
Node<K, V> next, prev;
Node(K key, V val) {
this.key = key;
this.val = val;
}
}
private final Node<K, V> head, tail;
private void addLastNode(Node<K, V> x) {
Node<K, V> temp = tail.prev;
// temp <-> tail
x.next = tail;
x.prev = temp;
temp.next = x;
tail.prev = x;
}
private void removeNode(Node<K, V> x) {
Node<K, V> prev = x.prev;
Node<K, V> next = x.next;
// prev <-> x <-> next
prev.next = next;
next.prev = prev;
x.next = x.prev = null;
}
}
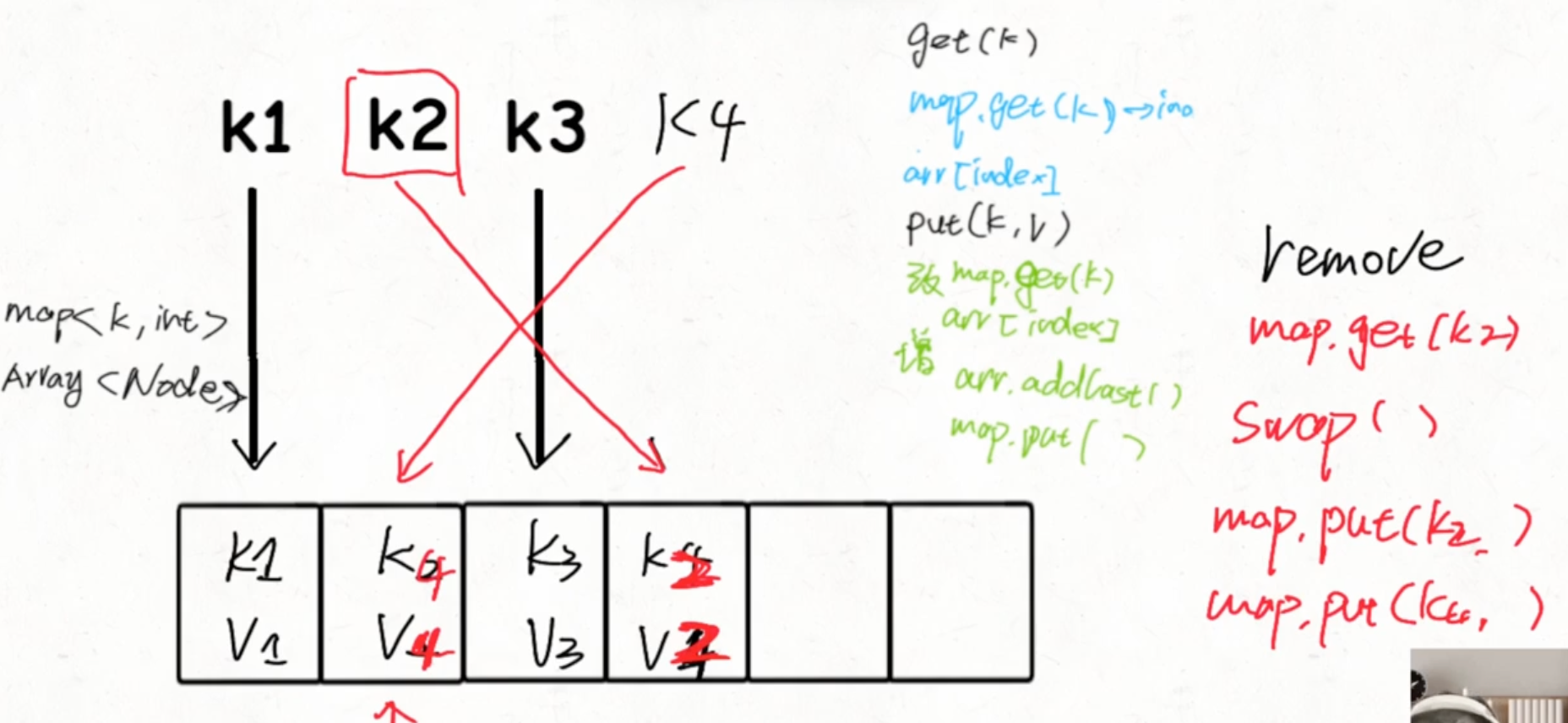
ArrayHashMap
特性:可在 O(1) 时间内等概率随机返回一个 key
标准 HashMap 中的 table 数组是无法提供一个随机 pop 方法的,因为其中存储元素并非都是有效(如线性探查法不是顺序存储元素的)
原理 与 ArrayList 结合
与 LinkedHashMap 类似,底层 HashMap 保存 key 到数组索引的映射
这里删除元素比较有意思,由于数组中间删除元素一定会设计元素的搬移,但是删除数组尾部元素就不需要,因此我们可以先将待删除元素和尾部元素作交换,然后在把它删掉,最后重新更新 HashMap 的索引映射即可
ArrayHashMap 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101import java.util.Random;
public class MyArrayHashMap<K, V> {
private static class Node<K, V> {
K key;
V val;
Node(K key, V val) {
this.key = key;
this.val = val;
}
}
// key => index
private final HashMap<K, Integer> map = new HashMap<>();
// Node List
private final MyArrayList<Node<K, V>> arr = new MyArrayList<>();
private final Random r = new Random();
public MyArrayHashMap() {
}
public V get(K key) {
if (!map.containsKey(key)) {
return null;
}
// 获取 key 在 map 中的索引
int i = map.get(key);
return arr.get(i).val;
}
public V put(K key, V val) {
if (containsKey(key)) {
// 修改
int i = map.get(key);
Node<K, V> x = arr.get(i);
V oldVal = x.val;
x.val = val;
return oldVal;
}
// 新增
Node<K, V> x = new Node<>(key, val);
arr.addLast(x);
map.put(key, arr.size() - 1);
return null;
}
public V remove(K key) {
if (!map.containsKey(key)) {
return null;
}
int index = map.get(key);
Node<K, V> x = arr.get(i);
// 1. 最后一个元素 e 和第 i 个元素 x 换位置
Node<K, V> e = arr.get(arr.size() - 1);
arr.set(index, e);
arr.set(arr.size() - 1, x);
// 2. 修改 map 中 e.key 对应的索引
map.put(e.key, index);
// 3. 在数组中 removeLast
arr.removeLast();
// 4. 在 map 中 remove x.key
map.remove(x.key);
return x.val;
}
// 随机弹出一个键
public K pop() {
int n = arr.size();
// [0, n-1]
int randomIndex = r.nextInt(n);
return arr.get(randomIndex).key;
}
public boolean containsKey(K key) {
return map.containsKey(key);
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public static void main(String[] args) {
MyArrayHashMap<Integer, Integer> map = new MyArrayHashMap<>();
map.put(2, 1);
map.put(2, 2);
System.out.println(map.get(2));
}
}
LRU 缓存淘汰算法
其解决的问题是由于缓存容量有限,当有新内容到来时需要选择清理掉一部分内容为新的内容腾地方,LRU 采取的策略是最近使用的原则,即最久未使用的就是待清除的。
条件分析
要想满足该
cache数据结构的条件,使得put和get均在O(1)的时间复杂度下运行,则有如下条件:1、显然
cache中的元素必须有时序,以区分最近使用的和久未使用的数据,当容量满了之后要删除最久未使用的那个元素腾位置。2、我们要在
cache中快速找某个key是否已存在并得到对应的val;3、每次访问
cache中的某个key,需要将这个元素变为最近使用的,也就是说cache要支持在任意位置快速插入和删除元素。联想之前学的可知 LinkedHashMap 满足此条件,结合 HashMap 的快速查找属性以及 LinkedList 的快速插入和删除元素的特性
代码实现
这里对于 put 方法流程如下:
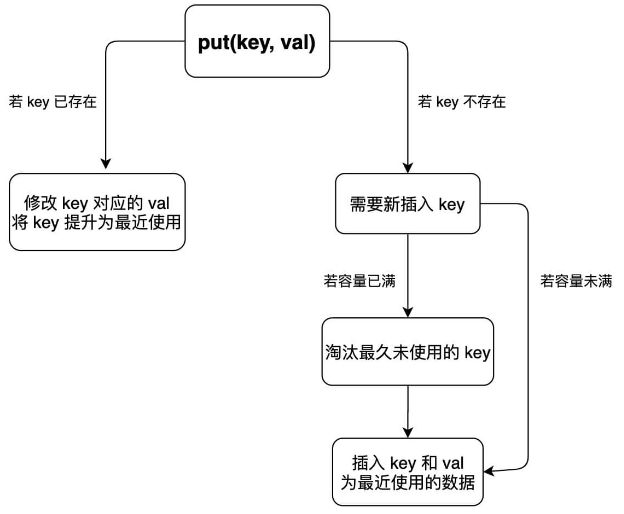
Java Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125package top.john.base;
import java.util.HashMap;
public class LRU {
// key -> Node(key, val)
private HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
private DoubleList cache;
private int cap;
public LRU(int cap) {
this.cap = cap;
map = new HashMap<>();
cache = new DoubleList();
}
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
// 变成最近使用的
makeRecently(key);
return map.get(key).val;
}
public void put(int key, int val) {
if (map.containsKey(key)) {
deleteKey(key);
addRecently(key, val);
return;
}
if (cap == cache.size()) {
removeRecently();
}
addRecently(key, val);
}
// 将某个 key 变为最近使用的
private void makeRecently(int key) {
Node x = map.get(key);
cache.remove(x);
cache.addLast(x);
}
// 添加最近使用的元素
private void addRecently(int key, int val) {
Node x = new Node(key, val);
cache.addLast(x);
map.put(key, x);
}
// 删除某一个 key
private void deleteKey(int key) {
Node x = map.get(key);
cache.remove(x);
map.remove(key);
}
// 删除最久未使用的元素
private void removeRecently() {
Node del = cache.removeFirst();
int delKey = del.key;
map.remove(delKey);
}
}
class DoubleList {
// dummy
private Node head, tail;
// nums
private int size;
public DoubleList() {
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
size = 0;
}
// addLast O(1)
public void addLast(Node x) {
x.prev = tail.prev;
x.next = tail;
tail.prev.next = x;
tail.prev = x;
size++;
}
public void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
size--;
}
public Node removeFirst() {
if (head.next == tail) {
return null;
}
Node first = head.next;
remove(first);
return first;
}
public int size() {
return size;
}
}
class Node {
public int key, val;
public Node next, prev;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}底层直接用 LinkedHashMap 的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42class LRUCache {
private int cap;
private LinkedHashMap<Integer, Integer> cache;
public LRUCache(int capacity) {
cache = new LinkedHashMap<>();
cap = capacity;
}
public int get(int key) {
if (!cache.containsKey(key)) {
return -1;
}
int val = cache.get(key);
makeRecently(key);
return val;
}
public void put(int key, int value) {
if (cache.containsKey(key)) {
// 直接跳整顺序并修改即可
makeRecently(key);
cache.put(key, value);
return;
}
if (cache.size() >= cap) {
// 找到迭代器的第一个结点,即最久未使用的元素
int del = cache.keySet().iterator().next();
cache.remove(del);
}
cache.put(key, value);
}
// 用于调整元素在链表中的顺序
private void makeRecently(int key) {
int val = cache.get(key);
cache.remove(key);
cache.put(key, val);
}
}
LFU 缓存淘汰算法
LFU 按照访问频率进行淘汰元素,并且如果出现频率相同多个元素,则优先淘汰最旧的数据。
leetcode-460 LFU 缓存 hard
条件分析
关键需满足的条件如下:
1、使用一个
HashMap存储key到val的映射,就可以快速计算get(key)。
2、使用一个HashMap存储key到freq的映射,就可以快速操作key对应的freq。
3.1、首先,肯定是需要freq到key的映射,用来找到freq最小的key。3.2、将
freq最小的key删除,那你就得快速得到当前所有key最小的freq是多少。想要时间复杂度 O(1) 的话,肯定不能遍历一遍去找,那就用一个变量minFreq来记录当前最小的freq吧。3.3、可能有多个
key拥有相同的freq,所以freq对key是一对多的关系,即一个freq对应一个key的列表。3.4、希望
freq对应的key的列表是存在时序的,便于快速查找并删除最旧的key。3.5、希望能够快速删除
key列表中的任何一个key,因为如果频次为freq的某个key被访问,那么它的频次就会变成freq+1,就应该从freq对应的key列表中删除,加到freq+1对应的key的列表中。这里对于
freq映射到的key列表,可以利用LinkedHashSet来维护,其中的链表可以帮助我们保持时序且快速删除和添加,而哈希集合可以快速查找元素代码实现
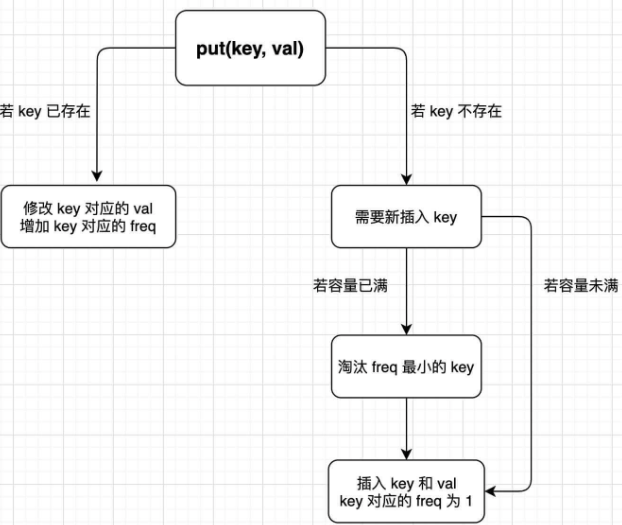
Java code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96package top.john.base;
import java.util.HashMap;
import java.util.LinkedHashSet;
public class LFUCache {
// key => val
HashMap<Integer, Integer> keyToVal;
// key => freq
HashMap<Integer, Integer> keyToFreq;
// freq => keyList
HashMap<Integer, LinkedHashSet<Integer>> freqToKeys;
// 记录最小的频次
int minFreq;
// 记录 LFU 缓存的最大容量
int cap;
public LFUCache(int capacity) {
keyToVal = new HashMap<>();
keyToFreq = new HashMap<>();
freqToKeys = new HashMap<>();
this.cap = capacity;
this.minFreq = 0;
}
public int get(int key) {
// TODO
if (!keyToFreq.containsKey(key)) {
return -1;
}
int val = keyToVal.get(key);
increaseFreq(key);
return val;
}
public void put(int key, int val) {
// TODO
if (keyToVal.containsKey(key)) {
keyToVal.put(key, val);
increaseFreq(key);
return;
}
if (cap <= keyToVal.size()) {
removeMinFreqKey();
}
keyToVal.put(key, val);
keyToFreq.put(key, 1);
freqToKeys.putIfAbsent(1, new LinkedHashSet<>());
freqToKeys.get(1).add(key);
// 注意修改 minFreq
this.minFreq = 1;
}
public void increaseFreq(int key) {
// TODO
Integer freq = keyToFreq.get(key);
// 更新 KF 表
keyToFreq.put(key, freq + 1);
// 更新 FK 表
// 1.1 删除原 freq 中的 key
freqToKeys.get(freq).remove(key);
// 1.2 更新 key 到 freq + 1 中
freqToKeys.putIfAbsent(freq + 1, new LinkedHashSet<>());
freqToKeys.get(freq + 1).add(key);
// 1.3 对原 freq 的 keyList 进行维护
if (freqToKeys.get(freq).isEmpty()) {
freqToKeys.remove(freq);
if (this.minFreq == freq) {
this.minFreq++;
}
}
}
public void removeMinFreqKey() {
// TODO
LinkedHashSet<Integer> keys = freqToKeys.get(this.minFreq);
Integer delKey = keys.iterator().next();
// 从 keysList 中删除
keys.remove(delKey);
// 如果 keysList 为空了,则没有对应这个 freq 的元素了
if (keys.isEmpty()) {
freqToKeys.remove(this.minFreq);
// 不需要更新 minFreq 的值,这个 API 只会在 put 新的 key 时会调用
// 出现新的 key 必然会更新 minFreq
}
// 从 KV 表中删除
keyToVal.remove(delKey);
// 从 KF 表中删除
keyToFreq.remove(delKey);
}
}
最大栈
leetcode-895 最大频率栈 hard
类似前面的题目,我们仍要维护一个频率到元素的映射,并记录频率最大值
这里有个细节就是当 push 一个已存在频率映射中的元素时,只修改 valToFreq 原有映射,并添加 freqToVals 一个新的映射集即可,而之前的保留。这里的区别在于即使后面 pop 元素时,其频率是会降低但不会没有,而且每次只会降低1个频率,因此之前的频率映射集仍要保留
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39class FreqStack {
// 记录 FreqStack 中元素的最大频率
int maxFreq = 0;
// 记录 FreqStack 中每个 val 对于的出现频率
HashMap<Integer, Integer> valToFreq;
HashMap<Integer, Stack<Integer>> freqToVals;
public FreqStack() {
valToFreq = new HashMap<>();
freqToVals = new HashMap<>();
}
public void push(int val) {
int freq = valToFreq.getOrDefault(val, 0) + 1;
valToFreq.put(val, freq);
freqToVals.putIfAbsent(freq, new Stack<>());
freqToVals.get(freq).push(val);
this.maxFreq = Math.max(this.maxFreq, freq);
}
public int pop() {
Stack<Integer> freqs = freqToVals.get(this.maxFreq);
int res = freqs.pop();
int f = valToFreq.get(res) - 1;
valToFreq.put(res, f);
if (freqs.isEmpty()) {
freqToVals.remove(this.maxFreq);
this.maxFreq--;
}
return res;
}
}设计类题目
-
这里利用链表来记录蛇身的每个位置,利用哈希集合来快速判断新移动位置是否会和之前的位置发生碰撞。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103class SnakeGame {
// 记录蛇身位置,主要找蛇头和蛇尾
LinkedList<Integer> body;
// 记录蛇身位置的集合,便于快速判断
HashSet<Integer> set;
// food 出现的位置序列
LinkedList<Integer> food;
// 判断是否存活
boolean isAlive;
// 屏幕尺寸
int m, n;
public SnakeGame(int width, int height, int[][] food) {
this.m = height;
this.n = width;
this.isAlive = true;
this.body = new LinkedList<>();
this.set = new HashSet<>();
this.food = new LinkedList<>();
for (int[] p : food) {
this.food.add(encode(p[0], p[1]));
}
// 添加蛇头起始点
this.body.addLast(encode(0,0));
this.set.add(encode(0,0));
}
public int move(String direction) {
if (!isAlive) {
return -1;
}
// 拿到原蛇头的位置
int head = this.body.getFirst();
// 转换成二维坐标
int x = head / n, y = head % n;
// 新坐标
int nx = x, ny = y;
switch(direction) {
case "R":
ny++;
break;
case "D":
nx++;
break;
case "U":
nx--;
break;
case "L":
ny--;
break;
}
// 判断越界
if (nx < 0 || nx == m || ny < 0 || ny == n ) {
isAlive = false;
return -1;
}
// 编码新坐标
int code = encode(nx, ny);
// 判断吃没吃着食物
if (!food.isEmpty() && food.getFirst() == code) {
// 身长 + 1 => 尾巴不会消失
food.removeFirst();
} else {
int tail = body.removeLast();
set.remove(tail);
}
// 判断吃没吃着自己,注意是在吃饭食物后判断,因为尾部会有变化
if (set.contains(code)) {
isAlive = false;
return -1;
}
// 添加新头部
body.addFirst(code);
set.add(code);
// 分数等于身长 -1
return body.size() - 1;
}
// 将二维坐标编码成一维
private int encode(int x, int y) {
return x * n + y;
}
}
/**
* Your SnakeGame object will be instantiated and called as such:
* SnakeGame obj = new SnakeGame(width, height, food);
* int param_1 = obj.move(direction);
*/ -
想法:userId 和 关注+自己的id 映射;维护一个 LinkedList
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49class Twitter {
class Node {
int userId;
int tweetId;
public Node(int userId, int tweetId) {
this.userId = userId;
this.tweetId = tweetId;
}
}
LinkedList<Node> news;
HashMap<Integer, HashSet<Integer>> userToUsers;
public Twitter() {
this.news = new LinkedList<>();
this.userToUsers = new HashMap<>();
}
public void postTweet(int userId, int tweetId) {
Node x = new Node(userId, tweetId);
news.addFirst(x);
}
public List<Integer> getNewsFeed(int userId) {
int count = 10;
LinkedList<Integer> res = new LinkedList<>();
Iterator list = news.iterator();
while (count > 0 && list.hasNext()) {
Node x = (Node) list.next();
if (x.userId == userId || (this.userToUsers.containsKey(userId) &&
this.userToUsers.get(userId).contains(x.userId))) {
res.add(x.tweetId);
count--;
}
}
return res;
}
public void follow(int followerId, int followeeId) {
this.userToUsers.putIfAbsent(followerId, new HashSet<>());
this.userToUsers.get(followerId).add(followeeId);
}
public void unfollow(int followerId, int followeeId) {
if (this.userToUsers.containsKey(followerId)) {
this.userToUsers.get(followerId).remove(followeeId);
}
}
}作者提供的一个更加聪明的设计,结合了合并 k 个有序链表的算法思路,以及 OOP 思想
Java Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123// Tweet structure
class Tweet {
private int id;
private int time;
private Tweet next;
// 需要传入推文内容(id)和发文时间
public Tweet(int id, int time) {
this.id = id;
this.time = time;
this.next = null;
}
}
// User Structure
// static int timestamp = 0
class User {
private int id;
public Set<Integer> followed;
// 用户发表的推文链表头结点
public Tweet head;
public User(int userId) {
followed = new HashSet<>();
this.id = userId;
this.head = null;
// 关注一下自己
follow(id);
}
public void follow(int userId) {
followed.add(userId);
}
public void unfollow(int userId) {
// 不可以取关自己
if (userId != this.id)
followed.remove(userId);
}
public void post(int tweetId) {
Tweet twt = new Tweet(tweetId, timestamp);
timestamp++;
// 将新建的推文插入链表头
// 越靠前的推文 time 值越大
twt.next = head;
head = twt;
}
}
class Twitter {
private static int timestamp = 0;
private static class Tweet {...}
private static class User {...}
// 我们需要一个映射将 userId 和 User 对象对应起来
private HashMap<Integer, User> userMap = new HashMap<>();
/** user 发表一条 tweet 动态 */
public void postTweet(int userId, int tweetId) {
// 若 userId 不存在,则新建
if (!userMap.containsKey(userId))
userMap.put(userId, new User(userId));
User u = userMap.get(userId);
u.post(tweetId);
}
/** follower 关注 followee */
public void follow(int followerId, int followeeId) {
// 若 follower 不存在,则新建
if(!userMap.containsKey(followerId)){
User u = new User(followerId);
userMap.put(followerId, u);
}
// 若 followee 不存在,则新建
if(!userMap.containsKey(followeeId)){
User u = new User(followeeId);
userMap.put(followeeId, u);
}
userMap.get(followerId).follow(followeeId);
}
/** follower 取关 followee,如果 Id 不存在则什么都不做 */
public void unfollow(int followerId, int followeeId) {
if (userMap.containsKey(followerId)) {
User flwer = userMap.get(followerId);
flwer.unfollow(followeeId);
}
}
/** 返回该 user 关注的人(包括他自己)最近的动态 id,
最多 10 条,而且这些动态必须按从新到旧的时间线顺序排列。*/
public List<Integer> getNewsFeed(int userId) {
// 合并 k 个有序链表的思路,利用优先级队列
List<Integer> res = new ArrayList<>();
if (!userMap.containsKey(userId)) return res;
// 关注列表的用户 Id
Set<Integer> users = userMap.get(userId).followed;
// 自动通过 time 属性从大到小排序,容量为 users 的大小
PriorityQueue<Tweet> pq =
new PriorityQueue<>(users.size(), (a, b)->(b.time - a.time));
// 先将所有链表头节点插入优先级队列
for (int id : users) {
Tweet twt = userMap.get(id).head;
// 有的零推文发送要考虑!
if (twt == null) continue;
pq.add(twt);
}
while (!pq.isEmpty()) {
// 最多返回 10 条就够了
if (res.size() == 10) break;
// 弹出 time 值最大的(最近发表的)
Tweet twt = pq.poll();
res.add(twt.id);
// 将下一篇 Tweet 插入进行排序
if (twt.next != null)
pq.add(twt.next);
}
return res;
}
}
-
哈希集合存储已分配的号码方便快速查询;链表来存储未分配号码,先入先出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class PhoneDirectory {
HashSet<Integer> finished;
LinkedList<Integer> unfinished;
public PhoneDirectory(int maxNumbers) {
this.finished = new HashSet<>();
this.unfinished = new LinkedList<>();
for (int i = 0; i < maxNumbers; i ++) {
this.unfinished.addLast(i);
}
}
public int get() {
if (this.unfinished.isEmpty()) {
return -1;
}
int res = this.unfinished.removeFirst();
this.finished.add(res);
return res;
}
public boolean check(int number) {
return !this.finished.contains(number);
}
public void release(int number) {
if (this.finished.contains(number)) {
this.finished.remove(number);
this.unfinished.addLast(number);
}
}
} -
这里实际按照二维数组遍历的方法即可,只不过每次保留 i 和 j 的值,同时要考虑到这一行为空数组的情况(如果遇到了就直接跳过)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34class Vector2D {
private int[][] vec;
private int i, j;
public Vector2D(int[][] vec) {
this.vec = vec;
this.i = 0;
this.j = 0;
}
public int next() {
if (!hasNext()) {
return -1;
}
int res = vec[this.i][this.j];
this.j++;
return res;
}
public boolean hasNext() {
// 可能存在空数组行
while (this.i < this.vec.length && this.j == this.vec[i].length) {
this.j = 0;
this.i++;
}
if (this.i == this.vec.length) {
return false;
}
return true;
}
}因此对于顶端迭代器这道题,实际我也可以提前拿到下一个元素的值,然后作为一个成员变量时常更新即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35class PeekingIterator implements Iterator<Integer> {
private Iterator<Integer> iterator;
private Integer nextElm;
public PeekingIterator(Iterator<Integer> iterator) {
// initialize any member here.
this.iterator = iterator;
this.nextElm = this.iterator.next();
}
// Returns the next element in the iteration without advancing the iterator.
public Integer peek() {
return this.nextElm;
}
// hasNext() and next() should behave the same as in the Iterator interface.
// Override them if needed.
@Override
public Integer next() {
int res = this.nextElm;
if (this.iterator.hasNext()) {
this.nextElm = this.iterator.next();
} else {
this.nextElm = null;
}
return res;
}
@Override
public boolean hasNext() {
return !(nextElm == null);
}
}
-